






随着人工智能和大数据技术的飞速发展,传统的关系型数据库已经无法支持海量数据规模的存储、处理及响应能力,如何提高海量数据的查询分析以及处理能力显得至关重要。当前采用分布式架构是各企业解决海量数据高效查询统计的有效方案,但是为了维护分布式数据一致性,需要以降低读写性能为代价。

ELK是三个开源软件Elasticsearch、Logstash、Kibana,其卓越的数据采集、处理、检索能力使得越来越多的企业将其引入其中,三者之间相互配合使 ELK逐渐成为了日志分析领域的实施标准,为企业提供了丰富的功能处理海量数据。
随着系统规模不断扩大,各个系统在面对海量数据时的存储以及查询响应能力面临挑战,而Logstash和Elasticsearch作为ELK的核心,其重要性不言而喻。
同时,本文阐述了在ARM环境下,Logstash的实践过程及解决方案。
ELK平台是一套完整的日志集中处理解决方案。其中,Elasticsearch是个开源分布式搜索引擎,主要提供搜集、分析、存储数据三大功能,具备强大的全文搜索能力和实时分析功能,并且具备分布式特性,能够处理海量数据和高并发请求;同时,还支持水平扩展,能够自动分片和复制数据以实现高可用性和容错性。
Logstash 是一个用于收集、过滤、转换和传输数据的工具。它支持共多种来源采集数据,并将数据发送到 Elasticsearch 或者其他目标存储。同时,Logstash也提供了丰富的插件和过滤器,可以对数据进行解析、转换和丰富,从而满足不同的业务需求。
Kibana 是一个用于可视化和分析 Elasticsearch 数据的工具。它提供了丰富的图表、仪表板以及搜索界面,能够帮助用户直观的理解和分析数据。
1.1Logstash平台搭建及适配性改造
