




 Transformer是一种使用自注意力机制的神经网络架构,对比传统序列转换模型,如RNN和CNN,具备更高的并行性和训练速度,尤其在机器翻译任务中表现优越。其关键在于自注意力机制,能捕捉全局依赖关系,通过多头注意力和前馈神经网络实现高效信息处理。Transformer的应用前景广阔,包括语音识别、图像处理和自然语言生成等领域。
Transformer是一种使用自注意力机制的神经网络架构,对比传统序列转换模型,如RNN和CNN,具备更高的并行性和训练速度,尤其在机器翻译任务中表现优越。其关键在于自注意力机制,能捕捉全局依赖关系,通过多头注意力和前馈神经网络实现高效信息处理。Transformer的应用前景广阔,包括语音识别、图像处理和自然语言生成等领域。
这篇文章主要介绍了一种新的神经网络架构——Transformer,它使用自注意力机制来计算输入和输出的表示,相比传统序列转换模型具有更高的并行性和更快的训练速度,并在机器翻译等序列转换任务中实现了最先进的性能。文章详细介绍了Transformer架构、自注意力机制以及与传统序列转换模型的比较,并探讨了Transformer在其他领域中的应用前景。文章提出了以下几个要点:
1. Transformer架构是一种新颖而有效的神经网络架构,它使用自注意力机制来计算输入和输出的表示。
2. 自注意力机制是一种关键技术,它使用查询、键和值来计算注意力权重,并将这些权重应用于值以生成加权表示。
3. Transformer相对于传统序列转换模型具有更高的并行性和更快的训练速度,并在机器翻译等序列转换任务中实现了最先进的性能。
4. Transformer在其他领域中也有广泛的应用前景,例如语音识别、图像处理和自然语言生成等任务。
FQA
Transformer架构是什么?它与传统序列转换模型有何不同之处?
Keyword:自注意力机制 序列转换模型 基础模型 并行性 训练速度
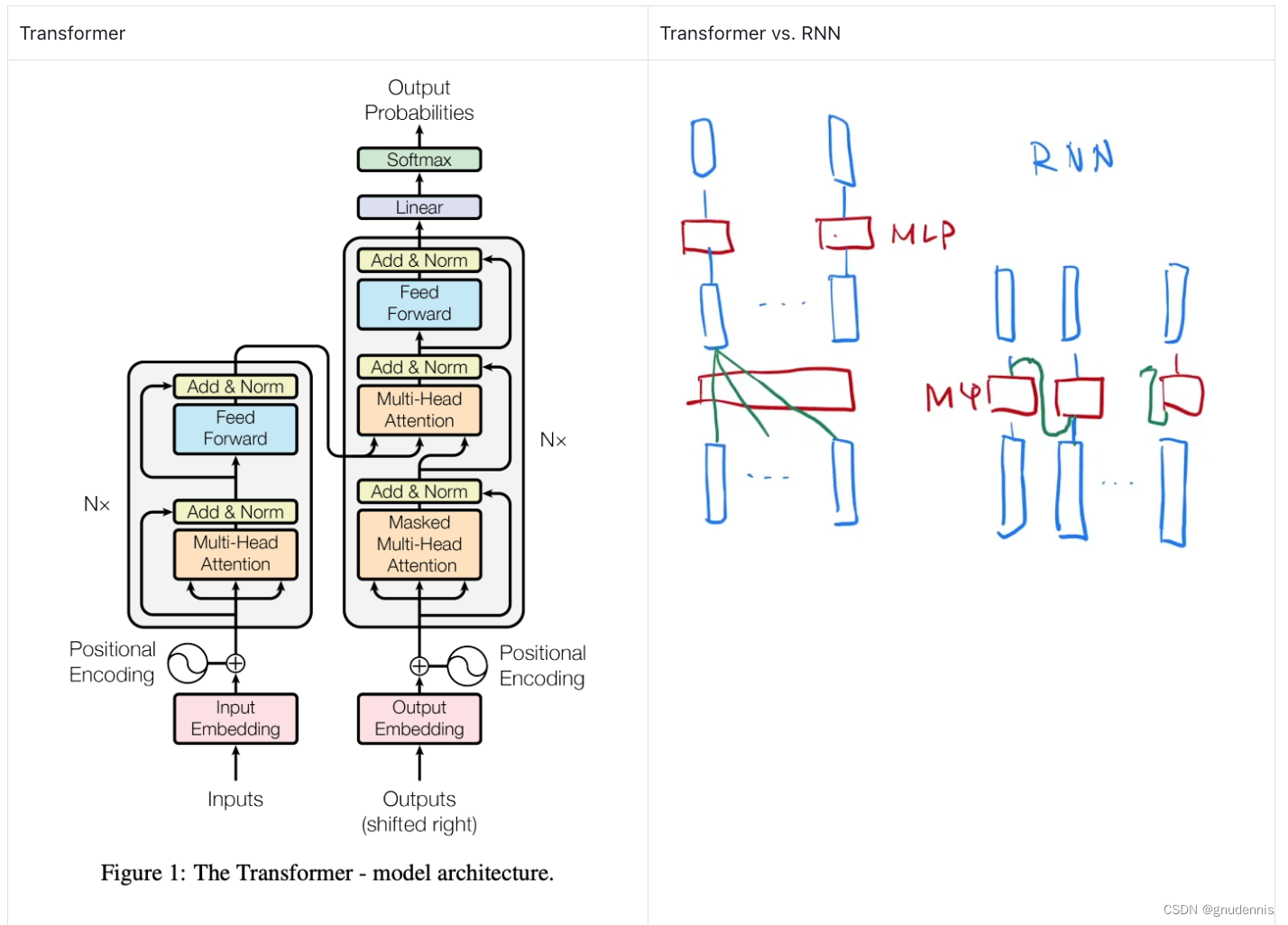
Transformer是一种基于注意力机制的序列转换模型,它在编码器和解码器中使用了多头自注意力机制和前馈神经网络,开创了继MLP、CNN和RNN之后的第四大类模型(基础模型)。与传统的序列转换模型(如循环神经网络和卷积神经网络)不同,Transformer完全依赖于自注意力机制来计算输入和输出的表示,从而消除了循环或卷积操作。这使得Transformer具有更好的并行性和更快的训练速度,并且在翻译质量方面表现出色。具体说来,Transformer具有以下不同之处:
1. 没有使用循环结构:传统的RNN模型使用循环结构来处理序列数据,但这种结构会导致难以并行化和梯度消失等问题。Transformer通过自注意力机制来处理序列数据,避免了这些问题。
2. 使用自注意力机制:传统的RNN和CNN模型通常使用固定大小的窗口或滑动窗口来处理序列数据,但这种方法可能会忽略长距离依赖关系。Transformer使用自注意力机制来计算每个位置与其他位置之间的关系,并根据这些关系对输入进行加权平均。
3. 使用残差连接和层归一化:为了避免深层网络中梯度消失或爆炸等问题,Transformer使用残差连接和层归一化技术。残差连接可以使信息在网络中更容易地流动,而层归一化可以使每个子层输出具有相似的分布。
4. 更高效的训练和推理:由于Transformer中的每个位置都可以并行计算,因此它比传统的RNN和CNN模型更容易并行化。此外,Transformer还使用了一些技巧来加速训练和推理,如掩码自注意力机制、预测性掩码等。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 559
559

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









