




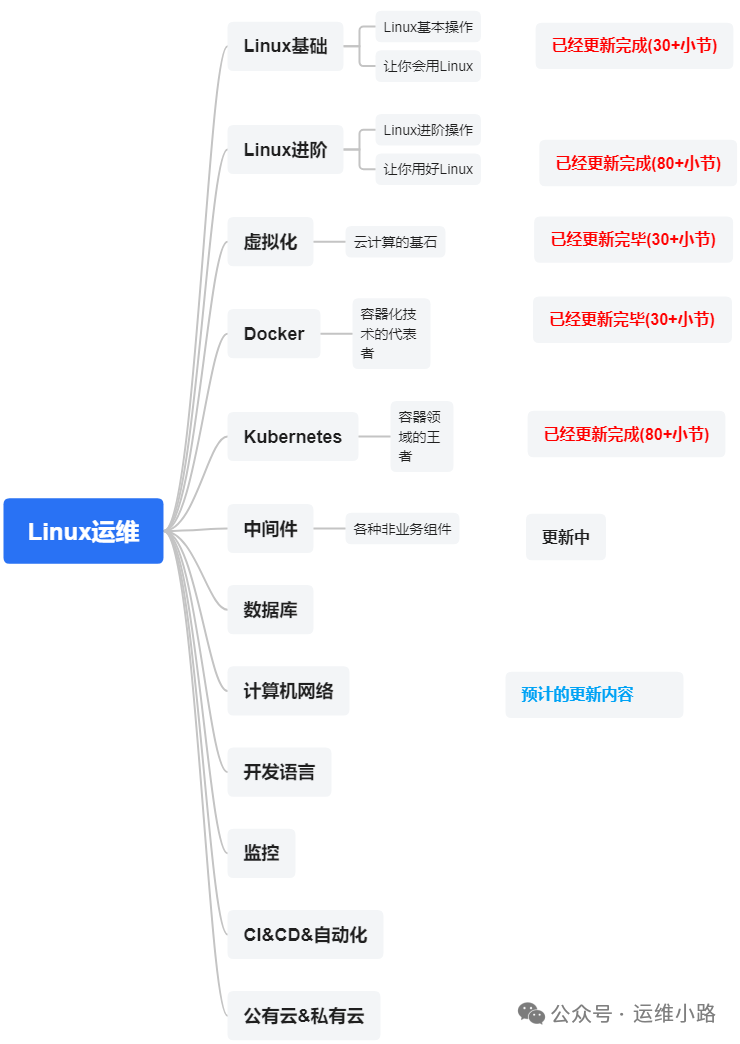
作者介绍:简历上没有一个精通的运维工程师。请点击上方的蓝色《运维小路》关注我,下面的思维导图也是预计更新的内容和当前进度(不定时更新)。
中间件,我给它的定义就是为了实现某系业务功能依赖的软件,包括如下部分:
Web服务器
代理服务器
ZooKeeper
Kafka
RabbitMQ
Hadoop HDFS(本章节)
我们前面介绍Hadoop的相关软件以及我们要讲解的HDFS,本小节就来讲讲基本部署操作。
1.JDK环境准备
yum -y install java-1.8.0-openjdk2.下载HDFS软件包
wget https://dlcdn.apache.org/hadoop/common/hadoop-2.10.2/hadoop-2.10.2.tar.gz
tar xvf hadoop-2.10.2.tar.gz
cd hadoop-2.10.23.配置文件一
hdfs全局核心配置文件,这里定义了集群临时数据目录和RPC端口。
vi ./etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value> <!-- NN 地址 -->
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/tmp/hadoop-data</value> <!-- 临时数据目录 -->
</property>
</configuration>4.配置文件二
hdfs主配置文件,hdfs 特性配置 (副本、元数据/数据目录),临时测试我这里并没有考虑数据安全。
vi ./etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value> <!-- 单机副本数必须设为1 -->
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/namenode</value> <!-- NN元数据存储路径 -->
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/datanode</value> <!-- DN数据存储路径 -->
</property>
</configuration>5.配置文件三
hdfs的JAVA进程环境变量,由于是yum安装的JDK,所以需要手工配置。
vi etc/hadoop/hadoop-env.sh
#export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.412.b08-1.el7_9.x86_64/jre6.初始化
这里主要是初始化储存结构和生成一些默认文件。
[root@localhost hadoop-2.10.2]# ./bin/hdfs namenode -format
25/07/05 00:26:50 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = localhost/127.0.0.1
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.10.2
xxxx
25/07/05 00:26:52 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost/127.0.0.17.配置免密登录本机
更详细的介绍,可以翻看我的临时文章:Linux进阶-sshd。
ssh-keygen #一直回车
ssh-copy-id localhost #把本机配置免密登录8.启动hdfs
#一键启动,如果是集群可以一次启动多个节点。
[root@localhost hadoop-2.10.2]# ./sbin/start-dfs.sh
Starting namenodes on [localhost]
localhost: starting namenode, logging to /root/hadoop-2.10.2/logs/hadoop-root-namenode-localhost.localdomain.out
localhost: starting datanode, logging to /root/hadoop-2.10.2/logs/hadoop-root-datanode-localhost.localdomain.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /root/hadoop-2.10.2/logs/hadoop-root-secondarynamenode-localhost.localdomain.out
[root@localhost hadoop-2.10.2]# 也可以使用手工启动,注意启动顺序。
# 1. NameNode
./sbin/hadoop-daemon.sh start namenode
# 2. 等待 10 秒(确保 NN 完全启动)
sleep 10
# 3. DataNode
./sbin/hadoop-daemon.sh start datanode
# 4. SecondaryNameNode
./sbin/hadoop-daemon.sh start secondarynamenode
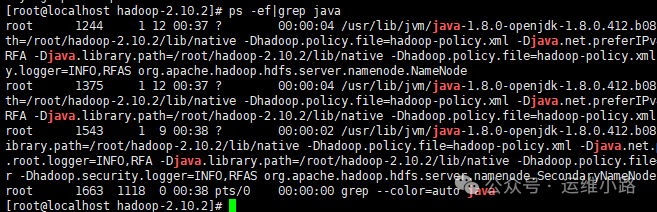
9.基本操作
创建目录,默认只有一个空的根目录:"/",这个他和ZooKeeper和Linux基本目录结构比较类似。
#先创建一个目录,默认止呕y
[root@localhost hadoop-2.10.2]# ./bin/hadoop fs -mkdir /test
[root@localhost hadoop-2.10.2]# ./bin/hadoop fs -ls /
Found 1 items
drwxr-xr-x - root supergroup 0 2025-07-07 21:33 /test上传下载文件
#上传
[root@localhost hadoop-2.10.2]# ./bin/hadoop fs -put NOTICE.txt /test/
[root@localhost hadoop-2.10.2]# ./bin/hadoop fs -ls /test
Found 1 items
-rw-r--r-- 1 root supergroup 15830 2025-07-07 21:34 /test/NOTICE.txt
#下载
[root@localhost hadoop-2.10.2]# ./bin/hadoop fs -get /test/NOTICE.txt notice.txt
[root@localhost hadoop-2.10.2]# ll notice.txt
-rw-r--r-- 1 root root 15830 Jul 7 21:35 notice.txt运维小路
一个不会开发的运维!一个要学开发的运维!一个学不会开发的运维!欢迎大家骚扰的运维!
关注微信公众号《运维小路》获取更多内容。

















 1767
1767

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