本文以7.4.2版本为例进行配置说明。X86服务器环境能够完全兼容ELK7.4.2,而在ARM服务器环境中,需要对Logstash进行适配性改造,操作步骤如图1所示。
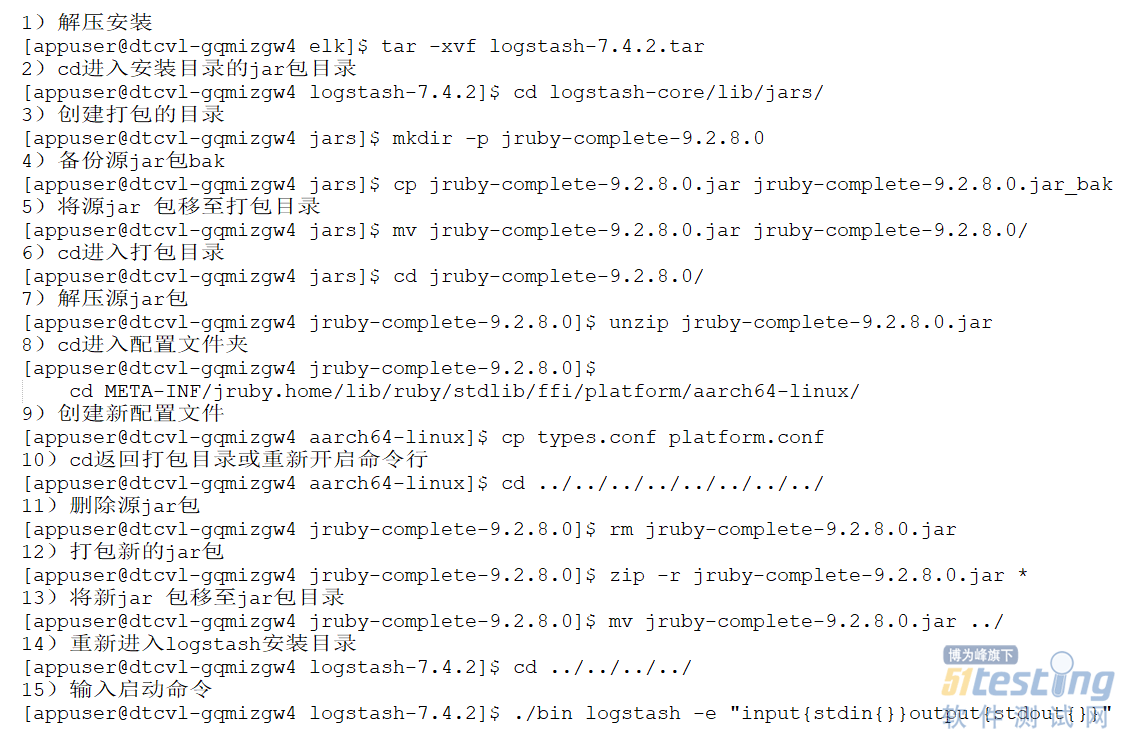
图1 Logstash配置文件修改
启动成功后控制台会有如图2的提示信息,正常显示后Logstash就可以监听控制台的输入信息。
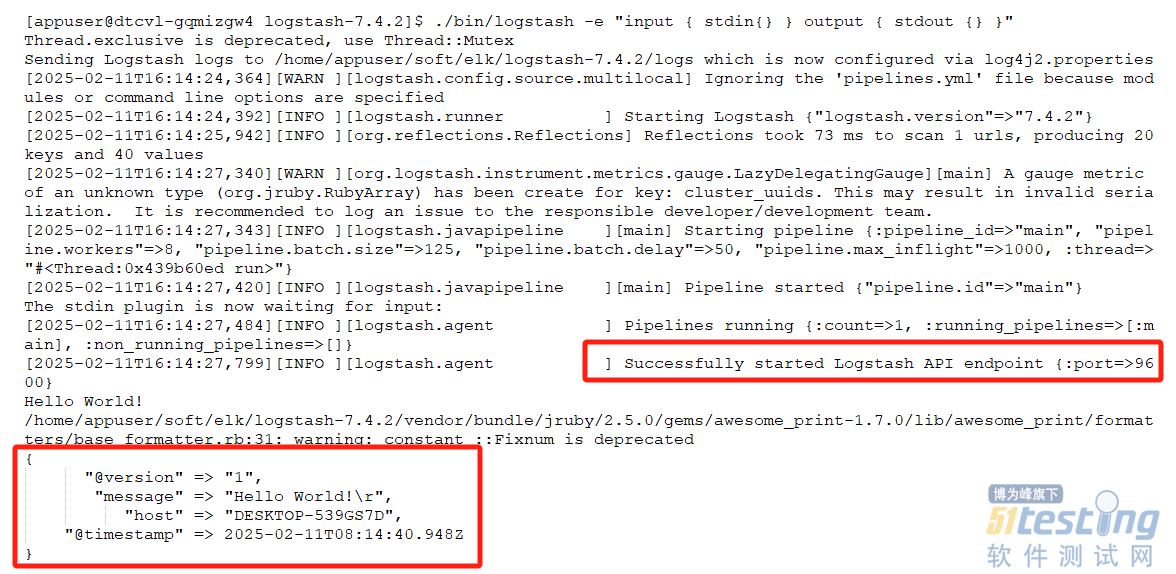
图2 Logstash启动示例
1.2 Elasticsearch集群配置
在ARM和X86环境中均可直接解压官网下载的Elasticsearch安装包后启动服务,但如果需要以集群方式提供服务,需要修改Elasticsearch 安装目录下config文件夹中的elasticearch.yml文件。
1.2.1 yml配置文件修改
Linux控制台切换至Elasticsearch安装目录,修改elasticsearch.yml文件,如图3-图7所示。
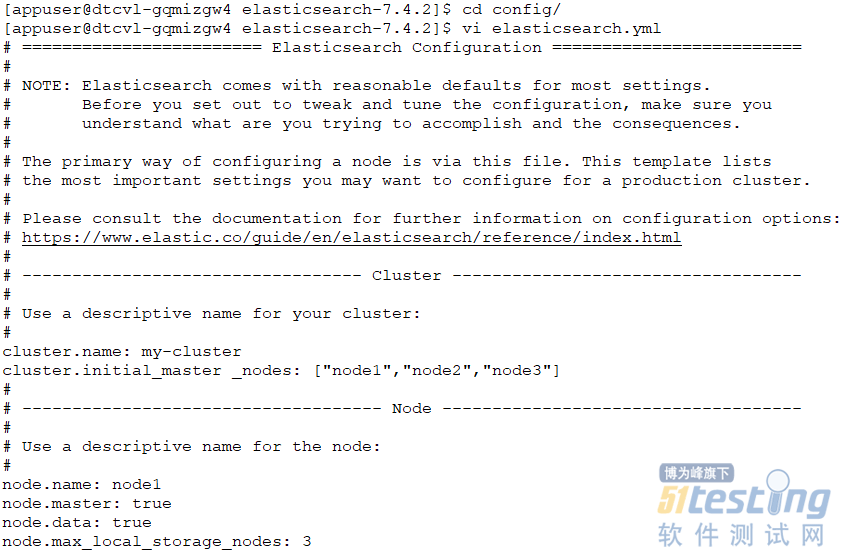
图3 Elasticsearch集群及节点配置
cluster.name:Elasticsearch集群名称;
cluster.initial_master_nodes: Elasticsearch 集群的节点名,有几台服务器需要加入集群,就需要在集合中设置几个节点名;
node.name::节点名,属于当前服务器的参数,cluster.initial_master_nodes是节点集合,集合中包含所有的节点名;
node.master:是否可以被推举为管理节点;
node.data::是否要作为数据节点;
node.max_local_storage_nodes:最大可以存储数据的节点数。

