




 本文介绍了一个线上接口监控报警平台的升级过程,从echarts+js+springboot展示方式升级为prometheus+Grafana,更好地满足了业务部门的需求。文章详细讨论了方案选择、架构原理及遇到的问题。
本文介绍了一个线上接口监控报警平台的升级过程,从echarts+js+springboot展示方式升级为prometheus+Grafana,更好地满足了业务部门的需求。文章详细讨论了方案选择、架构原理及遇到的问题。
一、背景
去年我们工具组开发了ams线上接口监控报警平台,开发该平台的目的是为了能够让用户没发现问题的时候,通过钉钉报警和可视化的方式让我们内部人员(开发、测试)提前知道哪个接口或哪个服务中的链路出问题了,然后快速处理掉,及时止损,这种守住最后一道防线的方式,目前取得了不错的效果。
同时该平台也实现了对线上接口监控指标的可视化展示,分为两类:一类是实时展示的监控指标;一类是展示统计性的监控指标。实时监控指标如图:
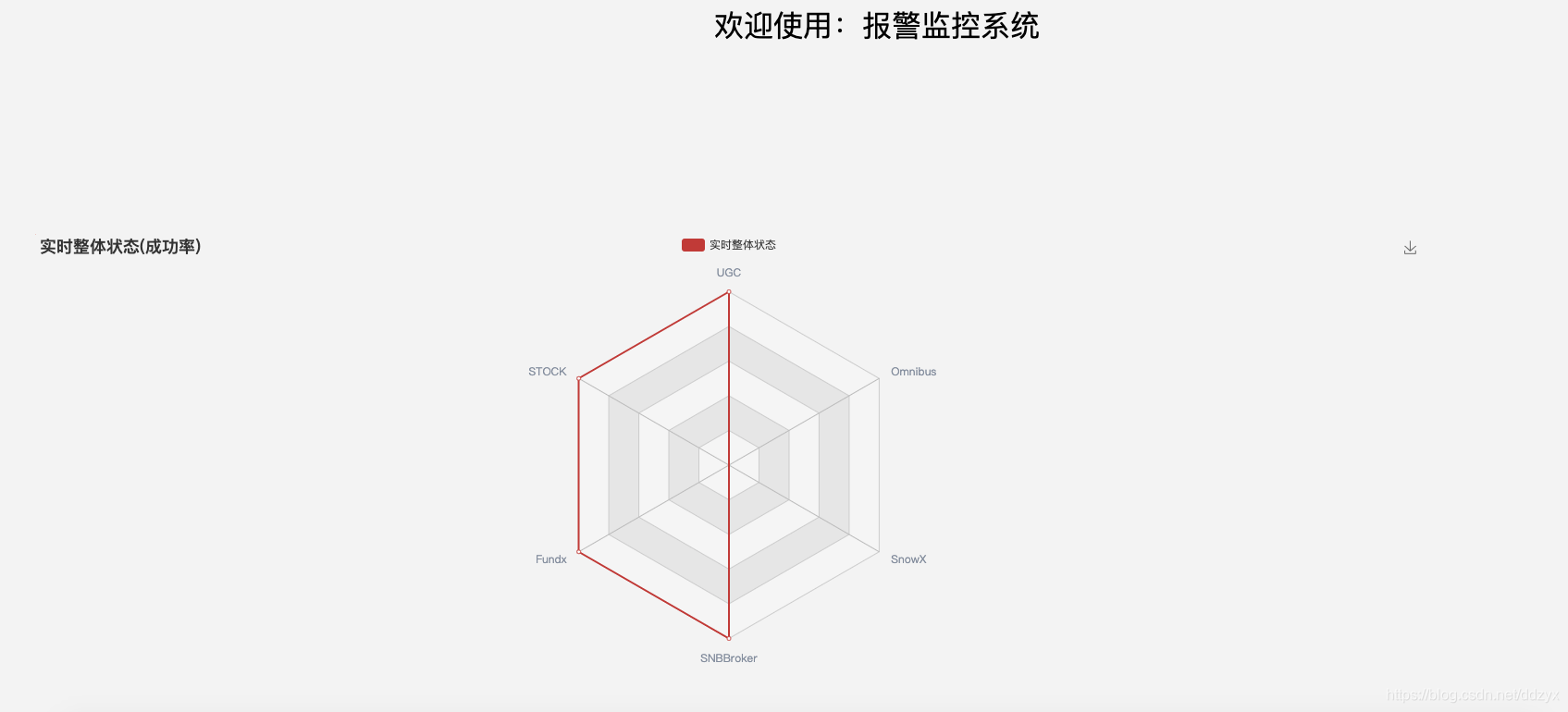


