



 本文深入探讨了Java注解处理器的工作原理,详细解析了javac如何处理注解,包括注解处理器的初始化、注解的发现与处理流程,以及如何生成新的源代码。通过实例演示了注解在语法树中的表示方式。
本文深入探讨了Java注解处理器的工作原理,详细解析了javac如何处理注解,包括注解处理器的初始化、注解的发现与处理流程,以及如何生成新的源代码。通过实例演示了注解在语法树中的表示方式。
写一个注解使用类,如下:
public class Test {
@Code(author = "mazhi",date="20170611")
private void process() {
}
}
使用Javac提供的api来运行Test类。在javac的Launcher类中编写如下代码:
JavaCompiler javac = ToolProvider.getSystemJavaCompiler();
String commonPath = "H:\\program workspace\\project\\Compiler_javac\\";
String str27 = commonPath+"test\\com\\test01\\Test.java";
javac.run(System.in, null, null,
//"-verbose",
//"-Xprint",
"-XprintRounds",
"-XprintProcessorInfo",
"-processor","com.test01.CodeProcessor",
"-d", "C:\\Users\\Administrator.PC-20160319ZQPU\\workspace\\tmp\\tmpdir\\",
str27); -Xprint表示打印出注解类,也就是Code类的代码。
-XprintRounds 打印出每一次Round的情况
-processor指定了注解处理器,注意这个包名必须在源代码目录下,不能在test目录或者其它路径下,否则不能加载到classpath中。
-d表示输出路径,CodeProcessor注解处理类生成的类路径,在运行CodeProcessor后生成的类名为GenerateTest如下:
package com.test01;
class TestAutogenerate {
protected TestAutogenerate() {}
protected final void message() {
//process()
//@com.test01.Code(date=20170611, author=mazhi)
System.out.println("author:mazhi");
System.out.println("date:20170611");
}
}
下面来看javac的具体处理过程。
1、在javac的compile方法中会调用initProcessAnnotations(processors)方法
initProcessAnnotations(processors)方法的具体代码如下:
/**
* Check if we should process annotations.
* If so, and if no scanner is yet registered, then set up the DocCommentScanner
* to catch doc comments, and set keepComments so the parser records them in the compilation unit.
*
* @param processors user provided annotation processors to bypass
* discovery, {@code null} means that no processors were provided
*/
public void initProcessAnnotations(Iterable<? extends Processor> processors) {
// Process annotations if processing is not disabled and there
// is at least one Processor available.
if (options.isSet(PROC, "none")) {
processAnnotations = false;
} else if (procEnvImpl == null) {
procEnvImpl = new JavacProcessingEnvironment(context, processors);
processAnnotations = procEnvImpl.atLeastOneProcessor();
if (processAnnotations) {
options.put("save-parameter-names", "save-parameter-names");
reader.saveParameterNames = true;
keepComments = true;
genEndPos = true;
if (taskListener != null)
taskListener.started(new TaskEvent(TaskEvent.Kind.ANNOTATION_PROCESSING));
log.deferDiagnostics = true;
} else { // free resources
procEnvImpl.close();
}
}
} 最主要的逻辑就是在创建JavacProcessingEnvironment对象,这个对象的构造函数中会调用initProcessorIterator(context, processors);
主要的代码如下:
private void initProcessorIterator(Context context, Iterable<? extends Processor> processors) {
Log log = Log.instance(context);
Iterator<? extends Processor> processorIterator;
if (options.isSet(XPRINT)) {
try {
Processor processor = PrintingProcessor.class.newInstance();
processorIterator = List.of(processor).iterator();
} catch (Throwable t) {
AssertionError assertError = new AssertionError("Problem instantiating PrintingProcessor.");
assertError.initCause(t);
throw assertError;
}
} else if (processors != null) {
processorIterator = processors.iterator();
} else {
String processorNames = options.get(PROCESSOR);
JavaFileManager fileManager = context.get(JavaFileManager.class);
try {
// If processorpath is not explicitly set, use the classpath.
processorClassLoader = fileManager.hasLocation(ANNOTATION_PROCESSOR_PATH)
? fileManager.getClassLoader(ANNOTATION_PROCESSOR_PATH)
: fileManager.getClassLoader(CLASS_PATH);
/*
* If the "-processor" option is used, search the appropriate
* path for the named class. Otherwise, use a service
* provider mechanism to create the processor iterator.