图4 数据及日志目录配置
path.data:数据存储目录,需要配置多个目录时中间以英文逗号分隔,集群进行扩容时可以将新的硬盘目录配置在这个参数中,重启Elasticsearch服务生效,创建索引时Elasticsearch目录选择的过程如下:
1)判断是否设置了path.data,没有时为默认路径;
2)获取所有的paths,默认最佳 path 是当前剩余空间最多的path;
3)遍历paths,过滤掉没有空间的path,若没有筛选出有剩余空间的path,则返回2)的path;
4)判断每个path下该索引的分片数,分片数少最小的path最终会被返回,当分片数相同,对path的所有索引分片总数,返回分片总数最少的索引,当这两个条件都相同,对剩余空间,返回剩余空间最大的path。
5)path.logs:日志存储目录;
修改path.data和path.logs 需要同步修改其他配置文件,该部分配置文件的修改将在后续1.2.2及1.2.3章节进行补充介绍。

图5 IP及端口配置
network.host:配置可访问此Elasticsearch集群的机器,如图5所示即为对所有完成网络打通的服务器均可见;
http.port:通过9200端口访问本服务器的Elasticsearch服务。

图6 集群节点ip及通信端口配置
transport.tcp.port:集群间节点的通信端口,配置不被其他服务的常驻进程推荐使用的端口即可;
discovery.seed_hosts:将所有加入Elasticsearch 集群的节点IP及端口配置到此列表中。

