



本文基于实际操作经验,详细介绍了HDFS的三种客户端操作方式,包含完整的部署步骤、常见问题排查和实战演示。
1. 环境准备与Hadoop部署
1.1 系统环境
-
操作系统: CentOS 7
-
Java版本: OpenJDK 1.8.0
-
Hadoop版本: 3.3.6
-
IntelliJ IDEA: 2025.2.4 (Ultimate版本)
2. HDFS进程管理
2.1 一键启停管理
启动HDFS集群
$HADOOP_HOME/sbin/start-dfs.sh执行原理:
-
启动SecondaryNameNode
-
读取core-site.xml确定NameNode位置并启动
-
读取workers文件启动所有DataNode
停止HDFS集群
$HADOOP_HOME/sbin/stop-dfs.sh验证进程状态
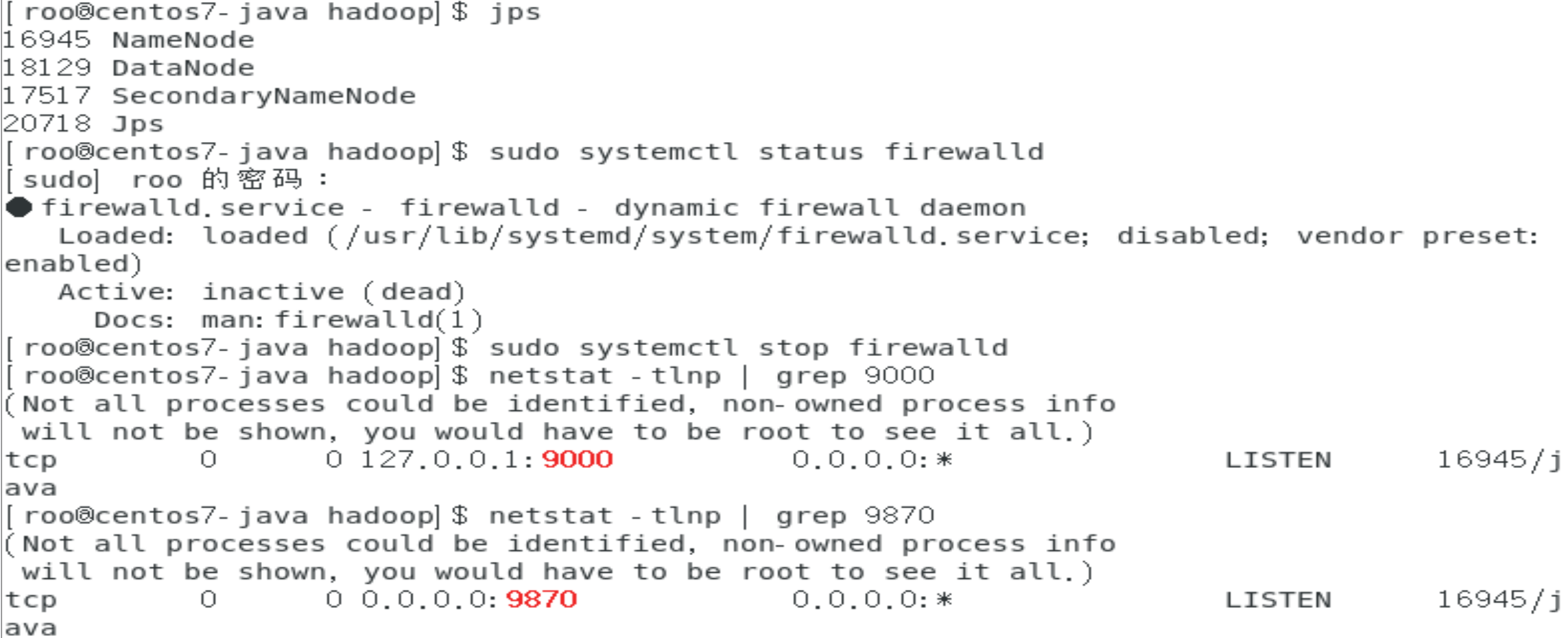
jps
2.2 单进程精细控制
使用hdfs命令
# 启动单个进程
$HADOOP_HOME/bin/hdfs --daemon start datanode
# 停止单个进程
$HADOOP_HOME/bin/hdfs --daemon stop datanode
# 查看进程状态(无输出表示正常)
$HADOOP_HOME/bin/hdfs --daemon status datanode使用传统脚本
