



SQL 执行顺序科普:揭开数据查询的神秘面纱
在数据驱动的时代,无论是企业管理庞大的客户信息,还是科研人员分析实验数据,SQL(Structured Query Language,结构化查询语言)都扮演着不可或缺的角色。它就像是数据库的 “翻译官”,能够让我们与存储着海量信息的数据库进行高效沟通。
一、SQL 是什么?
SQL 是一种专门用来与关系型数据库进行交互的标准语言,它允许用户以一种结构化、简洁的方式对数据库中的数据进行查询、插入、更新和删除等操作。关系型数据库将数据存储在由行和列组成的二维表中,表与表之间通过特定的关系相互关联。SQL 正是基于这种表结构,提供了一套统一的语法规则,使得不同的数据库系统(如 MySQL、Oracle、SQL Server 等)都能理解并执行相应的指令。通过 SQL,我们可以轻松从数据库中提取所需数据,对数据进行复杂的统计分析,确保数据的完整性和安全性。
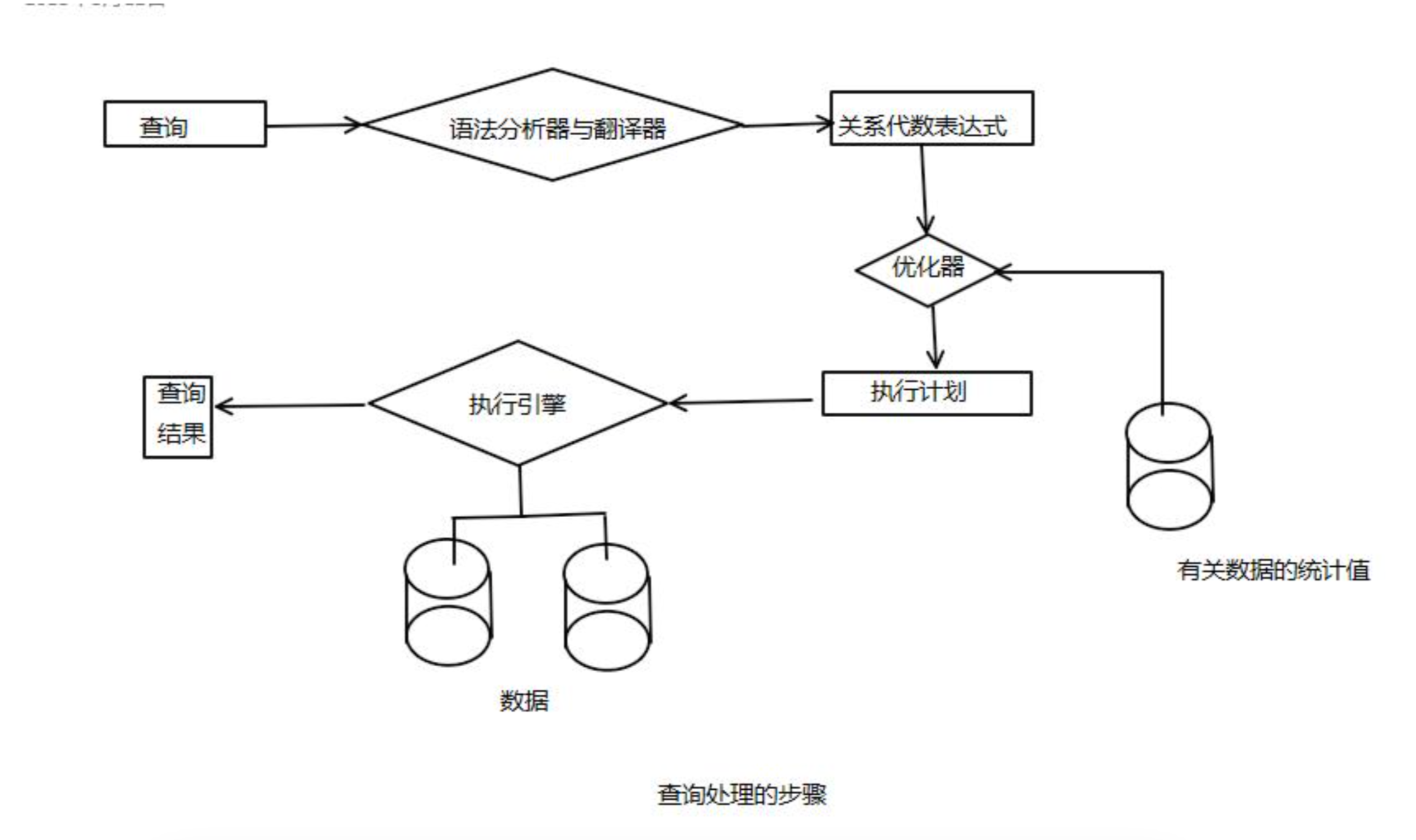
二、SQL 怎么用?
使用 SQL,首先需要连接到相应的数据库管理系统。可以通过数据库自带的客户端工具,如 MySQL Workbench、Oracle SQL Developer 等,或者通过编程语言(如 Python、Java 等)中的数据库连接库(如 Python 的pymysql、sqlite3)来建立连接。
连接成功后,就可以在客户端工具的查询窗口或编程语言的代码中编写 SQL 语句。例如,要从名为employees的表中查询所有员工的姓名和工资,可以使用以下 SQL 语句:
SELECT first_name, salary
FROM employees;
若要插入一条新员工记录到employees表中,可使用INSERT INTO语句:
INSERT INTO employees (first_name, last_name, salary, department_id)
VALUES ('John', 'Doe', 8000, 10);
通过不同的 SQL 语句组合,能够满足各种复杂的数据操作需求。
三、SQL 的执行顺序
在执行 SQL 语句时,尤其是包含多个子句(如SELECT、FROM、WHERE、GROUP BY、HAVING、ORDER BY等)的复杂查询,了解其执行顺序至关重要,这有助于优化查询性能和得到准确的结果。下面以常见的SELECT查询语句为例,详细介绍 SQL 的执行顺序:
- FROM 子句:这是 SQL 执行的起点。数据库首先会根据FROM子句指定的表名,找到对应的数据库表,并将这些表的数据加载到内存中。如果涉及多个表的连接(如JOIN操作),数据库会先根据连接条件将这些表进行关联。例如,执行SELECT * FROM orders JOIN customers ON orders.customer_id = customers.customer_id;,数据库会先将orders表和customers表按照customer_id进行连接操作。
- WHERE 子句:在表数据加载和连接完成后,数据库会执行WHERE子句。它会根据指定的过滤条件,逐行检查数据,筛选出符合条件的行,不符合条件的行将被排除,不会参与后续的计算。例如,SELECT * FROM employees WHERE department_id = 10;,数据库会从employees表中筛选出department_id等于 10 的所有行。