*/
if (processorNames != null) {
processorIterator = new NameProcessIterator(processorNames, processorClassLoader, log);
} else {
processorIterator = new ServiceIterator(processorClassLoader, log);
}
} catch (SecurityException e) {
/*
* A security exception will occur if we can't create a classloader.
* Ignore the exception if, with hindsight, we didn't need it anyway
* (i.e. no processor was specified either explicitly, or implicitly,
* in service configuration file.) Otherwise, we cannot continue.
*/
processorIterator = handleServiceLoaderUnavailability("proc.cant.create.loader", e);
}
}
discoveredProcs = new DiscoveredProcessors(processorIterator);
}
不难看出这个逻辑通过对-Xprint命令进行判断,如果设置了,那么就会打印注解类的代码(注意不是使用注解类的代码),其中打印已经有了默认的注解处理实现类PrintingProcessor。
最后一个else循环中对-processor命令进行了处理,得到的值就是我们指定的注解处理类CodeProcessor。接着往下面的逻辑看,从两处查找注解处理类Processor,这里用到了迭代器模式,有NameProcessIterator与ServiceIterator。
(1)NameProcessIterator主要处理-processor命令指定的注解处理器,指定多个时使用逗号分割,这样就可以通过这个注解处理器迭代获取
(2)ServiceIterator主要处理 /META-INF/services/下指定的注解处理器,在前面说过。
最后一段代码生成一个DiscoveredProcessors对象。
2、在initProcessAnnotations(processors)方法中调用JavacProcessingEnvironment的atLeastOneProcessor()方法
public boolean atLeastOneProcessor() {
return discoveredProcs.iterator().hasNext();
}
DiscoveredProcessor是一个双层的迭代器,具体代码如下:
// TODO: These two classes can probably be rewritten better...
/**
* This class holds information about the processors that have
* been discoverd so far as well as the means to discover more, if
* necessary. A single iterator should be used per round of
* annotation processing. The iterator first visits already
* discovered processors then fails over to the service provider
* mechanism if additional queries are made.
*/
class DiscoveredProcessors implements Iterable<ProcessorState> {
// 省略内部的ProcessorStateIterator迭代器
Iterator<? extends Processor> processorIterator;
ArrayList<ProcessorState> procStateList;
public ProcessorStateIterator iterator() {
return new ProcessorStateIterator(this); // 创建一个内部的迭代器ProcessorStateIterator类对象
}
DiscoveredProcessors(Iterator<? extends Processor> processorIterator) {
this.processorIterator = processorIterator;
this.procStateList = new ArrayList<ProcessorState>();
}
/**
* Free jar files, etc. if using a service loader.
*/
public void close() {
if (processorIterator != null &&
processorIterator instanceof ServiceIterator) {
((ServiceIterator) processorIterator).close();
}
}
}
DiscoveredProcessors内部的迭代器如下:
class ProcessorStateIterator implements Iterator<ProcessorState> {
DiscoveredProcessors psi;
Iterator<ProcessorState> innerIter;
boolean onProcInterator;
ProcessorStateIterator(DiscoveredProcessors psi) {
this.psi = psi;
this.innerIter = psi.procStateList.iterator();
this.onProcInterator = false;
}
public ProcessorState next() {
if (!onProcInterator) {
if (innerIter.hasNext())
return innerIter.next();
else
onProcInterator = true;
}
if (psi.processorIterator.hasNext()) {
ProcessorState ps = new ProcessorState(psi.processorIterator.next(),
log, source, JavacProcessingEnvironment.this);
psi.procStateList.add(ps);
return ps;
} else
throw new NoSuchElementException();
}
public boolean hasNext() {
if (onProcInterator)
return psi.processorIterator.hasNext();
else
return innerIter.hasNext() || psi.processorIterator.hasNext();
}
public void remove () {
throw new UnsupportedOperationException();
}
/**
* Run all remaining processors on the procStateList that
* have not already run this round with an empty set of annotations.
