




作者介绍:简历上没有一个精通的运维工程师。请点击上方的蓝色《运维小路》关注我,下面的思维导图也是预计更新的内容和当前进度(不定时更新)。
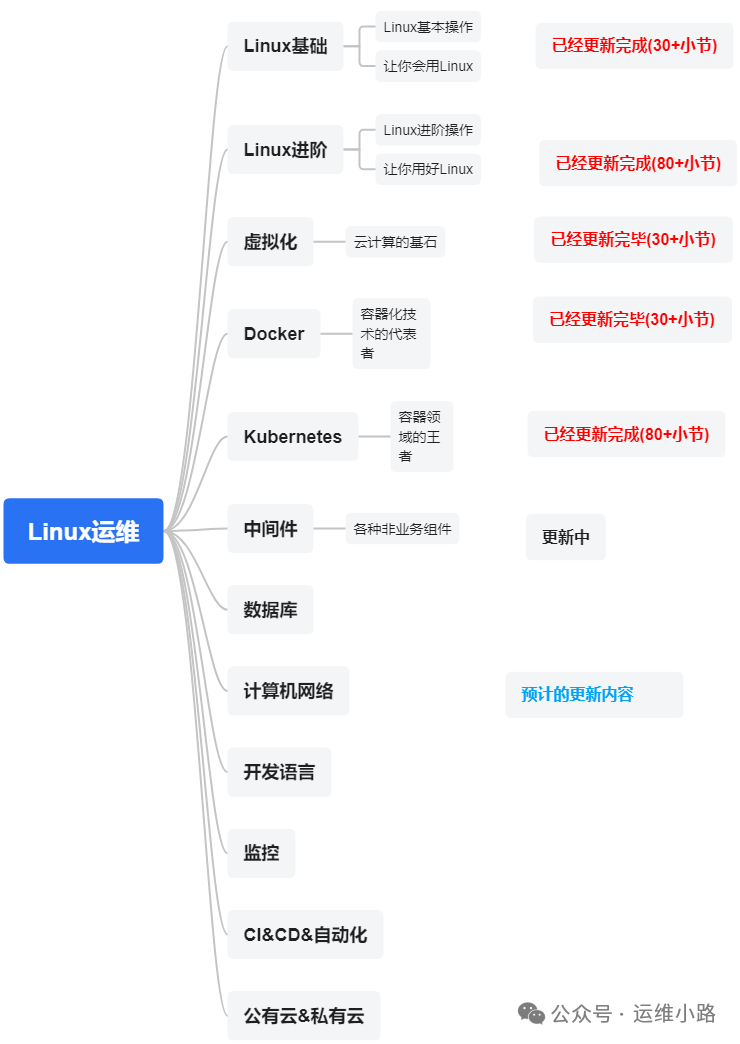
中间件,我给它的定义就是为了实现某系业务功能依赖的软件,包括如下部分:
Web服务器
代理服务器
ZooKeeper
Kafka
RabbitMQ
Hadoop HDFS(本章节)
1. 系统管理命令
1.1 服务状态管理
# 启动/停止 HDFS 服务
start-dfs.sh # 启动集群
stop-dfs.sh # 停止集群
# 单独启停组件
hadoop-daemon.sh start|stop namenode # NameNode
hadoop-daemon.sh start|stop datanode # DataNode
hadoop-daemon.sh start|stop journalnode # JournalNode
1.2 安全模式操作
#只读不写
hdfs dfsadmin -safemode get # 查看安全模式状态
hdfs dfsadmin -safemode enter # 进入安全模式
hdfs dfsadmin -safemode leave # 退出安全模式
2. 存储空间管理
2.1 空间监控
hdfs dfsadmin -report # 查看集群存储报告
hdfs dfs -df -h / # 查看文件系统空间使用
hdfs dfs -du -h /path # 查看目录大小
2.2 配额管理
hdfs dfsadmin -setQuota 1000 /dir # 设置目录文件数配额
hdfs dfsadmin -clrQuota /dir # 清除配额
hdfs dfs -count -q /dir # 查看配额使用情况
3. 数据管理命令
3.1 文件操作
hdfs dfs -ls /path # 列出目录
hdfs dfs -mkdir -p /path # 创建目录
hdfs dfs -put local /hdfs # 上传文件
hdfs dfs -get /hdfs local # 下载文件
hdfs dfs -rm -r /path # 递归删除
hdfs dfs -cp /src /dest # 复制文件
hdfs dfs -mv /src /dest # 移动文件
3.2 数据平衡
#触发数据迁移的磁盘空间使用率差异阈值
hdfs balancer # 启动数据平衡
hdfs balancer -threshold 10 # 设置平衡阈值(10%)
4. 块管理命令
4.1 块操作
hdfs fsck / -files -blocks # 检查块健康状况
hdfs dfsadmin -metasave filename # 保存块元数据到文件
hdfs debug recoverLease -path /file -retries 3 # 恢复租约
4.2 副本管理
hdfs dfs -setrep -w 2 /file # 修改副本数(同步等待)
hdfs dfsadmin -fetchImage fsimage_backup # 备份fsimage
5. 高可用管理
5.1 NameNode HA
hdfs haadmin -getServiceState nn1 # 查看NN状态
hdfs haadmin -transitionToActive --forcemanual nn1 # 手动切换主备
5.2 JournalNode
hdfs dfs -ls journalnode://cluster1/ # 查看编辑日志
6. 安全相关命令
6.1 Kerberos 管理
klist # 查看票据
kinit -kt keytab user@REALM # 使用keytab认证