$HADOOP_HOME/sbin/hadoop-daemon.sh start namenode
$HADOOP_HOME/sbin/hadoop-daemon.sh stop datanode2.3 常见问题排查
问题:jps看不到DataNode进程
现象:jps命令只显示NameNode和SecondaryNameNode
排查步骤:
# 检查进程是否存在
ps aux | grep DataNode
# 检查端口监听
netstat -tlnp | grep 9866
# 检查HDFS状态
hdfs dfsadmin -report解决方案:
# 停止以root运行的DataNode
sudo $HADOOP_HOME/bin/hdfs --daemon stop datanode
# 以当前用户重新启动
$HADOOP_HOME/bin/hdfs --daemon start datanode3. HDFS Shell命令行操作
3.1 基本文件操作
目录管理
# 创建目录(递归创建)
hdfs dfs -mkdir -p /hdfs_demo/input
# 查看目录
hdfs dfs -ls /
hdfs dfs -ls /hdfs_demo
文件上传下载
# 创建本地测试文件
echo "hello hdfs from YYYY_Nlx" > test1.txt
# 上传到HDFS
hdfs dfs -put test1.txt /hdfs_demo/input/
# 下载到本地
hdfs dfs -get /hdfs_demo/input/test1.txt ./
# 查看文件内容
hdfs dfs -cat /hdfs_demo/input/test1.txt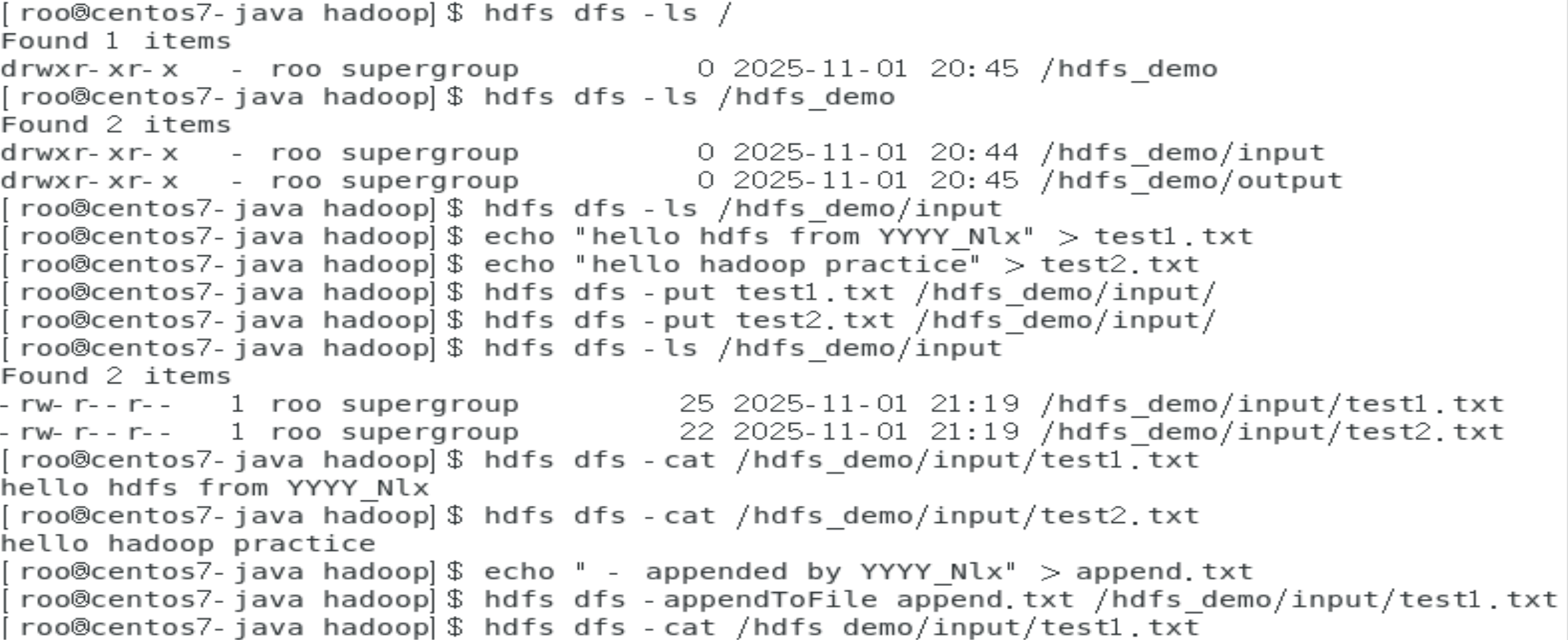
文件操作进阶
# 追加内容到文件
echo "appended content" > append.txt
hdfs dfs -appendToFile append.txt /hdfs_demo/input/test1.txt
# 复制文件
hdfs dfs -cp /hdfs_demo/input/test1.txt /hdfs_demo/input/test1_copy.txt
# 移动/重命名文件
hdfs dfs -mv /hdfs_demo/input/test2.txt /hdfs_demo/input/test2_renamed.txt
# 删除文件
hdfs dfs -rm /hdfs_demo/input/test1_copy.txt
# 递归删除目录
hdfs dfs -rm -r /hdfs_demo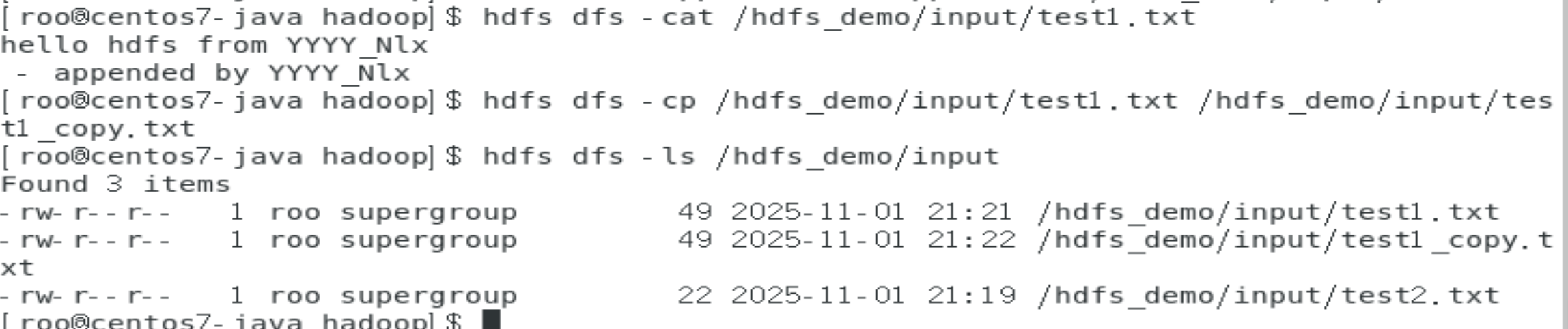

3.2 命令体系说明
Hadoop提供两套命令体系,用法完全一致:
-
hadoop命令:老版本用法,
hadoop fs [generic options] -