但是监控数据的可视化方案在需求设计时考虑有些欠缺:
1、当时组内因为任务多、时间紧,我们没有对各个部门进行详细的需求调研(只是根据我们过往的经验自己总结的需求来设计的方案),导致指标监控这块与业务部门的需求有出入。
2、监控数据的可视化代码实现是基于echart+js+springboot实现的,使用echart画的饼状图、柱状图、折线图,表现形式不如专业监控工具展现的好,如Grafana监控视图。
二、需求
重新调研公司各部门的需求,整理如下:
1、把旧的echart+js+springboot形式展示改为prometheus+Grafana进行展示,选用表现形式更好的专业监控工具进行展现;
2、监控指标根据业务部门关注的指标进行监控;
以下是各部门关注的监控指标:
a, 证券(业务部门1)
响应时间
返回状态码
用例执行结果
可定制化的字段
监控项目本身的报警
屏蔽接口统计中的产品字段
b, 财富(业务部门2)
响应时间
返回状态码
返回业务码
接口返回的数据包大小
c,社区(业务部门3)
全链路接口响应时间
3、监控指标数据需要固化下来,方便以后回溯。
三、方案选型:
通过调研,我们总结了2套可实现方案:
方案一(被动模式):
自定义exporter,prometheus agent去请求调用项目,项目处理逻辑:先自定义sql去查库,然后按照自定义的exporter数据格式去处理数据,处理成metrics指标数据,然后把处理完的数据写入缓存,等待prometheus来pull metrics数据,最后集成Grafana进行展示。
方案二(主动模式):
我们开发的后端自动化测试框架一轮一轮的在后台定时的去跑测试case,每跑一条case得出的结果,经过逻辑计算处理,使用java Client SDK Push 数据到 PushGateway ,使用 PushGateway 数据上报的方式,等待prometheus来pull metrics数据,最后集成Grafana进行展示。
最后根据我们实际的业务需求,最终选择方案二作为我们的开发实现方案。
我们选择方案二的理由基于以下考虑:
1、虽然prometheus提供了pull的方式来收集数据,可能由于子网络或者防火墙的原因,不能直接拉取各个 Target 的指标数据,运维成本比push方式高。
2、监控业务数据时,需要将不同数据汇总,然后由prometheus统一收集,这是PushGateway最大的优势,也是结合我们自己的实际开发需求来选择的方案。
3、pushgateway可以持久化推送给它的所有监控数据,这也是我们实际开发的需求,需要把监控数据固化下来,方便以后查问题回溯。
四、架构&工作原理
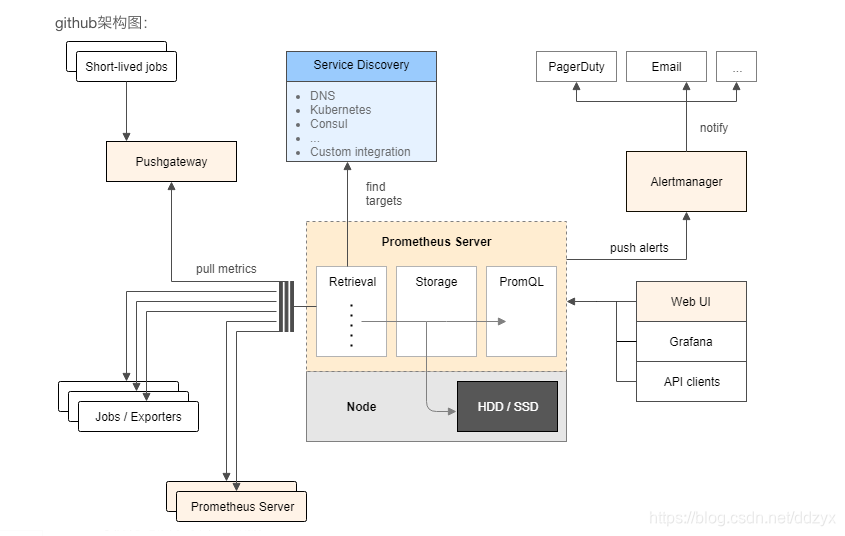
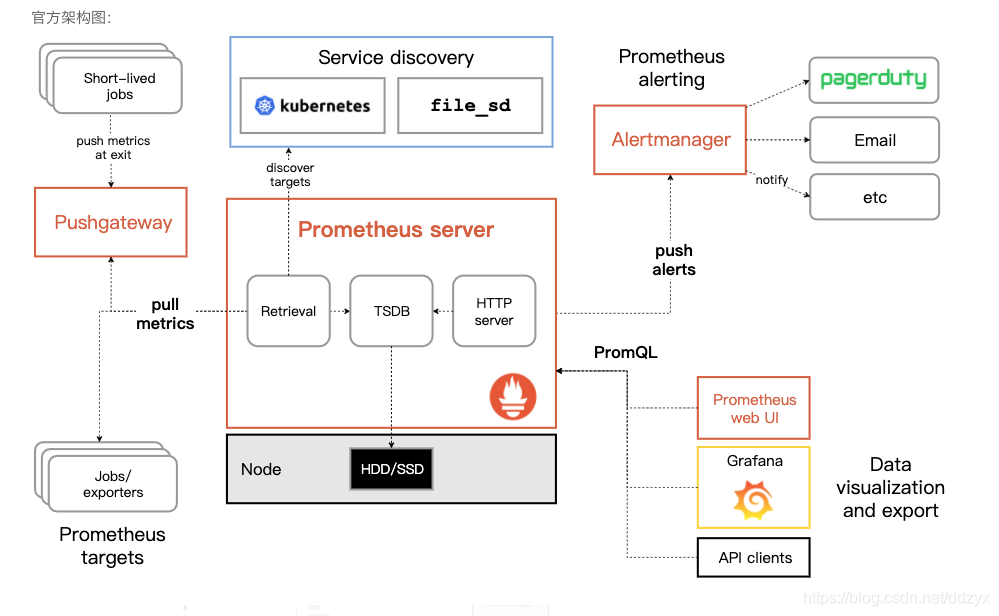
Prometheus服务,可以直接通过目标拉取数据,或者间接地通过中间网关拉取数据。它在本地存储抓取的所有数据,并通过一定规则进行清理和整理数据,并把得到的结果存储到新的时间序列中,Grafana和其他API可视化地展示收集的数据
Prometheus的基本原理是通过HTTP协议周期性抓取被监控组件的状态,任意组件只要提供对应的HTTP接口就可以接入监控。不需要任何SDK或者其他的集成过程。这样做非常适合做虚拟化环境监控系统,比如VM、Docker、Kubernetes等。输出被监控组件信息的HTTP接口被叫做exporter 。目前互联网公司常用的组件大部分都有exporter可以直接使用,比如Varnish、Haproxy、Nginx、MySQL、Linux系统信息(包括磁盘、内存、CPU、网络等等)。
Prometheus服务过程大概是这样:
Prometheus Daemon负责定时从静态配置的 targets 或者服务发现的 targets 上抓取metrics(指标)数据,每个抓取target需要暴露一个http服务的接口给它定时抓取。Prometheus支持通过配置文件、文本文件、Zookeeper、Consul、DNS SRV Lookup等方式指定抓取目标。Prometheus采用PULL的方式进行监控,即服务器可以直接通过目标PULL数据或者间接地通过中间网关来Push数据。
Prometheus新拉取的数据大于配置内存缓存区的时候,会将抓取的数据持久化到本地磁盘(如果使用 remote storage 将持久化到云端)。并通过一定规则进行清理和整理数据,把得到的结果存储到新的时间序列中。
Prometheus通过PromQL和其他API可视化地展示收集的数据。Prometheus支持很多方式的图表可视化,例如Grafana、自带的Promdash以及自身提供的模版引擎等等。Prometheus还提供HTTP API的查询方式,自定义所需要的输出。
PushGateway支持Client主动推送metrics到PushGateway,而Prometheus只是定时去Gateway上抓取数据。
Prometheus 可以配置 rules,然后定时查询数据,当条件触发的时候,会将 alert 推送到配置的 Alertmanager。
Alertmanager是独立于Prometheus的一个组件,可以支持Prometheus的查询语句,提供十分灵活的报警方式。Alertmanager 收到警告的时候,可以根据配置,聚合,去重,降噪,最后发送警告。
Pushgateway是prometheus的一个重要组件,利用该组件可以实现自动以监控指标,从字面意思来看,该部件不是将数据push到prometheus,而是作为一个中间组件收集外部push来的数据指标,prometheus会定时从pushgateway上pull数据。