图7 其他变量配置
xpack.ml.enabled:设置false即可。
1.2.2系统安全配置文件修改
在指定path.data数据存储目录时,需要在/etc/security/limits.conf文件中补充可打开文件描述符(65536以上)及进程数(4096以上)参数,具体如下:
* soft nofile 65536
* hard nofile 65536
* soft nproc 4096
* hard nproc 40961.2.3 jvm.options配置文件修改
在指定 path.logs 日志存储目录时,需要修改 Elasticsearch安装目录下config文件夹下jvm.options的日志相关参数,否则会产生jvm找不到gc.log 文件告警,具体修改如图8红色框线所示。
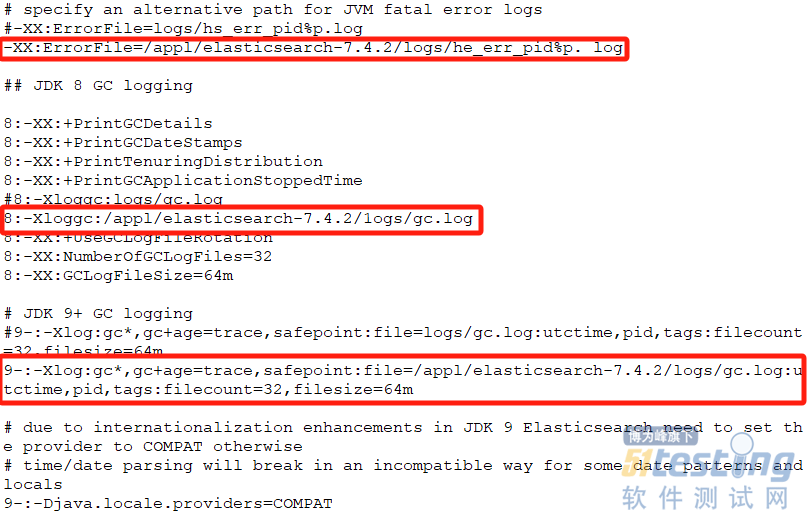
图8 jvm日志相关参数配置
jvm.options 中还有调整堆内存的参数,最大内存(Xmx)及最小内存(Xms)不能超过物理机总内存的50%,可根据物理机具体使用情况进行分配。
1.2.4 Elasticsearch 集群服务验证
在Elasticsearch安装目录下,使用命令:
./bin/elasticsearch
可以在控制台前台启动Elasticsearch服务,如图9信息表示服务成功启动。
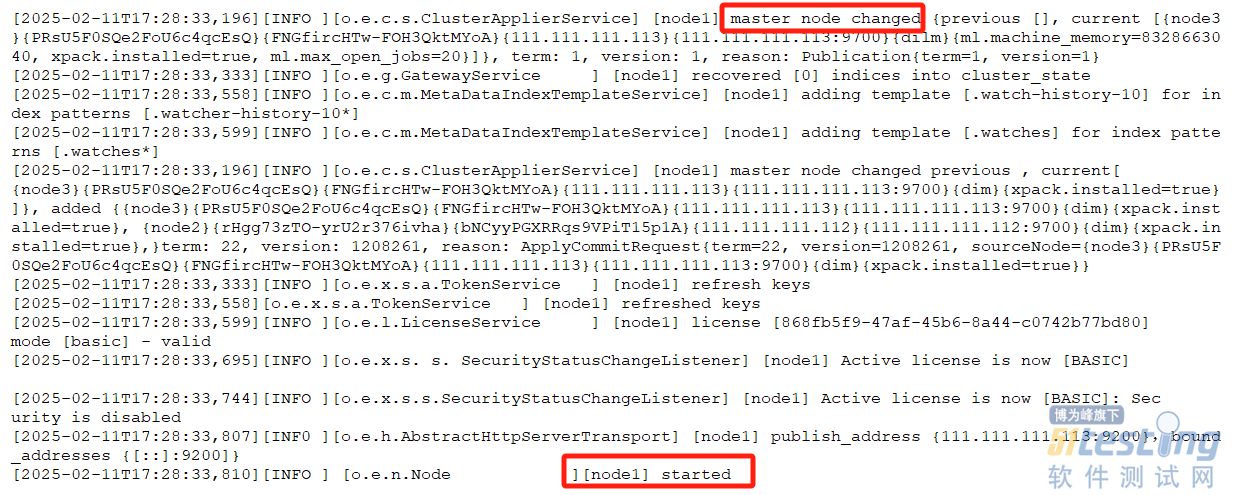
图9 Elasticsearch启动成功示例
第一部分红框显示管理节点的变化情况,第二部分红框表示当前服务器Elasticsearch正常启动服务。待验证成功后,可以结束当前进程,然后使用命令
./bin/elasticsearch -d
以守护进程的方式启动服务,保证在Elasticsearch作为后台进程提供稳定的数据服务。当所有节点的服务全部启动后,通过:
http://*.*.*.*:9200/_cat/nodes?v&h=http,version,jdk,disk.total,disk.used,disk.avail,disk.used_percent,heap.percent,master
查看当前集群的所有节点状态。

图10 Elasticsearch 集群状态
图10中disk表示硬盘空间,当总空间少时需考虑集群扩容,当剩余空间不足时应考虑数据清理。master列为*的行其对应的服务器为Elasticsearch集群依据算法推举产生的管理节点。
本文主要介绍了在ARM架构下,基于Logstash+Elasticsearch集群的搭建与部署,并结合我司日常数据处理需求及开发应用场景进行了深入的研究与探索,具体阐述了针对Logstash和ARM架构不兼容的问题做适配性优化,提供了生产运维中可能遇到问题的解决方案。
文末了:可以到我的个人号:atstudy-js
这里有10W+ 热情踊跃的测试小伙伴们,一起交流行业热点、测试技术各种干货,一起共享面试经验、跳槽求职各种好用的
欢迎加入 ↓ ↓ ↓
AI测试、 车载测试、自动化测试、银行、金融、游戏、AIGC...

















 1643
1643

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