hdfs命令:新版本用法,
hdfs dfs [generic options]
4. Web界面操作
4.1 访问Web界面
确定访问地址
# 查看本机IP
hostname -I
# 输出: 192.168.139.150
# 检查Web端口
netstat -tlnp | grep 9870

浏览器访问
http://192.168.139.150:9870 或 http://localhost:9870
4.2 Web界面功能
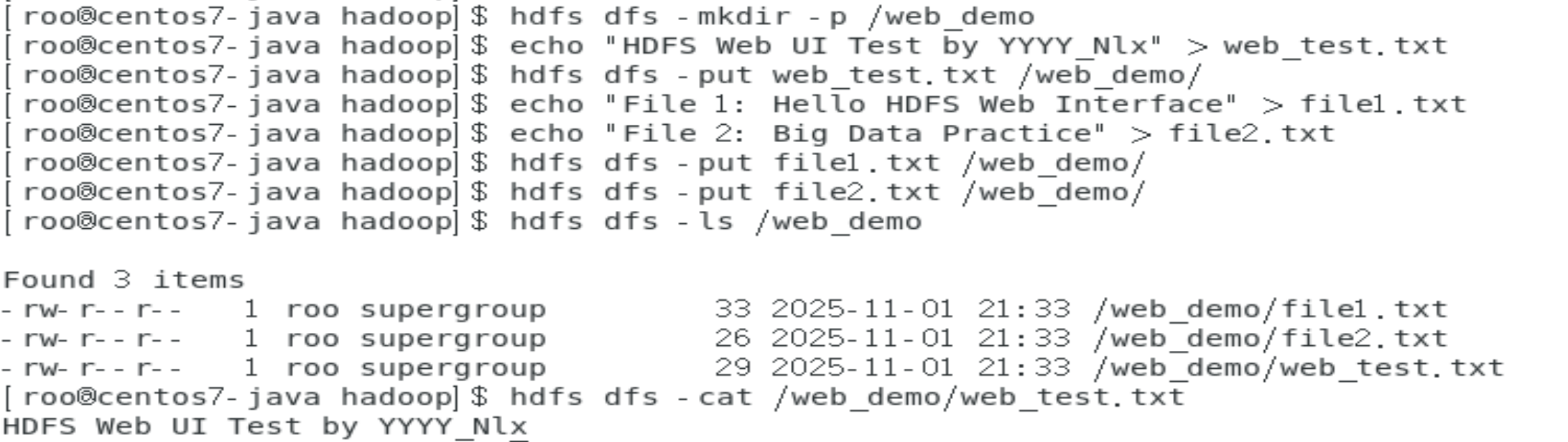
集群概览
-
查看集群状态和版本信息
-
监控存储使用情况
-
查看活跃节点状态
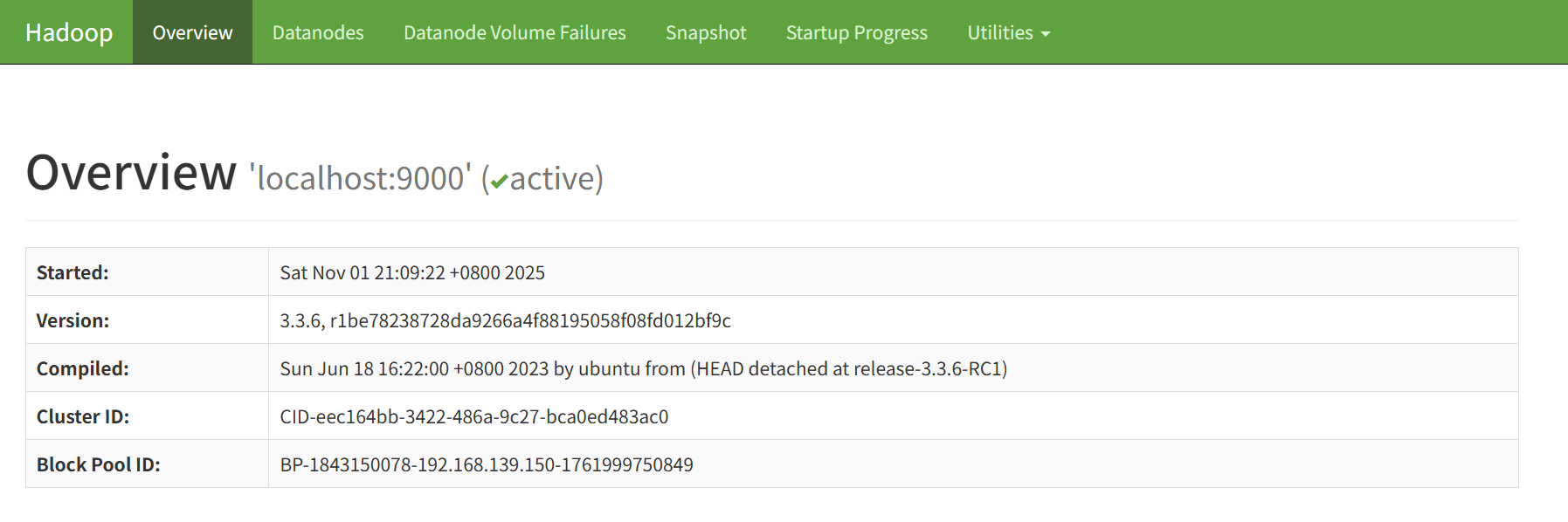
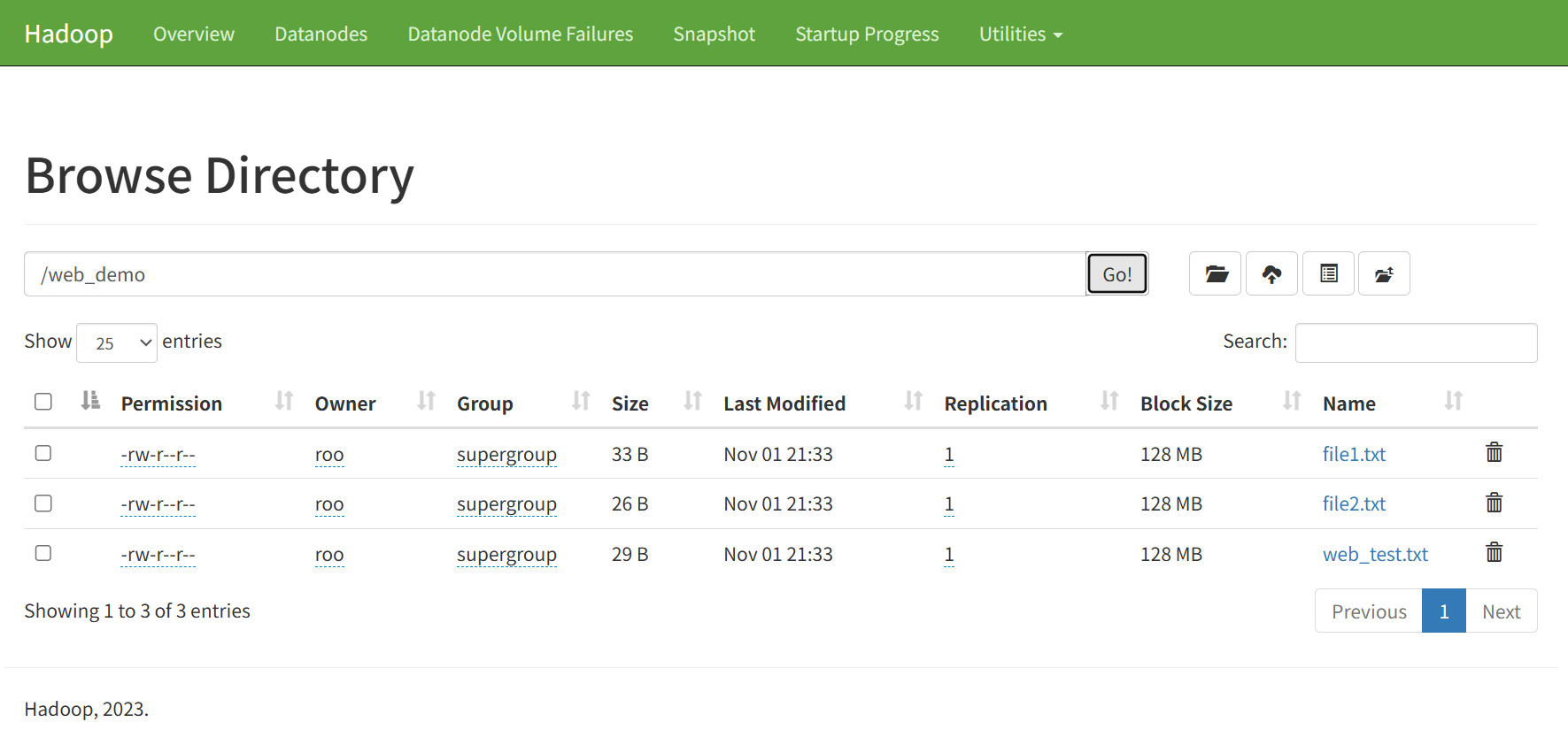
文件系统浏览
-
点击 Utilities → Browse the file system
-
导航到目标目录
-
查看文件详细信息(权限、大小、修改时间等)
权限说明
-
Web界面默认以匿名用户(dr.who)身份访问
-
大多数操作为只读权限
-
实际文件所有者为创建文件的用户(如YYYY_Nlx)
4.3 准备测试数据
# 创建专门用于Web界面查看的测试数据
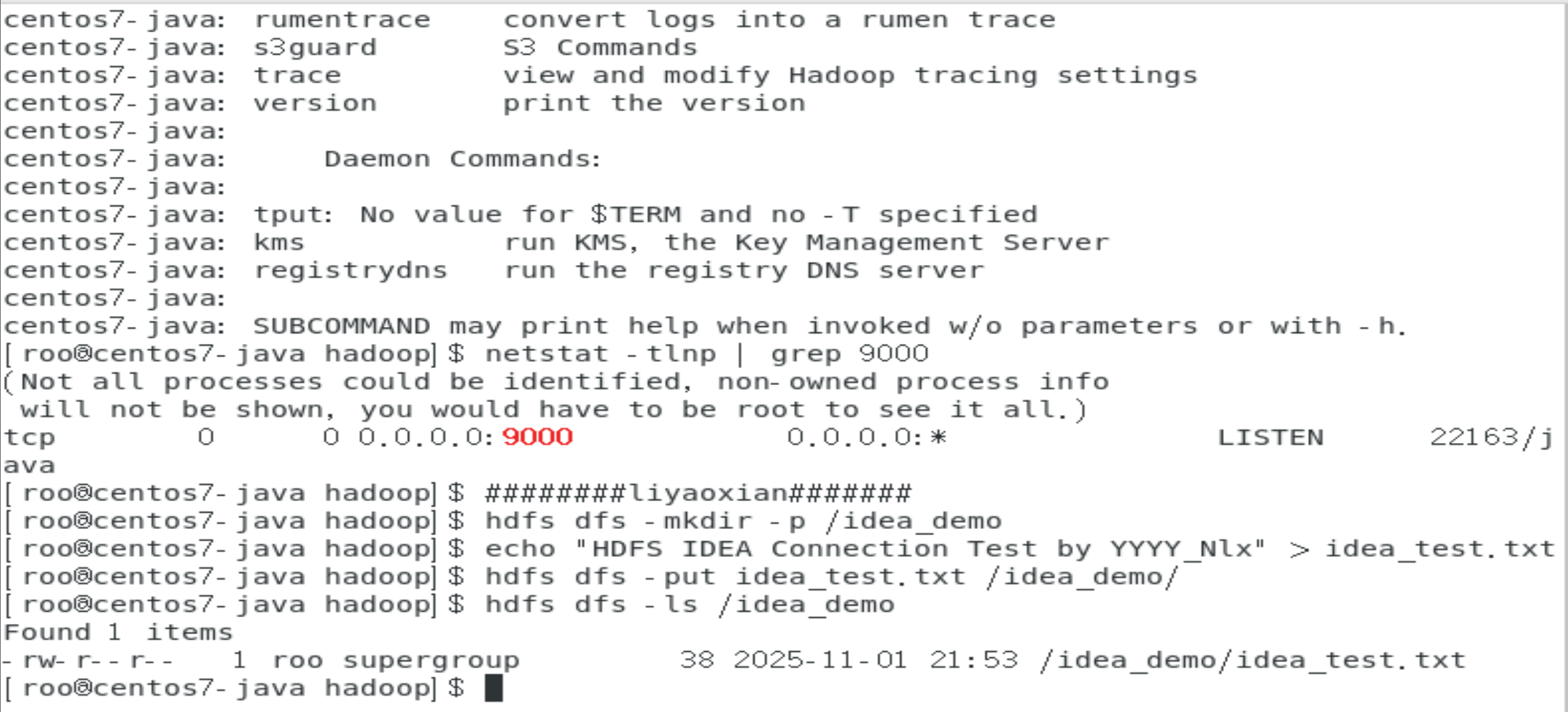
hdfs dfs -mkdir -p /web_demo