*/
public void runContributingProcs(RoundEnvironment re) {
if (!onProcInterator) {
Set<TypeElement> emptyTypeElements = Collections.emptySet();
while(innerIter.hasNext()) {
ProcessorState ps = innerIter.next();
if (ps.contributed)
callProcessor(ps.processor, emptyTypeElements, re);
}
}
}
} 重点注意如上next()方法的一个处理逻辑,优先返回procStateList中的注解处理器。
这个类涉及到另外一个重要的类ProcessorState,主要的代码逻辑段如下:
/**
* State about how a processor has been used by the tool. If a
* processor has been used on a prior round, its process method is
* called on all subsequent rounds, perhaps with an empty set of
* annotations to process. The {@code annotatedSupported} method
* caches the supported annotation information from the first (and
* only) getSupportedAnnotationTypes call to the processor.
*/
static class ProcessorState {
public Processor processor;
public boolean contributed;
private ArrayList<Pattern> supportedAnnotationPatterns;
private ArrayList<String> supportedOptionNames;
ProcessorState(Processor p, Log log, Source source, ProcessingEnvironment env) {
processor = p;
contributed = false;
try {
processor.init(env);
checkSourceVersionCompatibility(source, log);
supportedAnnotationPatterns = new ArrayList<Pattern>();
for (String importString : processor.getSupportedAnnotationTypes()) {
supportedAnnotationPatterns.add(importStringToPattern(importString,
processor,
log));
}
supportedOptionNames = new ArrayList<String>();
for (String optionName : processor.getSupportedOptions() ) {
if (checkOptionName(optionName, log))
supportedOptionNames.add(optionName);
}
} catch (ClientCodeException e) {
throw e;
} catch (Throwable t) {
throw new AnnotationProcessingError(t);
}
}
// 省略一些方法
}
3、调用processAnnotations()方法运行注解处理器
这个方法的运行时机是完成词法和语法分析,并且输入符号表的过程完成后进行调用。
主要执行了代码:procEnvImpl.doProcessing(context, roots, classSymbols, pckSymbols)
主要的逻辑代码段如下:
Round round = new Round(context, roots, classSymbols);
boolean errorStatus;
boolean moreToDo;
do {
// Run processors for round n
round.run(false, false);
// Processors for round n have run to completion.
// Check for errors and whether there is more work to do.
errorStatus = round.unrecoverableError();
moreToDo = moreToDo();
round.showDiagnostics(errorStatus || showResolveErrors);
// Set up next round.
// Copy mutable collections returned from filer.
round = round.next(
new LinkedHashSet<JavaFileObject>(filer.getGeneratedSourceFileObjects()),