pushgateway并不是将Prometheus的pull改成了push,它只是允许用户向他推送指标信息,并记录。而Prometheus每次从 pushgateway拉取的数据并不是期间用户推送上来的所有数据,而是client端最后一次push上来的数据。因此需设置client端向pushgateway端push数据的时间小于等于prometheus去pull数据的时间,这样一来可以保证prometheus的数据是最新的。
【注意】如果client一直没有推送新的指标到pushgateway,那么Prometheus获取到的数据是client最后一次push的数据,直到指标消失(默认5分钟)。
Prometheus本身是不会存储指标的,但是为了防止pushgateway意外重启、工作异常等情况的发送,在pushgateway处允许指标暂存,参数–persistence.interval=5m,默认保存5分钟,5分钟后,本地存储的指标会删除。
prometheus将获取到的数据存入TSDB,一款时序型数据库。此时prometheus已经获取到了监控数据,可以使用内置的PromQL进行查询。
它的报警功能使用Alertmanager提供,Alertmanager是prometheus的告警管理和发送报警的一个组件。
图表展示将prometheus数据接入grafana,由grafana进行统一管理。
五、metric
prometheus采集到的监控数据均以metric(指标)形式保存在时序数据库中(TSDB)
每一条时间序列由 metric 和 labels 组成,每条时间序列按照时间的先后顺序存储它的样本值。
默认情况下各监控client向外暴露一个HTTP服务,prometheus会通过pull方式获取client的数据,数据格式如下:
# HELP node_cpu Seconds the cpus spent in each mode.
# TYPE node_cpu counter node_cpu{cpu="cpu0",mode="idle"} 362812.7890625
# HELP node_load1 1m load average.
# TYPE node_load1 gauge node_load1 3.0703125
以#开头的表示注释信息,解释了每一个指标的监控目的和类型
node_cpu表示监控指标的名称
{}内的内容是标签,以键值对的方式记录
数字是这个指标监控的数据
指标(metric)的格式如下:
<metric name>{<label name>=<label value>, ...}
指标名称反映的是监控了什么。
标签反映的是样本的维度,可以理解成指标的细化。比如:
api_http_requests_total{method="POST", handler="/messages"}
指标是“api_http_requests_total”,含义是通过api请求的http总数。
标签“method=“POST”” “handler=”/messages""代表了这些http请求中 POST 请求 并且 handler是/messages的数量
上述指标等同于:
{__name__="api_http_requests_total",method="POST", handler="/messages"}
指标有四种类型
Counter
Counter用于累计值,例如记录请求次数、任务完成数、错误发生次数。一直增加,不会减少。重启进程后,会被重置。
例如:http_response_total{method=”GET”,endpoint=”/api/tracks”} 100,10秒后抓取http_response_total{method=”GET”,endpoint=”/api/tracks”} 100。
Counter 表示收集的数据是按照某个趋势(增加/减少)一直变化的,我们往往用它记录服务请求总量、错误总数等。
例如 Prometheus server 中 http_requests_total, 表示 Prometheus 处理的 http 请求总数。
Gauge
Gauge常规数值,例如 温度变化、内存使用变化。可变大,可变小。重启进程后,会被重置。
例如: memory_usage_bytes{host=”master-01″} 100 < 抓取值、memory_usage_bytes{host=”master-01″} 30、memory_usage_bytes{host=”master-01″} 50、memory_usage_bytes{host=”master-01″} 80 < 抓取值。
Gauge 表示搜集的数据是一个瞬时的值,与时间没有关系,可以任意变高变低,往往可以用来记录内存使用率、磁盘使用率等。
例如 Prometheus server 中 go_goroutines, 表示 Prometheus 当前 goroutines 的数量。
Histogram
Histogram(直方图)可以理解为柱状图的意思,常用于跟踪事件发生的规模,例如:请求耗时、响应大小。它特别之处是可以对记录的内容进行分组,提供count和sum全部值的功能。
例如:{小于10=5次,小于20=1次,小于30=2次},count=7次,sum=7次的求和值。
Histogram 由 _bucket{le=“”},_bucket{le=“+Inf”}, _sum,_count 组成,主要用于表示一段时间范围内对数据进行采样(通常是请求持续时间或响应大小),并能够对其指定区间以及总数进行统计,通常它采集的数据展示为直方图。
例如 Prometheus server 中 prometheus_local_storage_series_chunks_persisted, 表示 Prometheus 中每个时序需要存储的 chunks 数量,我们可以用它计算待持久化的数据的分位数。
Summary
Summary和Histogram十分相似,常用于跟踪事件发生的规模,例如:请求耗时、响应大小。同样提供 count 和 sum 全部值的功能。
例如:count=7次,sum=7次的值求值。
它提供一个quantiles的功能,可以按%比划分跟踪的结果。例如:quantile取值0.95,表示取采样值里面的95%数据。
Summary 和 Histogram 类似,由 {quantile=“<φ>”},_sum,_count 组成,主要用于表示一段时间内数据采样结果(通常是请求持续时间或响应大小),它直接存储了 quantile 数据,而不是根据统计区间计算出来的。
例如 Prometheus server 中 prometheus_target_interval_length_seconds。
Histogram vs Summary
- 都包含 _sum,_count Histogram 需要通过 _bucket
- 计算 quantile, 而 Summary 直接存储了 quantile 的值。
六、安装部署监控体系(PushGateway+Prometheus+Grafana+Alertmanager)
1、docker方式搭建
安装方法网上很多。我们这次使用docker安装,比较简便。
安装过程如下:
git clone https://github.com/evnsio/prom-stack.git cd prom-stack docker-compose pull && docker-compose up -d