echo "HDFS Web UI Test by YYYY_Nlx" > web_test.txt
hdfs dfs -put web_test.txt /web_demo/5. Java API操作
5.1
网络架构
Windows IDEA ←→ CentOS虚拟机(Hadoop服务)
↓ ↓
Big Data Tools HDFS:9000
5.2Big Data Tools插件安装
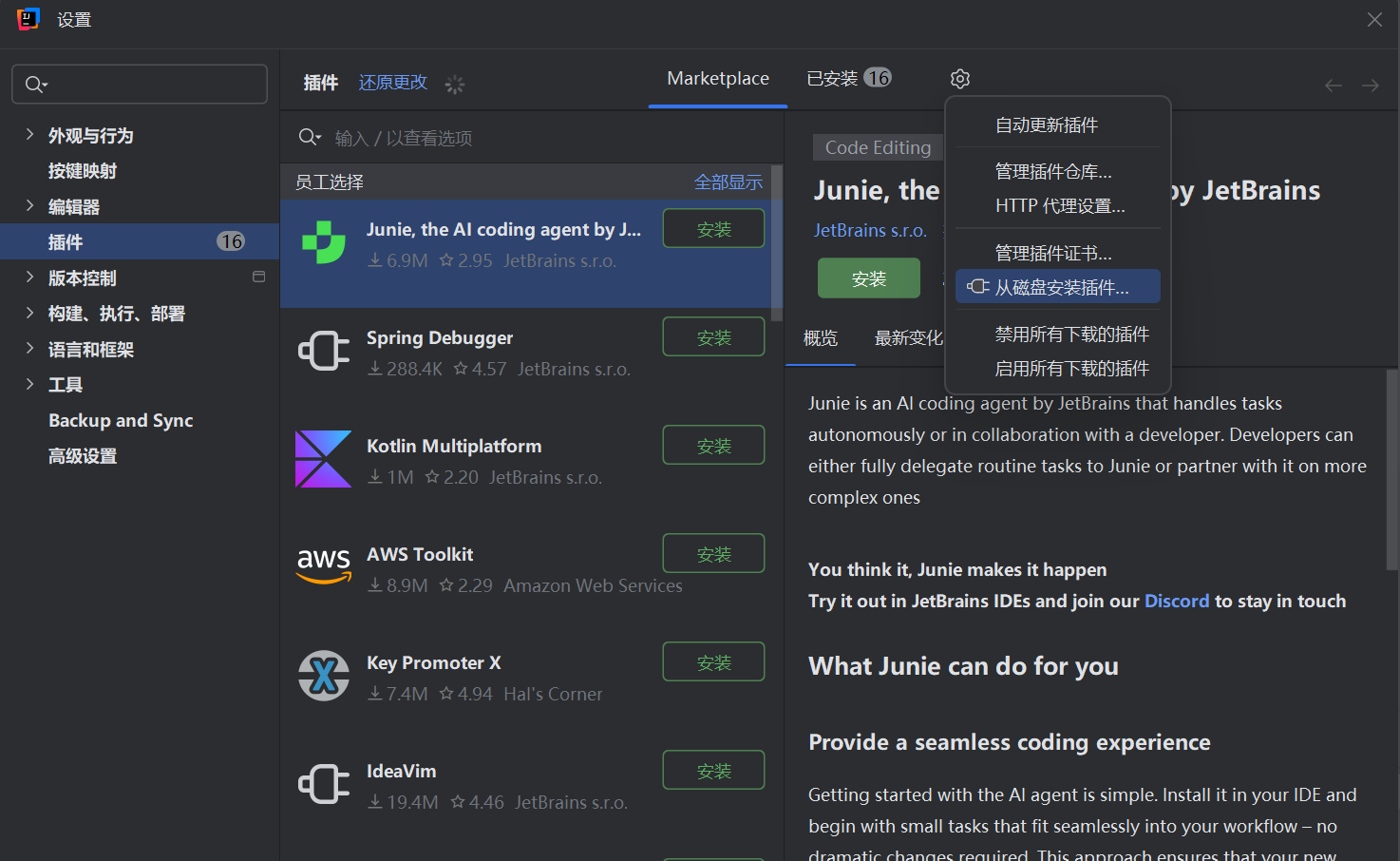
安装步骤
-
打开插件市场
-
File → Settings → Plugins
-
搜索 "Big Data Tools"
选择正确版本
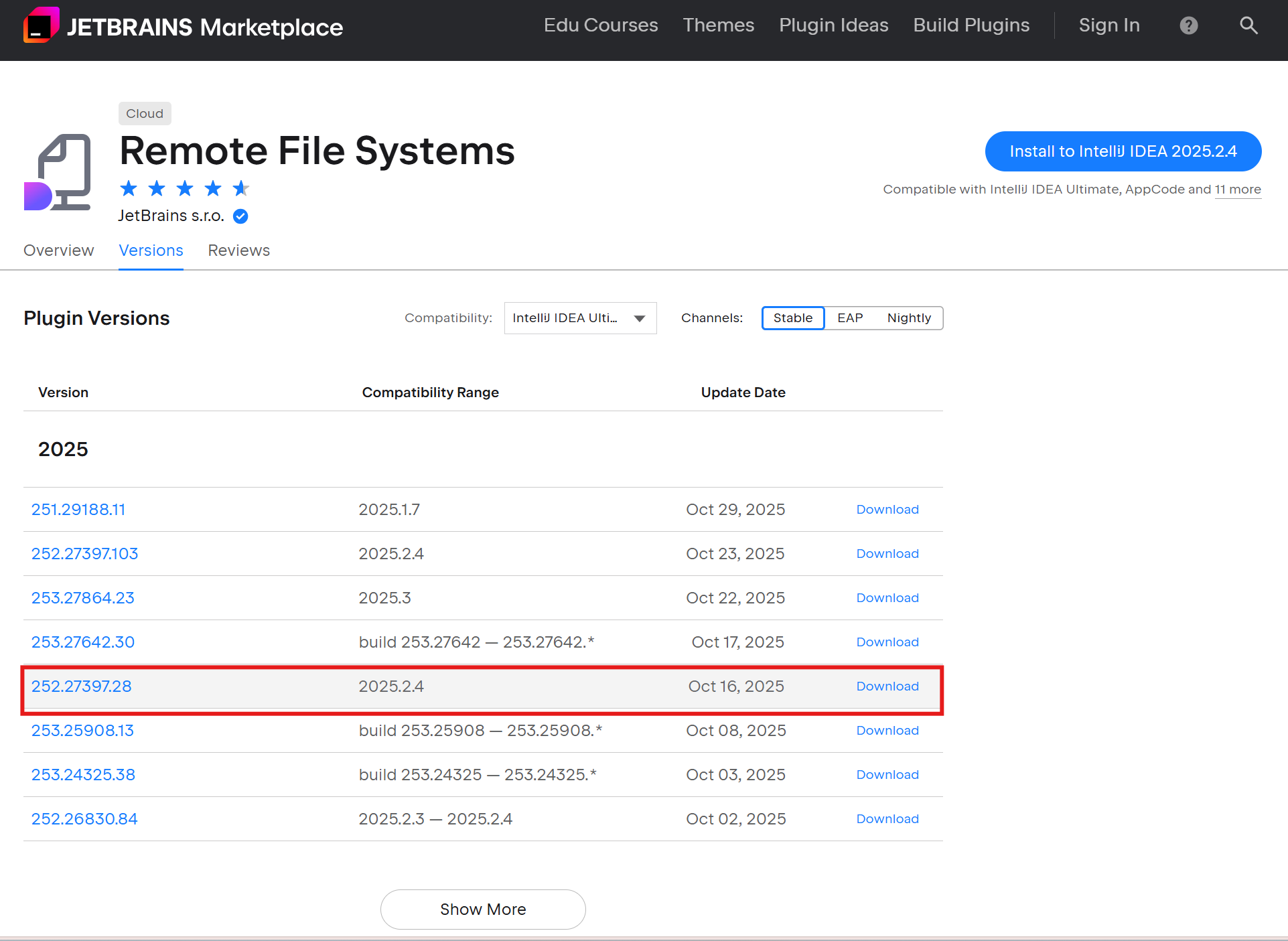
# 重要!确保插件版本与IDE兼容 # 我的IDE版本:IU-252.27397.103 # 对应插件版本:252.23892.360 -
-
解决依赖问题
-
安装主插件时会自动安装依赖组件
-
如遇依赖缺失,手动安装
Big Data Tools Core
-
常见安装问题解决
问题1: 插件版本不兼容
错误:插件版本需要253.27864,但当前IDE版本是252.27397.103
解决方案: 下载与IDE版本匹配的插件版本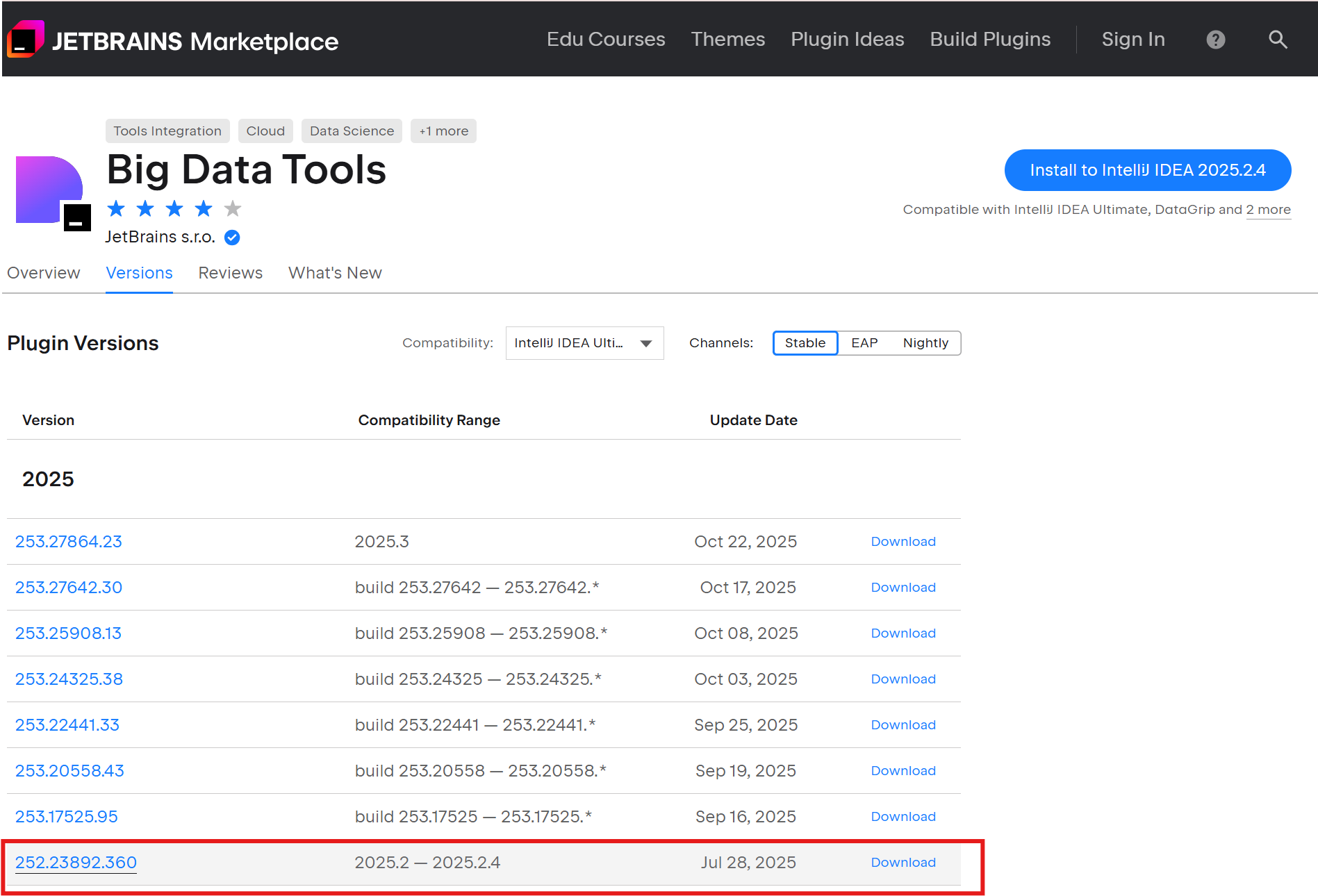
问题2: 依赖组件缺失