hdfs dfs -Ddfs.namenode.kerberos.principal=nn/_HOST@REALM -ls / # 指定principal
6.2 ACL 管理
#突破用户,组,其他
hdfs dfs -getfacl /path # 查看ACL
hdfs dfs -setfacl -m user:alice:rwx /path # 设置ACL
7. 运维监控命令
7.1 日志检查
# 查看NameNode日志
tail -f /var/log/hadoop-hdfs/hadoop-hdfs-namenode-*.log
# 查看DataNode日志
tail -f /var/log/hadoop-hdfs/hadoop-hdfs-datanode-*.log
7.2 JMX 监控
# 获取NameNode JMX指标
curl http://namenode:9870/jmx?qry=Hadoop:service=NameNode,name=NameNodeInfo
8. 紧急恢复命令
8.1 元数据恢复
hdfs namenode -recover # 恢复元数据
hdfs namenode -importCheckpoint # 从检查点恢复
8.2 数据节点退役
hdfs dfsadmin -refreshNodes # 刷新节点列表
echo "hostname" > /excludes # 添加退役节点
9. 实用技巧
9.1 小文件合并
hadoop archive -archiveName myhar.har -p /input /output # 创建HAR归档
9.2 跨集群操作
hadoop distcp hdfs://nn1:8020/src hdfs://nn2:8020/dest # 集群间复制
10. 命令速查表
| **类别** | **常用命令** |
|---------------|--------------------------------|
| **文件操作** | ls, put, get, rm, cp, mv |
| **空间管理** | df, du, setQuota |
| **块管理** | fsck, setrep, balancer |
| **HA管理** | haadmin, getServiceState |
| **安全相关** | kinit, getfacl, setfacl |
提示:所有命令均需在配置了Hadoop环境变量的环境下执行,部分命令需要管理员权限。
在HDFS的的命令里面分两种命令:hadoop和hdfs

HDFS 文件操作(两者通用但语法不同)
|
操作 |
Hadoop 命令 |
HDFS 命令 |
|---|---|---|
|
查看文件列表 | hadoop fs -ls /path | hdfs dfs -ls /path |
|
上传文件 | hadoop fs -put local hdfs | hdfs dfs -put local hdfs |
|
下载文件 | hadoop fs -get hdfs local | hdfs dfs -get hdfs local |
|
删除文件 | hadoop fs -rm /file | hdfs dfs -rm /file |
| 底层实现 |
调用 HDFS 客户端 API |
直接使用 HDFS 原生客户端 |
✅ 功能等价性:
hadoop fs = hdfs dfs(日常文件操作可互换)
运维小路
一个不会开发的运维!一个要学开发的运维!一个学不会开发的运维!欢迎大家骚扰的运维!
关注微信公众号《运维小路》获取更多内容。

















 330
330

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