可以看到docker-compose已经成功启动了
可以使用docker-compose ps命令查看各个服务使用的端口

grafana可以使用默认用户名密码 admin password 登陆
测试使用curl生成测试数据
可以使用$RANDOM来生成随机数
while true; do echo “mymetric $RANDOM” | curl --data-binary @- http://localhost:9091/metrics/job/my-push-job sleep 1 done
"mymetric"就是这个被监控的指标,这个监控指标推送到pushgateway比较简洁直观的
操作效果如下
在浏览器里打开pushgateway: “http://127.0.0.1:9091/”

可以看到测试的数据已经进入pushgateway了

在浏览器里打开prometheus: “http://127.0.0.1:9090/”
搜索metric名称,可以查看prometheus从pushgateway拉取的数据,如上图。
在grafana配置可视化界面
配置从prometheus里获取监控数据
在浏览器里打开这个grafana地址:http://127.0.0.1:3000/datasources/new 配置好prometheus监控数据服务器的地址

查看操作结果

创建监控数据展示页面

选择graph类型的展示效果

点击"Panel Title"选择Edit

在查询参数处使用这个条件
alert_gauge{department=“STOCK”,instance=“alert_gauge_rt_instance”,job=“alert_gauge_rt_job”,level=“0”,project=“stock-api”,uri=“/v5/stock/ah/compare.json”}
查询出这个第一步生成的用来测试的监控数据