new LinkedHashMap<String,JavaFileObject>(filer.getGeneratedClasses()));
// Check for errors during setup.
if (round.unrecoverableError())
errorStatus = true;
} while (moreToDo && !errorStatus);
// run last round
round.run(true, errorStatus);
round.showDiagnostics(true);
3.1、创建一个Round类对像,主要的逻辑是调用了findAnnotationsPresent()方法,代码如下:
/** Find the set of annotations present in the set of top level
* classes and package info files to be processed this round. */
void findAnnotationsPresent() {
ComputeAnnotationSet annotationComputer = new ComputeAnnotationSet(elementUtils);
// Use annotation processing to compute the set of annotations present
annotationsPresent = new LinkedHashSet<TypeElement>();
for (ClassSymbol classSym : topLevelClasses)
annotationComputer.scan(classSym, annotationsPresent);
for (PackageSymbol pkgSym : packageInfoFiles)
annotationComputer.scan(pkgSym, annotationsPresent);
} 其中的topLevelClasses的值如下截图:
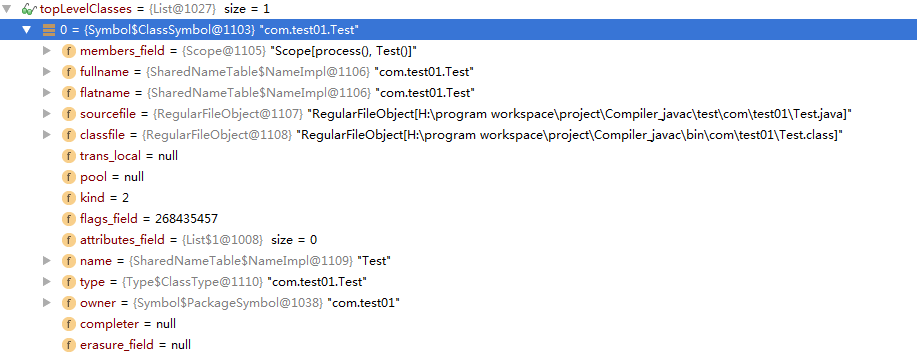
运行完成后的annotationsPresent值如下截图。
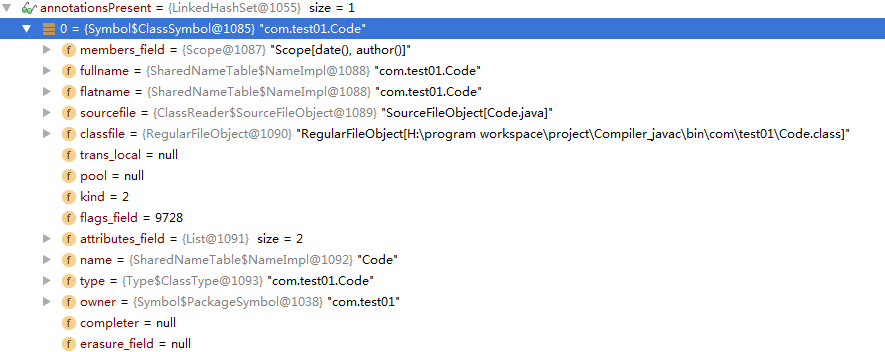
可以看到为process()方法找到了对应的注解类Code。下面来看查找Test()与process()方法注解的具体过程。
涉及到一个类ComputeAnnotationSet,代码如下:
/**
* Computes the set of annotations on the symbol in question.
* Leave class public for external testing purposes.
*/
public static class ComputeAnnotationSet extends ElementScanner7<Set<TypeElement>, Set<TypeElement>> {
final Elements elements;
public ComputeAnnotationSet(Elements elements) {
super();
this.elements = elements;
}
@Override
public Set<TypeElement> visitPackage(PackageElement e, Set<TypeElement> p) {
// Don't scan enclosed elements of a package
return p;
}
@Override
public Set<TypeElement> scan(Element e, Set<TypeElement> p) {
for (AnnotationMirror annotationMirror : elements.getAllAnnotationMirrors(e) ) {
Element e2 = annotationMirror.getAnnotationType().asElement();
p.add((TypeElement) e2);
}
return super.scan(e, p);
}
}
调用scan()方法时elements对象为JavacElements类对象,前面介绍过。由于Test的ClassSymbol没有注解,所以不走for循环。继续调用super.scan(e,p)方法继续执行查找注解元素。
关于Element中定义的访问者方法<R, P> R accept(ElementVisitor<R, P> v, P p);
但是只有TypeSymbol,PackageSymbol、ClassSymbol、VarSymbol、DelegatedSymbol实现了这个方法。
同样最终会使用scan方法来处理process()方法,其中e为MethodSymbol类型,如下截图:
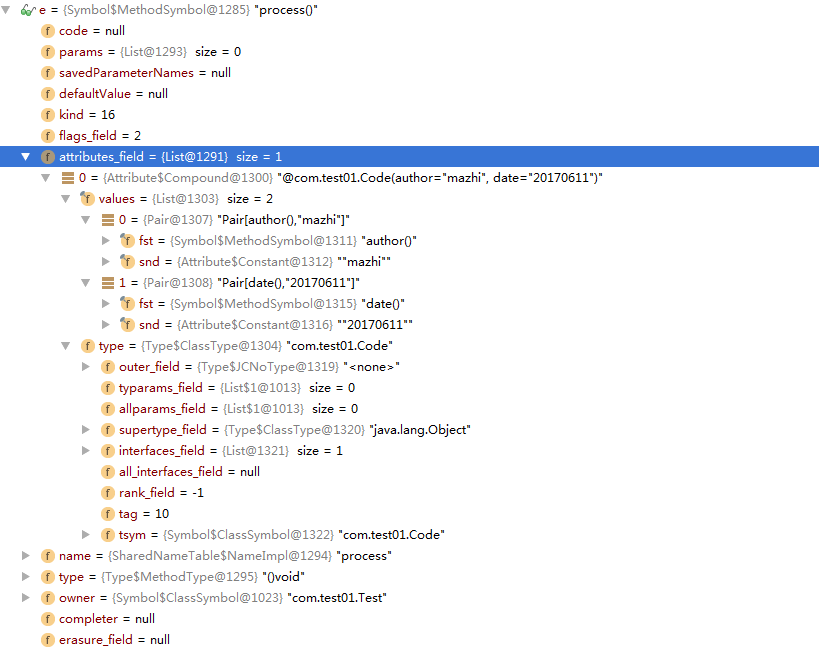
其中getAllAnnotationMirrors()方法的代码如下:
/**
* Returns all annotations of an element, whether inherited or directly present.