需要安装插件 'com.intellij.bigdatatools.core'
解决方案: 单独安装Big Data Tools Core组件
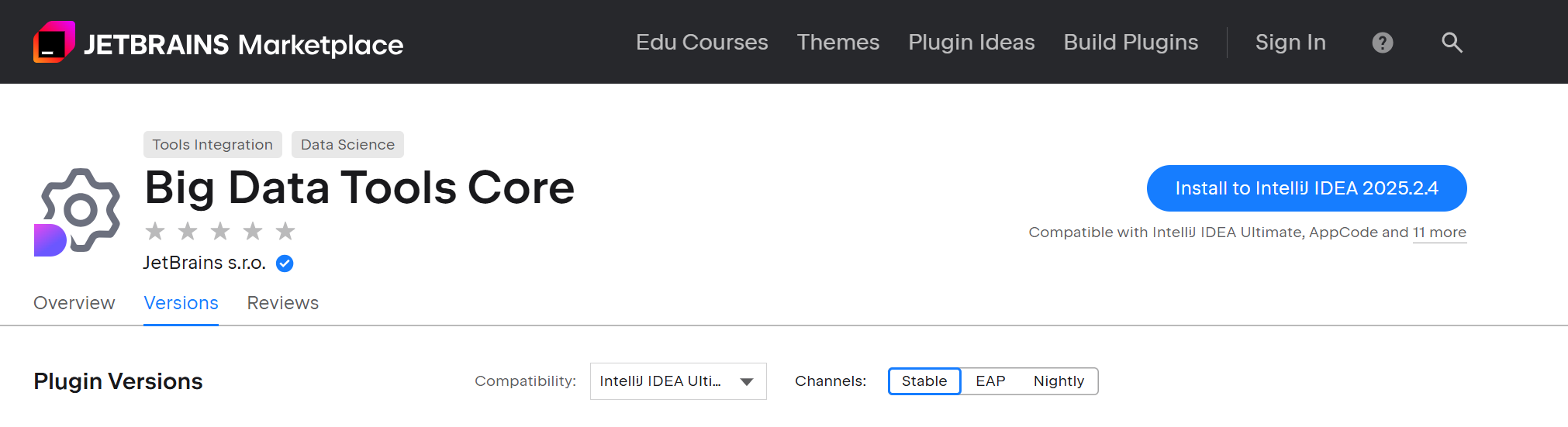
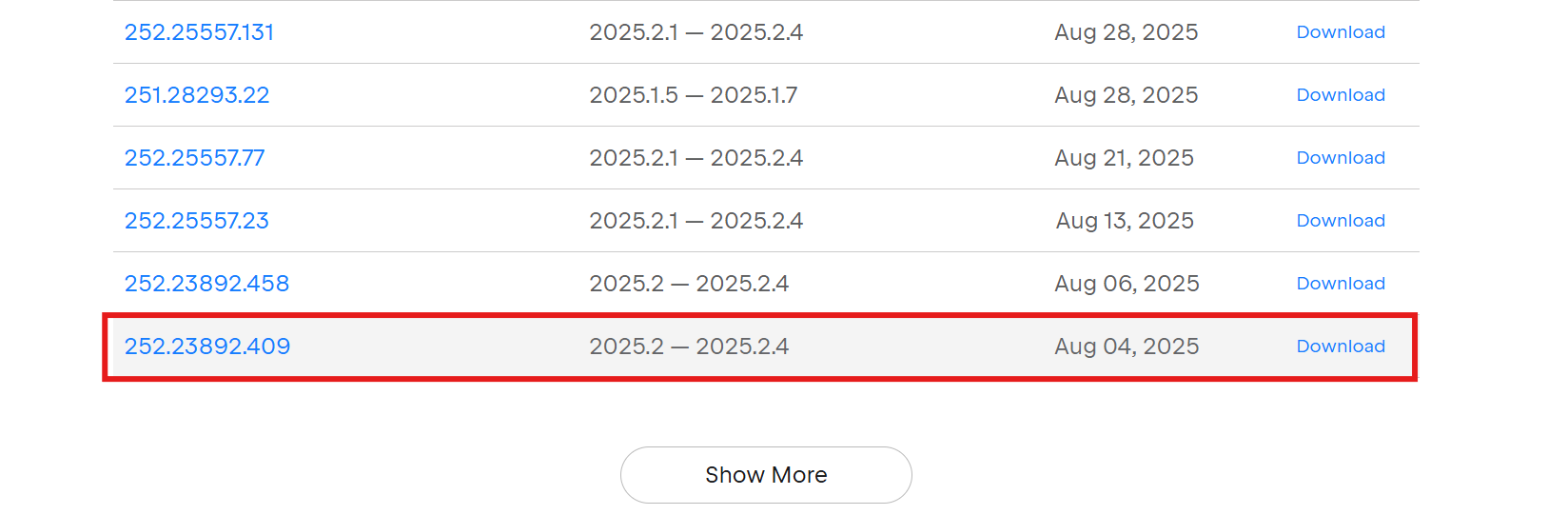
问题3: 网络下载失败
Cannot download: 连接被中止
解决方案:
-
使用手动下载安装
-
配置代理
5.3虚拟机Hadoop配置
# 1. 设置环境变量
echo 'export HADOOP_HOME=/usr/local/hadoop' >> ~/.bashrc
echo 'export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk' >> ~/.bashrc
echo 'export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin' >> ~/.bashrc
source ~/.bashrc
# 2. 配置core-site.xml
cd $HADOOP_HOME/etc/hadoop
sudo cat > core-site.xml << 'EOF'
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://0.0.0.0:9000</value>