然后点击保存按钮就可以生成图表了

2、二进制包方式搭建
二进制方式搭建,就是把各个组件的二进制包下载下来进行本地安装,这里就不详细介绍了。
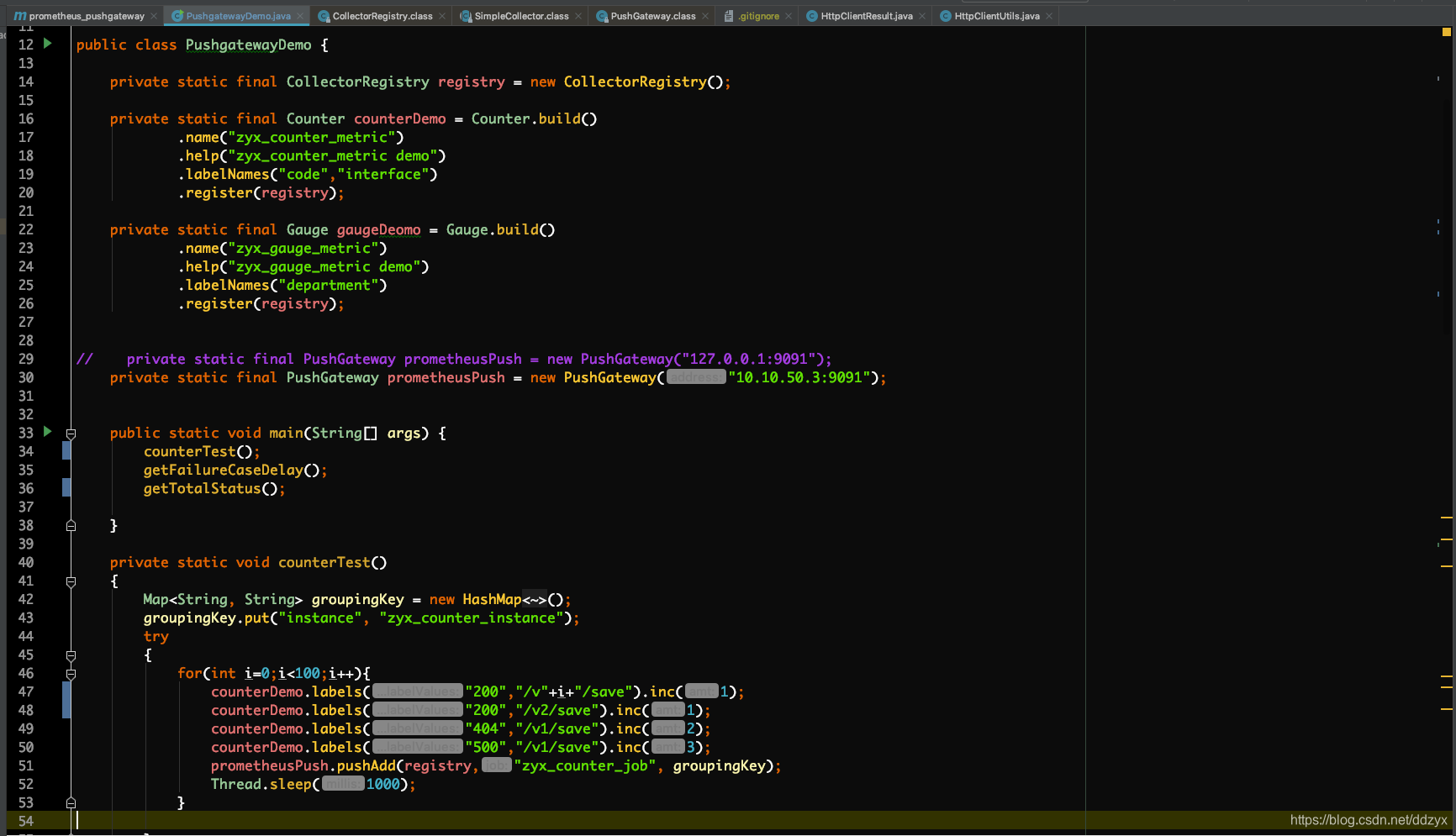
六、开发java sdk与PushGateway集成
使用Client SDK向Pushgateway推数据
通过Client SDK推送metric信息到Pushgateway:
1.添加pom依赖:
io.prometheus
simpleclient_pushgateway
0.6.0
2.添加配置:在Prometheus的配置文件中配置,让其从Pushgateway上进行数据采集,这里10.51.14.23:9091为我Pushgateway的地址端口。配置完后需要重启使其配置生效
scrape_configs:
- job_name: ‘pushgateway’
static_configs: - targets: [‘10.51.14.23:9091’]
labels:
instance: “pushgateway”
3.代码:
demo:
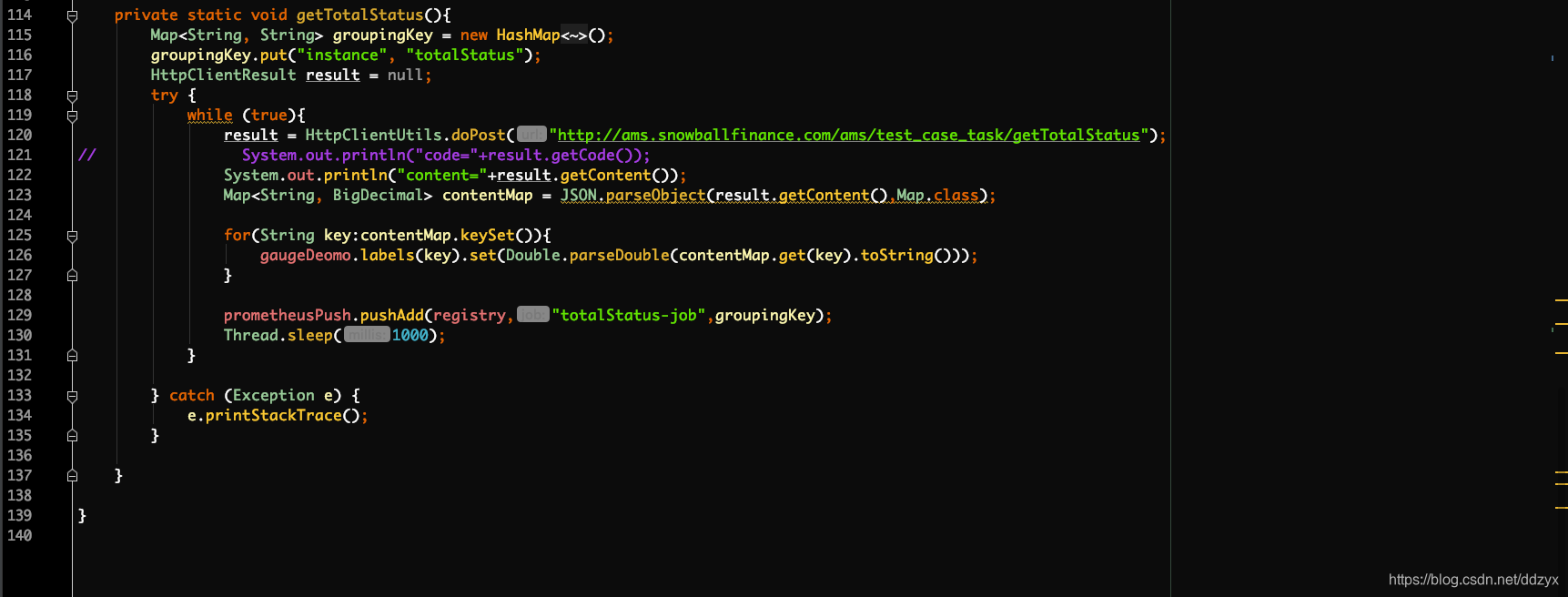
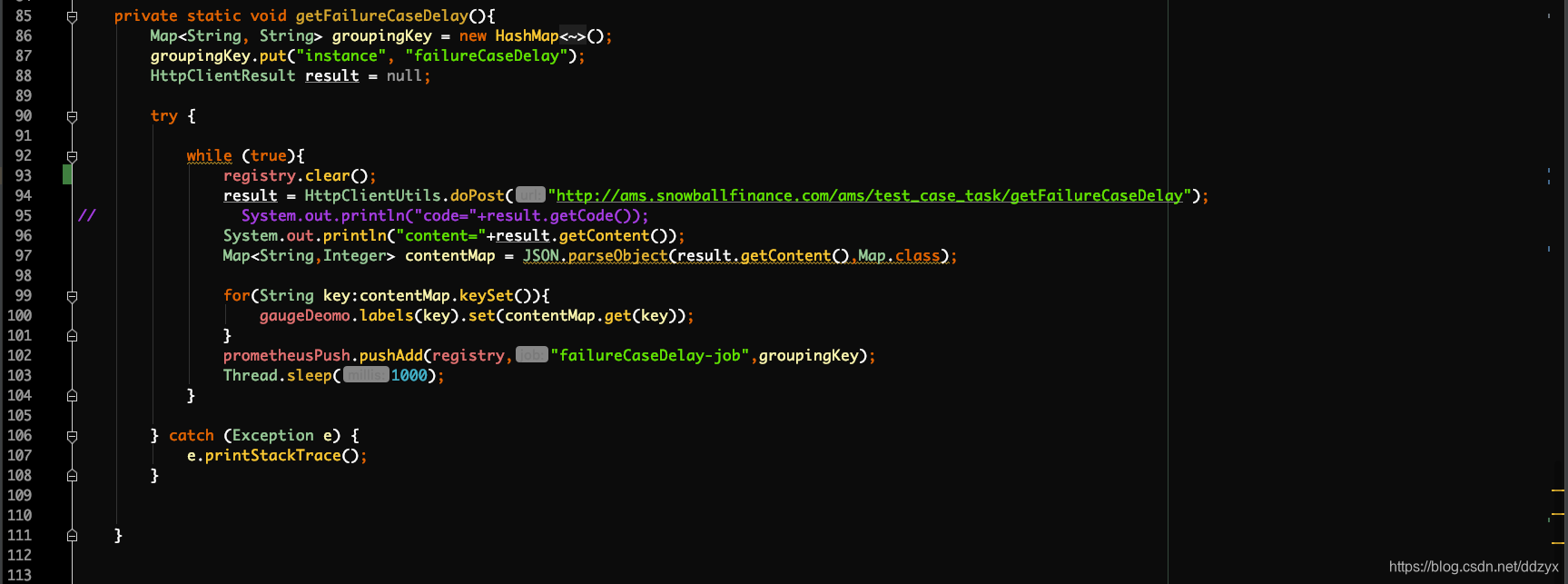
七、踩的坑
1、docker-compose up -d时grafana无法启动出现如下报错:
[root@localhost grafana]# docker-compose logs -f grafana
Attaching to grafana_grafana_1
grafana_1 | GF_PATHS_DATA=‘/var/lib/grafana’ is not writable.
grafana_1 | You may have issues with file permissions, more information here: http://docs.grafana.org/installation/docker/#migration-from-a-previous-version-of-the-docker-container-to-5-1-or-later
grafana_1 | mkdir: cannot create directory ‘/var/lib/grafana/plugins’: Permission denied
grafana_grafana_1 exited with code 1
原因:grafana_data目录权限不足。