* @param e the element being examined
* @return all annotations of the element
*/
public List<com.sun.tools.javac.code.attribute.Compound> getAllAnnotationMirrors(Element e) {
Symbol sym = cast(Symbol.class, e);
// 返回Symbol中的attribute_field属性
List<com.sun.tools.javac.code.attribute.Compound> annos = sym.getAnnotationMirrors();
while (sym.getKind() == ElementKind.CLASS) {
Type sup = ((ClassSymbol) sym).getSuperclass();
if (sup.typeTag != TypeTags.CLASS || sup.isErroneous() ||
sup.typeSymbol == syms.objectType.typeSymbol) {
break;
}
sym = sup.typeSymbol;
List<com.sun.tools.javac.code.attribute.Compound> oldAnnos = annos;
for (com.sun.tools.javac.code.attribute.Compound anno : sym.getAnnotationMirrors()) {
if (isInherited(anno.type) &&
!containsAnnoOfType(oldAnnos, anno.type)) {
annos = annos.prepend(anno);
}
}
}
return annos;
}
返回后进入循环获取的annotatonMirror如下截图:
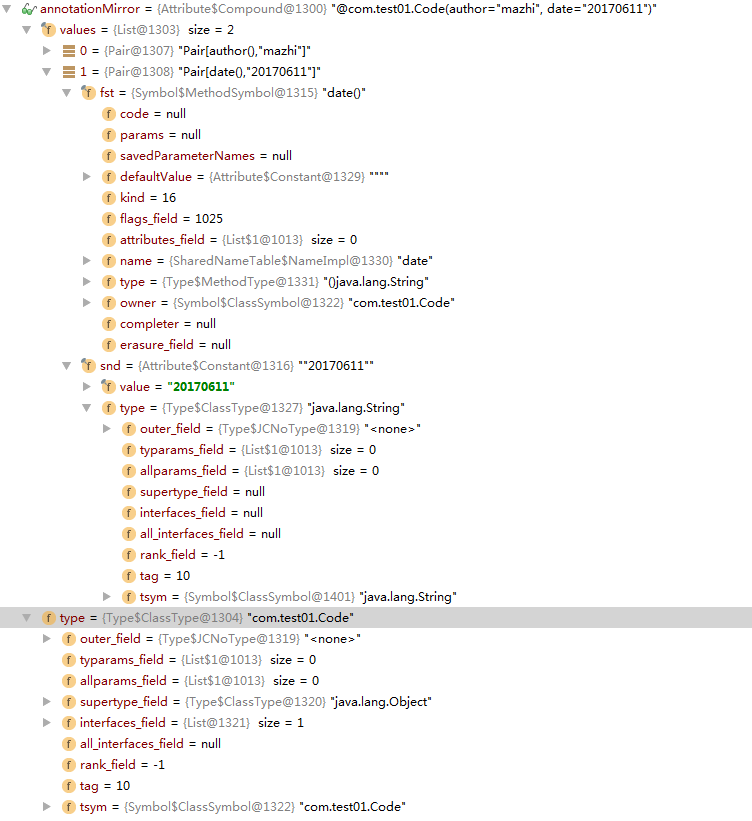
最后调用这个对象的getAnnotationType()方法,返回对象后调用asElement()方法,也就是获取type的tsym属性值,从上图可看出是Code类。
3.2、调用Round类对象的round.run(false, false)方法
/** Run a processing round. */
void run(boolean lastRound, boolean errorStatus) {
printRoundInfo(lastRound);
try {
if (lastRound) {
filer.setLastRound(true);
Set<Element> emptyRootElements = Collections.emptySet(); // immutable
RoundEnvironment renv = new JavacRoundEnvironment(true,
errorStatus,
emptyRootElements,
JavacProcessingEnvironment.this);
discoveredProcs.iterator().runContributingProcs(renv);
} else {
discoverAndRunProcs(context, annotationsPresent, topLevelClasses, packageInfoFiles);
}
} finally {
if (taskListener != null)
taskListener.finished(new TaskEvent(TaskEvent.Kind.ANNOTATION_PROCESSING_ROUND));
}
nMessagerErrors = messager.errorCount();
}
因为首次运行时lastRound值为false,所以运行discoverAndRunProcs()方法,具体代码如下:
private void discoverAndRunProcs(Context context,
Set<TypeElement> annotationsPresent,
List<ClassSymbol> topLevelClasses,
List<PackageSymbol> packageInfoFiles) {
Map<String, TypeElement> unmatchedAnnotations = new HashMap<String, TypeElement>(annotationsPresent.size());
for(TypeElement a : annotationsPresent) {
