




作者介绍:简历上没有一个精通的运维工程师。请点击上方的蓝色《运维小路》关注我,下面的思维导图也是预计更新的内容和当前进度(不定时更新)。
我们上一章介绍了Docker基本情况,目前在规模较大的容器集群基本都是Kubernetes,但是Kubernetes涉及的东西和概念确实是太多了,而且随着版本迭代功能在还增加,笔者有些功能也确实没用过,所以只能按照我自己的理解来讲解。
虽然我们上一小节,介绍了健康检查的几种用法,今天我们将通过一个实际的案例来讲解。
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3 # 设置你想要维持的Pod副本数量
selector:
matchLabels:
app: nginx # 定义选择器,用于确定哪些Pod属于此Deployment
strategy:
type: RollingUpdate # 滚动更新策略
rollingUpdate:
maxUnavailable: 25% # 最大不可用Pod的比例
maxSurge: 25% # 最大浪涌Pod的比例
template: # 这是创建新Pod时使用的模板
metadata:
labels:
app: nginx # 确保Pod标签与选择器匹配
spec:
containers:
- name: nginx
image: nginx # 使用Nginx镜像的特定版本
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80 # 容器监听的端口
readinessProbe: # 添加就绪探针配置
httpGet:
path: /
port: 80
initialDelaySeconds: 60 # 探针开始执行前的等待时间
periodSeconds: 10 # 执行探针的时间间隔
timeoutSeconds: 1 # 探针超时时间
successThreshold: 1 # 成功状态的阈值
failureThreshold: 3 # 失败状态的阈值
livenessProbe: # 添加存活探针配置
httpGet:
path: /
port: 80
initialDelaySeconds: 60 # 探针开始执行前的等待时间
periodSeconds: 10 # 执行探针的时间间隔
timeoutSeconds: 1 # 探针超时时间
successThreshold: 1 # 成功状态的阈值
failureThreshold: 3 # 失败状态的阈值
前面都是deploy的配置,下面是针对2个探针的解释。
1.采用httpget方式对容器进行监控检查。
2.具体的逻辑是对容器的ip:80/进行检查,其实就是容器ip进行http请求。
3.容器启动以后,60秒以后才开始执行健康检查逻辑,因为有的程序启动需要比较长的时间,第一次执行60+10执行,未执行健康检查之前pod的状态都是0/1,执行成功以后都才会变成1/1。
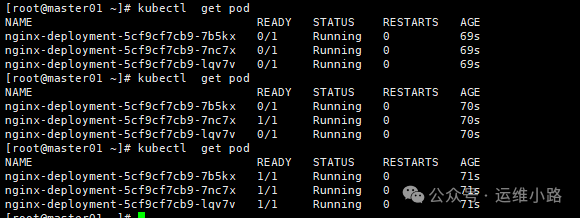
4.每个健康检查的逻辑执行间隔是10秒,也就是每10秒会执行一次2个探针。
5.如果请求容器的ip,1秒没未返回结果,则认为是超时失败。
6.如果连续失败3次,则认为容器是真的失败,这个是为了避免偶尔出现误判异常而触发逻辑。
7.如果成功一次,则说明他已经恢复。
8.健康检查的执行者是每个节点的kubelet进程,当我们排查问题的时候,就需要去检查kubelet的的日志,当然这个需要先修改kubelet的日志级别并重启kubelet才可以看到。
# 这个是修改过的配置
# 其实就是添加了 --v=7 这个参数
[root@node01 kubelet]# cat /var/lib/kubelet/kubeadm-flags.env
KUBELET_KUBEADM_ARGS="--network-plugin=cni --v=7 --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.6"


运维小路
一个不会开发的运维!一个要学开发的运维!一个学不会开发的运维!欢迎大家骚扰的运维!
关注微信公众号《运维小路》获取更多内容。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