解决办法:chown 472:472 grafana_data -R
2、收集数据本身的 job 和 instance 被覆盖
问题
推送给Pushgateway的instance和job全部加了"exported_"前缀,instance=“gateway”,job=“pushgateway”
现象:myCounter{exported_instance=“instance1”,exported_job=“some_job”,instance=“gateway”,job=“pushgateway”}
原因: 收集数据本身的 job 和 instance 被覆盖。
因为 Prometheus 配置 pushgateway 的时候,也会指定 job 和 instance, 但是它只表示 pushgateway 实例,不能真正表达收集数据的含义。所以在 prometheus 中配置 pushgateway 的时候,需要添加 honor_labels: true 参数,
从而避免收集数据本身的 job 和 instance 被覆盖。
解决方案: 添加 honor_labels: true
···
job_name: ‘pushgateway’
honor_labels: true
static_configs:
targets: [‘127.0.0.1:9091’]
labels:
instance: gateway
···
然后重启Prometheus
3、每轮中各个业务线的测试周期不固定,有的业务线每3分钟跑一次,有的业务线自动化case每隔半小时跑一次,导致图表实时展示时出现很长的直线,不符合预期。
原因:因为如果一直没有新数据推给pushgateway的话,prometheus拉取的数据一直是sdk最后一次推的数据,也就是旧的数据,所以会导致很长的直线。
解决方案:
a、每个业务线跑完数据后实时地由pushgateway推送,pushgateway推送完后删除该metric;
b、prometheus的拉取时间间隔缩短至最小,改为10s拉一次;
c、数据存储由原来的pushgateway端存储改为prometheus存储,由prometheus固化到磁盘;
d、修改prometheus数据存储(保留)时间为1个月;
4、docker prometheus因为权限问题报错,启不起来
原因:由于prometheus权限的特殊性,它新建的目录和文件都是nobody用户权限和nogroup用户组权限的,而在宿主机建对应的目录或文件的权限一般是root或者user权限,所以prometheus docker会因为权限不一致起不来。如下图:

解决方法:使宿主机上对应的目录或文件的权限都跟prometheus的权限一致,对应起来就好了。(经验之谈)

八、效果
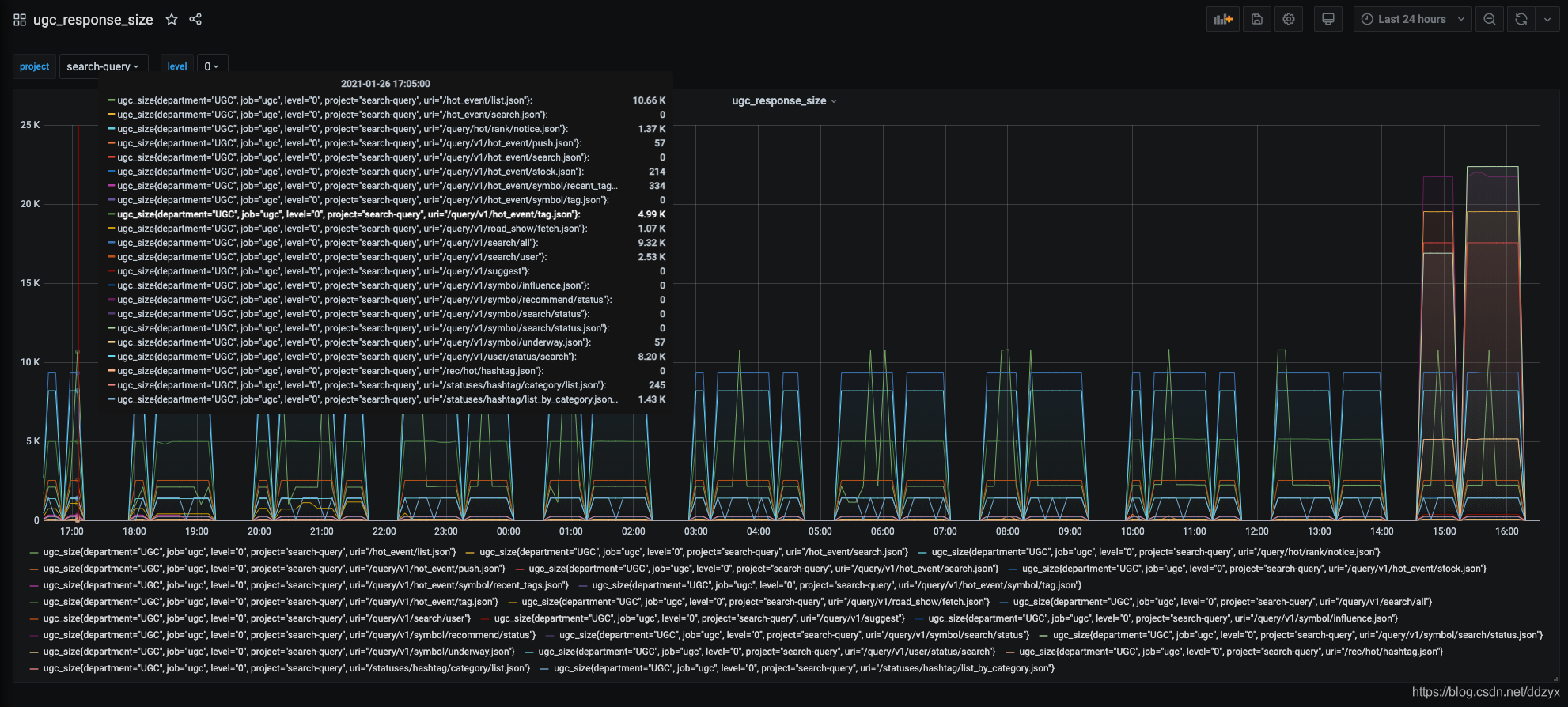
