




作者介绍:简历上没有一个精通的运维工程师。请点击上方的蓝色《运维小路》关注我,下面的思维导图也是预计更新的内容和当前进度(不定时更新)。
我们上一章介绍了Docker基本情况,目前在规模较大的容器集群基本都是Kubernetes,但是Kubernetes涉及的东西和概念确实是太多了,而且随着版本迭代功能在还增加,笔者有些功能也确实没用过,所以只能按照我自己的理解来讲解。
我们前面通过多个小节来介绍了Kubernetes来讲解Node和Pod之间的调度和绑定关系,当我们的集群按照我们预期运行一段时间以后,某些机器因为软件或者硬件等其他原因需要进行维修,但是这些机器已经运行了不少Pod,这个时候我们应该怎么做呢?是直接暴力关机让Pod通过控制器自动飘逸到其他节点上,还是有更优雅一点的方案?针对这个问题,Kubernetes给我们提供了两个优雅的方案:隔离(Cordon)和驱逐(Eviction)。
在 Kubernetes(k8s)中,隔离(Cordon)和驱逐(Eviction)是管理节点和 Pod 的两个重要操作。
隔离(Cordon)
隔离节点是指将该节点标记为不可调度(NoSchedule),这意味着新的 Pod 不会被调度到该节点上,但是节点上正在运行的 Pod 仍然可以正常运行。
隔离节点的步骤如下:
#获取所有节点
kubectl get nodes
#对需要隔离的节点进行隔离操作
kubectl cordon node01
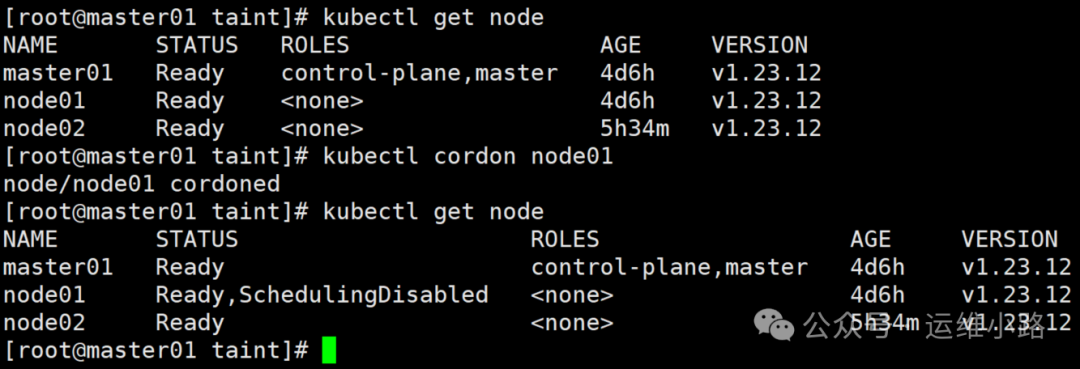
实际上这个隔离就是给这个主机打上一个污点和添加一个新字段。
Taints: node.kubernetes.io/unschedulable:NoSchedule
Unschedulable: true
#添加的污点和状态值,
隔离节点通常用于节点维护,比如升级内核、硬件维护等,以避免新的 Pod 被调度到正在维护的节点上。隔离完成以后,只是解决了新Pod无法调度进来,但是还没有解决历史Pod的问题,这个就是下面要介绍的驱逐的功能。
驱逐(Eviction)
驱逐 Pod 是指将 Pod 从节点上强制删除,通常用于节点资源不足或者节点需要维护的情况。驱逐 Pod 与直接删除 Pod 的不同之处在于,驱逐会考虑 Pod 的 QoS 级别和策略,按照一定的顺序进行。
驱逐 Pod 的步骤如下:
kubectl drain node02 --ignore-daemonsets
这个命令会驱逐节点上的所有 Pod,--ignore-daemonsets 表示忽略DaemonSet管理的 Pod。如果出现使用了本地盘的PV&PVC则需要加上下面的参数才能正常驱逐。--delete-local-data 表示即使 Pod 使用了本地数据卷也会被驱逐(但是这个驱逐以后的Pod状态会处于Pending状态,因为它的数据在这个机器,它无法被调度到其他节点,所以我们这种凡是带有数据的需要考虑它的高可用,避免出现因为这个Pod被驱逐而导致业务不可用的情况。
这两个操作都需要谨慎使用,因为它们会影响到服务的可用性和集群的稳定性。通常在进行这些操作之前,需要确保有足够的资源冗余,以及良好的监控和通知机制,以避免对业务造成不必要的影响。
维护
当我们完成隔离和驱逐以后,这个节点就只剩余DaemonSet的Pod,由于该类型的Pod级别都是属于Agent或者日志采集类,对业务无影响,所以这个时候我们可以正常对这个机器进行关机维护操作。
取消隔离
当我们对这个机器维护完成以后,开机运行以后,这个节点的状态会自动变成Ready状态,但是由于我们执行了隔离操作,所以这个时候除了DaemonSet会正常运行外,其他Pod并不会调度过来,所以我们还需要对他执行取消隔离操作。
kubectl uncordon node02
这个时候,我们的Pod就会正常调度,我们的维护就算完成,但是根据经验,我们一般会对某个Pod进行扩容操作,确保他真的能调度到这个新节点上。避免未做测试而产生其他问题。
运维小路
一个不会开发的运维!一个要学开发的运维!一个学不会开发的运维!欢迎大家骚扰的运维!
关注微信公众号《运维小路》获取更多内容。

















 1147
1147

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