unmatchedAnnotations.put(a.getQualifiedName().toString(), a);
}
// Give "*" processors a chance to match
if (unmatchedAnnotations.size() == 0)
unmatchedAnnotations.put("", null);
DiscoveredProcessors.ProcessorStateIterator psi = discoveredProcs.iterator();
// TODO: Create proper argument values; need past round
// information to fill in this constructor. Note that the 1
// st round of processing could be the last round if there
// were parse errors on the initial source files; however, we
// are not doing processing in that case.
Set<Element> rootElements = new LinkedHashSet<Element>();
rootElements.addAll(topLevelClasses);
rootElements.addAll(packageInfoFiles);
rootElements = Collections.unmodifiableSet(rootElements);
RoundEnvironment renv = new JavacRoundEnvironment(false,
false,
rootElements,
JavacProcessingEnvironment.this);
while(unmatchedAnnotations.size() > 0 && psi.hasNext() ) {
ProcessorState ps = psi.next();
Set<String> matchedNames = new HashSet<String>();
Set<TypeElement> typeElements = new LinkedHashSet<TypeElement>();
for (Map.Entry<String, TypeElement> entry: unmatchedAnnotations.entrySet()) {
String unmatchedAnnotationName = entry.getKey();
if (ps.annotationSupported(unmatchedAnnotationName) ) {
matchedNames.add(unmatchedAnnotationName);
TypeElement te = entry.getValue();
if (te != null)
typeElements.add(te);
}
}
if (matchedNames.size() > 0 || ps.contributed) {
boolean processingResult = callProcessor(ps.processor, typeElements, renv);
ps.contributed = true;
ps.removeSupportedOptions(unmatchedProcessorOptions);
if (printProcessorInfo || verbose) {
log.printNoteLines("x.print.processor.info",
ps.processor.getClass().getName(),
matchedNames.toString(),
processingResult);
}
if (processingResult) {
unmatchedAnnotations.keySet().removeAll(matchedNames);
}
}
}
unmatchedAnnotations.remove("");
if (lint && unmatchedAnnotations.size() > 0) {
// Remove annotations processed by javac
unmatchedAnnotations.keySet().removeAll(platformAnnotations);
if (unmatchedAnnotations.size() > 0) {
log = Log.instance(context);
log.warning("proc.annotations.without.processors",unmatchedAnnotations.keySet());