- GROUP BY 子句:当查询中包含GROUP BY子句时,数据库会将WHERE子句筛选后的结果按照指定的列进行分组。例如,SELECT department_id, AVG(salary) FROM employees WHERE department_id = 10 GROUP BY department_id;,数据库会将department_id为 10 的员工按照department_id分组,即使这里只有一组,也会进行分组操作。
- 聚合函数:分组完成后,数据库会对每个分组应用聚合函数(如SUM、AVG、COUNT等)进行计算。在上述示例中,会计算出department_id为 10 的员工的平均工资。
- HAVING 子句:HAVING子句用于对分组和聚合后的结果进行筛选。它的作用和WHERE子句类似,但WHERE子句作用于行数据,而HAVING子句作用于分组后的结果。例如,SELECT department_id, AVG(salary) FROM employees WHERE department_id = 10 GROUP BY department_id HAVING AVG(salary) > 5000;,会在计算出平均工资后,筛选出平均工资大于 5000 的分组。
- SELECT 子句:在经过前面的筛选和计算后,SELECT子句会从满足条件的结果集中选取指定的列。同时,它还会处理列的别名、表达式计算等操作。例如,SELECT first_name AS '名字', salary * 12 AS '年薪' FROM employees WHERE department_id = 10;,会将选取的列按照指定的别名显示,并计算出年薪。
- DISTINCT 关键字:如果SELECT子句中使用了DISTINCT关键字,它会去除结果集中重复的行,确保返回的每一行数据都是唯一的。例如,SELECT DISTINCT department_id FROM employees;,会返回employees表中不重复的department_id。
- ORDER BY 子句:最后,ORDER BY子句会根据指定的列对结果集进行排序,可以按照升序(ASC,默认)或降序(DESC)排列。例如,SELECT first_name, salary FROM employees WHERE department_id = 10 ORDER BY salary DESC;,会将department_id为 10 的员工按照工资从高到低进行排序。
了解 SQL 的执行顺序,不仅能帮助我们编写出更高效的查询语句,避免不必要的性能损耗,还能让我们在面对复杂的数据操作需求时,更加清晰地规划和构建 SQL 语句。随着数据量的不断增长,掌握 SQL 执行的底层逻辑将成为数据工作者的一项核心技能。

















 1635
1635

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