</property>
</configuration>
EOF
# 3. 配置hdfs-site.xml
sudo cat > hdfs-site.xml << 'EOF'
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
EOF启动Hadoop服务
# 格式化HDFS(首次使用)
hdfs namenode -format
# 启动HDFS服务
start-dfs.sh
# 验证服务状态
jps
5.4 Windows环境配置
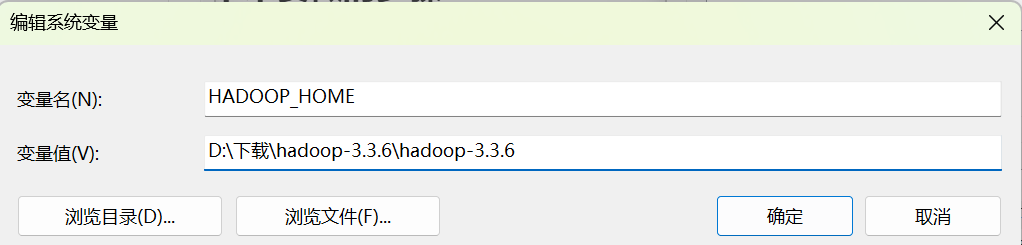
设置系统环境变量:
-
HADOOP_HOME:D:\hadoop-3.3.6 -
在Path中添加:
%HADOOP_HOME%\bin


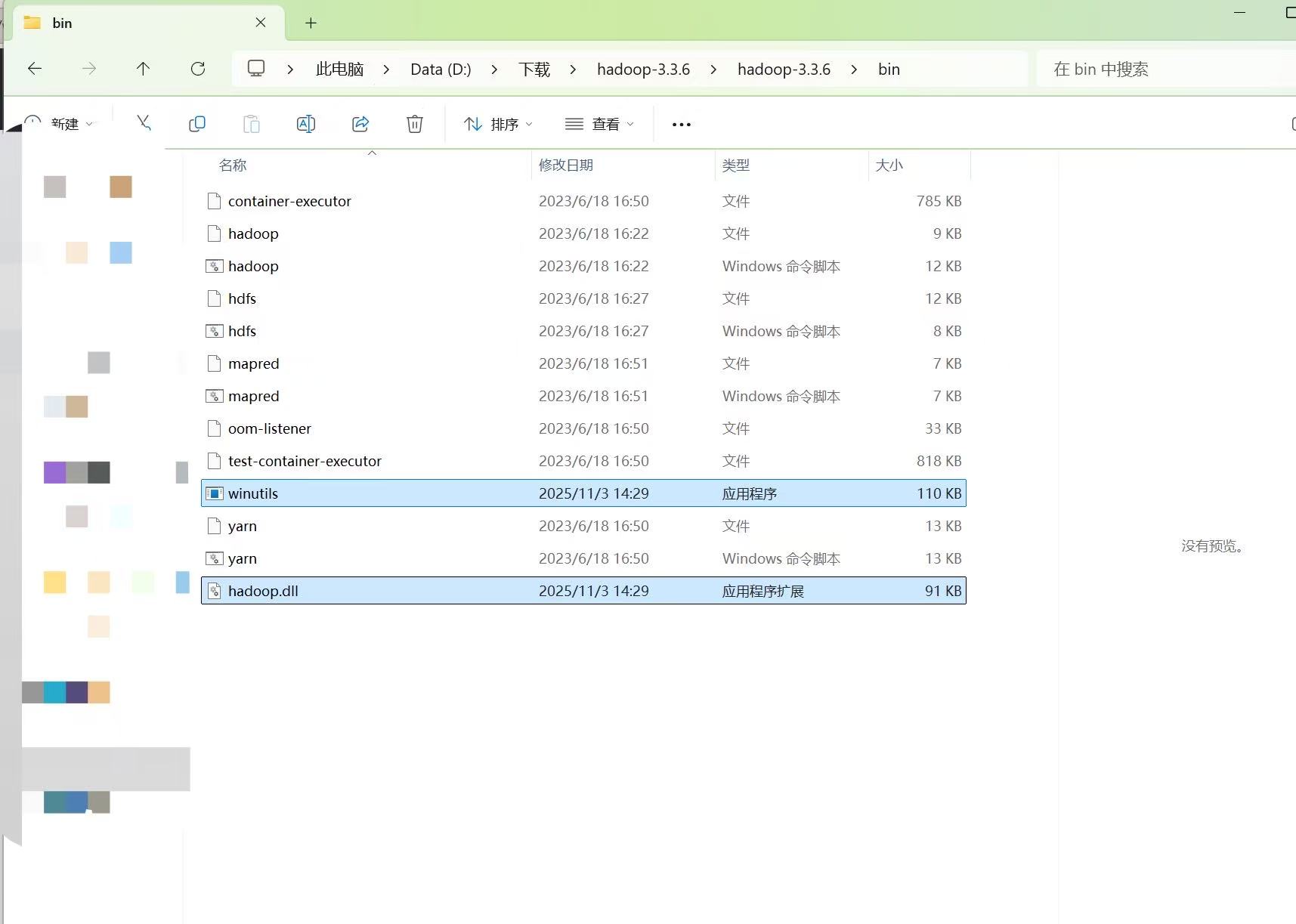
下载Windows原生库:
-
从GitHub下载
winutils.exe和hadoop.dll -
放置到
%HADOOP_HOME%\bin\目录 -
将
hadoop.dll复制到C:\Windows\System32\
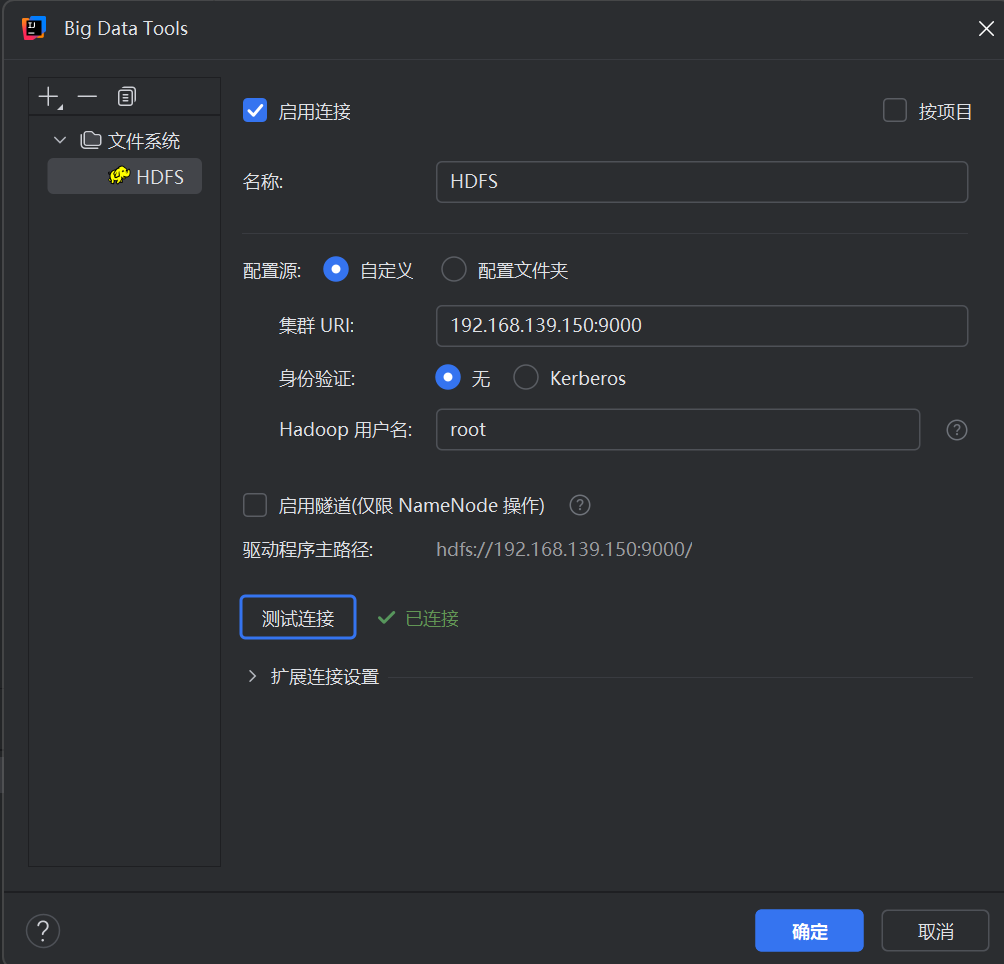
5.5Big Data Tools连接设置
在Big Data Tools面板中配置HDFS连接:
-
配置源: 自定义
-
集群URL:
192.168.139.150:9000(虚拟机IP) -
身份验证: 无
-
Hadoop用户名:
root -
启用隧道: 不勾选
六、常见问题总结
6.1 连接问题
-
确保使用正确的IP地址,不是localhost
-
检查Hadoop服务状态,使用
jps命令验证 -
确认防火墙设置,端口9000和9870需要开放
6.2 权限问题
-
Windows环境变量需要正确设置HADOOP_HOME
-
Hadoop用户名需要与实际系统用户匹配
-
文件权限可能需要使用
hdfs dfs -chmod修改
6.3 性能优化
-
配置合理的副本数(dfs.replication)
-
调整块大小根据实际需求
-
使用压缩减少存储空间和网络传输
七、总结
通过本文的详细步骤,你应该能够:
-
✅ 成功安装和配置Big Data Tools插件
-
✅ 建立稳定的HDFS连接
-
✅ 熟练进行图形化HDFS操作
-
✅ 掌握命令行和Java API操作
-
✅ 解决常见的连接和配置问题
Big Data Tools插件极大地简化了HDFS操作流程,让开发者能够更专注于业务逻辑而不是环境配置。希望这篇教程能够帮助你在大数据开发道路上更加顺畅!
欢迎在评论区留言交流你遇到的问题和解决方案!
相关资源下载:

















 685
685

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