}
}
// Run contributing processors that haven't run yet
psi.runContributingProcs(renv);
// Debugging
if (options.isSet("displayFilerState"))
filer.displayState();
}
3.2、调用next()方法生成新的Round对象
由于生成了新的源代码类GenerateTest,所以需要继续进行处理,但这次调用的构造方法与上次不同,如下:
/** Create a new round. */
private Round(Round prev,
Set<JavaFileObject> newSourceFiles, Map<String,JavaFileObject> newClassFiles) {
this(prev.nextContext(),
prev.number+1,
prev.nMessagerErrors,
prev.compiler.log.nwarnings);
this.genClassFiles = prev.genClassFiles;
List<JCCompilationUnit> parsedFiles = compiler.parseFiles(newSourceFiles);
roots = cleanTrees(prev.roots).appendList(parsedFiles);
// Check for errors after parsing
if (unrecoverableError())
return;
enterClassFiles(genClassFiles);
List<ClassSymbol> newClasses = enterClassFiles(newClassFiles);
genClassFiles.putAll(newClassFiles);
enterTrees(roots);
if (unrecoverableError())
return;
topLevelClasses = join(
getTopLevelClasses(parsedFiles),
getTopLevelClassesFromClasses(newClasses));
packageInfoFiles = join(
getPackageInfoFiles(parsedFiles),
getPackageInfoFilesFromClasses(newClasses));
findAnnotationsPresent();
} 同样也调用了findAnnotationPresent()方法。这样创建了Round后继续调用run()方法。
上一篇提到了实现Annotation注解处理器的一些重要的类,如Message,Filer。
Message用来报告错误,警告和其他提示信息。
JavacFilter用来创建新的源文件,class文件以及辅助文件。
下面来看看javac中的具体实现。
(1)JavacFiler
首先看下JavacFiler的继承体系,其中主要包括两大块,操作流和表示的文件类型。
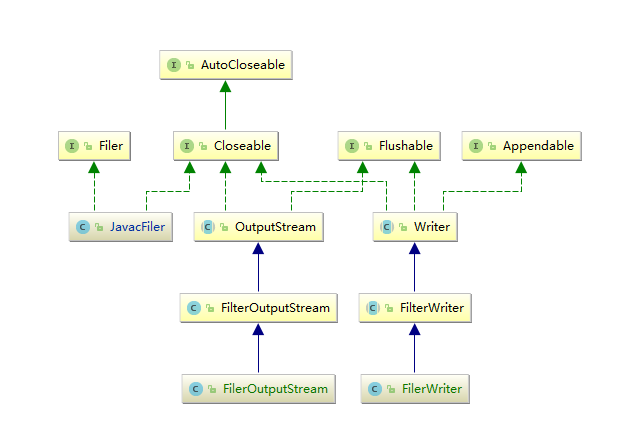
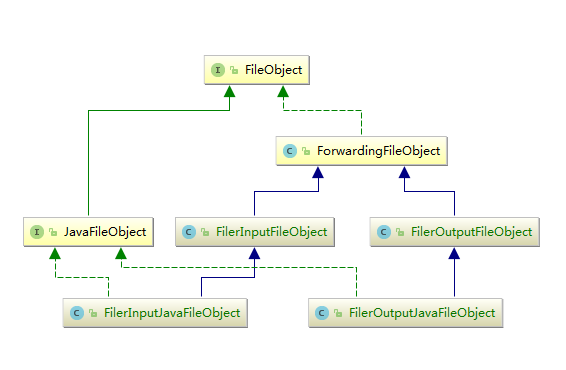
(2)JavacRoundEnvironment
sdddddd
(3)JavacProcessingEnvironment
举个例子来看一看注解定义类在语法树中用哪些语法节点来表示以及如何组织的。
@Retention(RetentionPolicy.RUNTIME) // 注解会在class中存在,运行时可通过反射获取
@Target(ElementType.METHOD) // 目标是方法
@Documented // 文档生成时,该注解将被包含在javadoc中,可去掉
public @interface TestAnnotation {
public String name() default "helloworld";
}
查看JCClassDecl语法节点(注解类也被当作一个类来表示)的jcModifiers属性,截图如下。
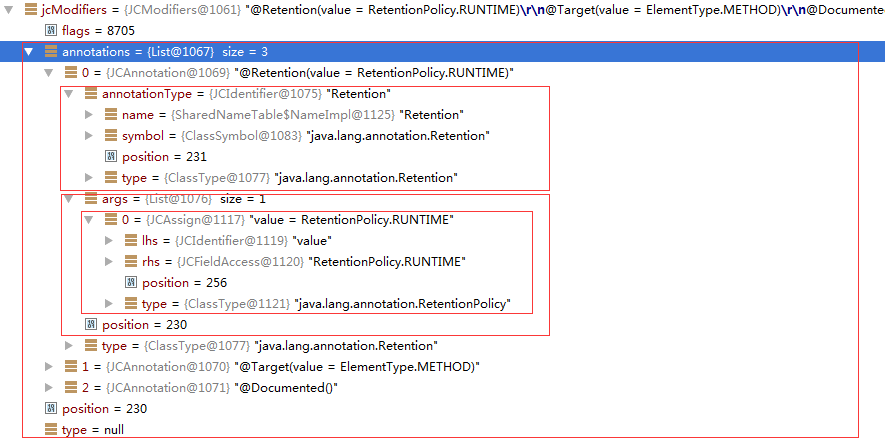
jcModifiers中的flags属性值为8705,必写为这样的表示:
(1<<13)|(1<<0)|(1<<9)
查看Flags中关于各个Modifiers指定的常量,可知是public和interface且还有个专门表示annotation的静态常量,如下:
/** Flag that marks attribute interfaces 标记属性接口, added in classfile v49.0.
* 应该只能修饰注解定义类
*/
public static final int ANNOTATION = 1<<13;
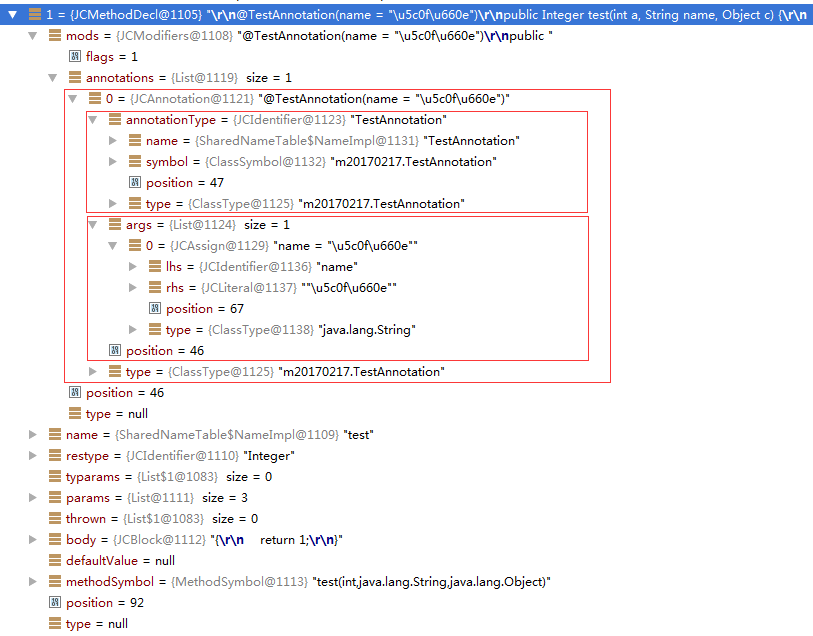
然后看一下JCMethodDecl属性,截图如下:
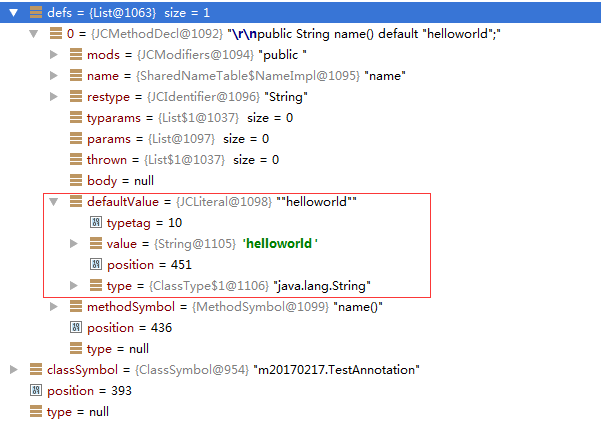
使用如上的注解,如下:
public class C {
@TestAnnotation(name = "小明")
public Integer test(int a, String name, Object c) {
return 1;
}
}
截图如下:

















 27万+
27万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