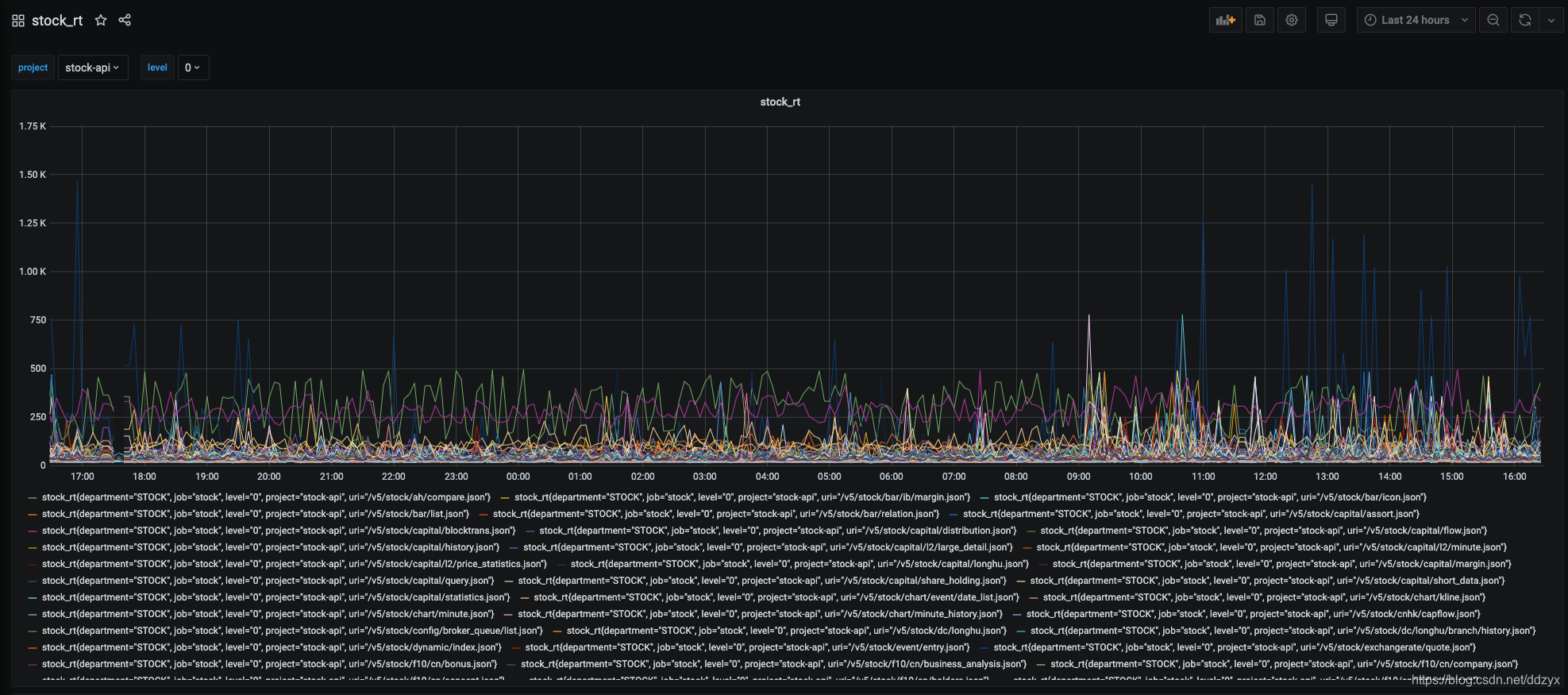
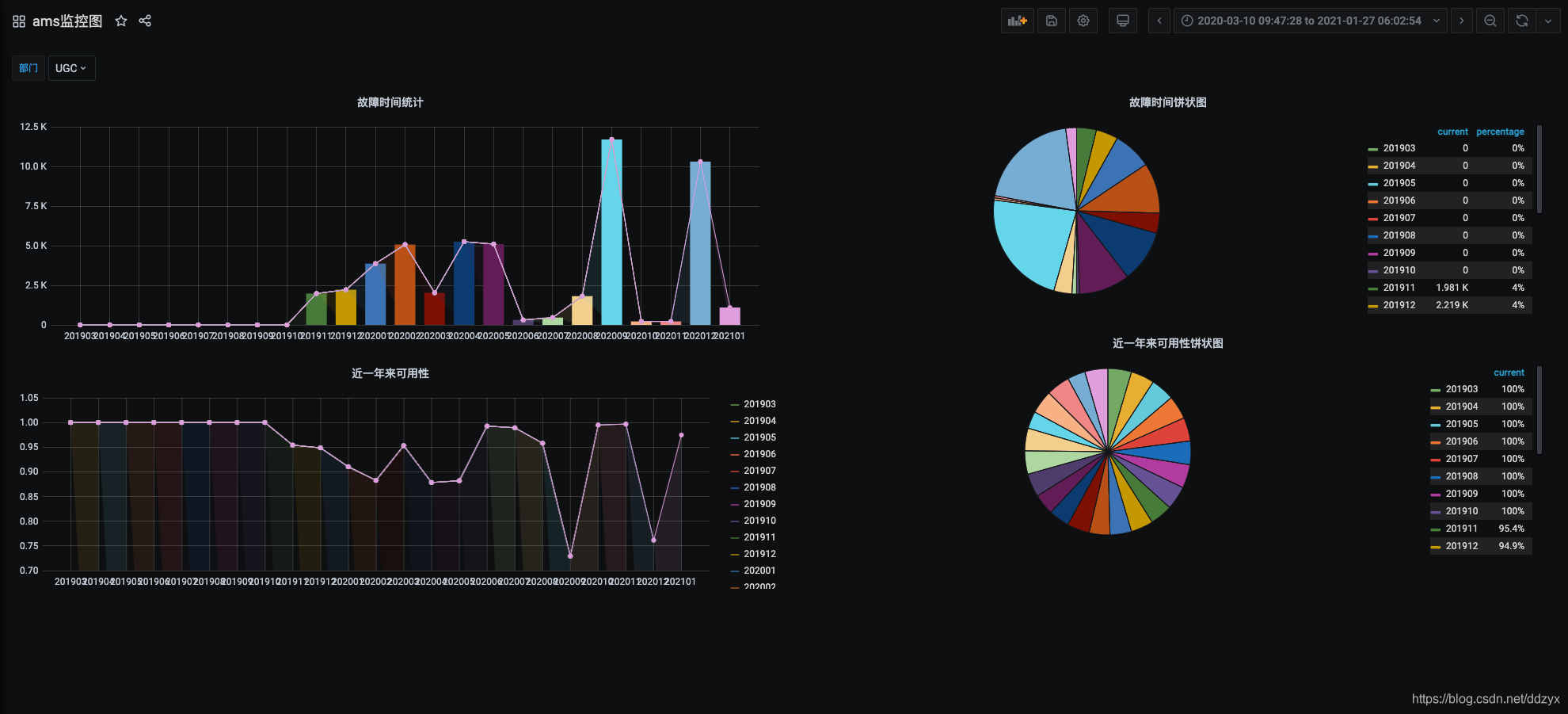
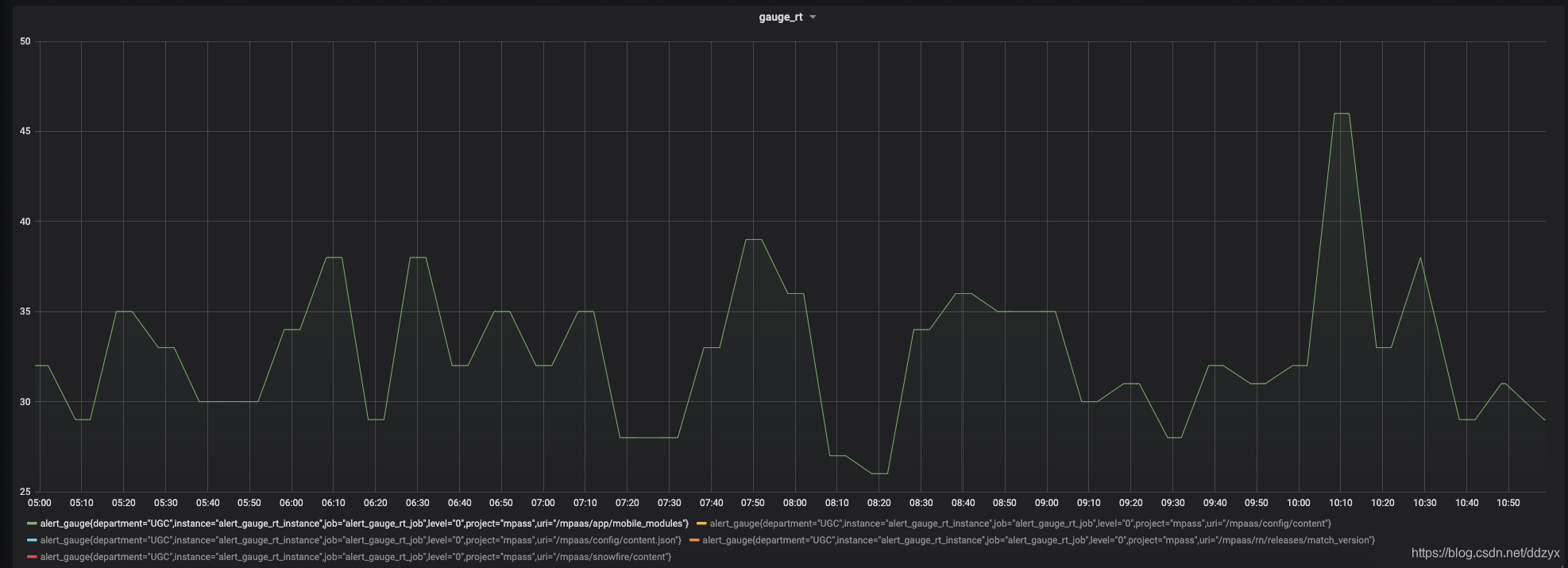
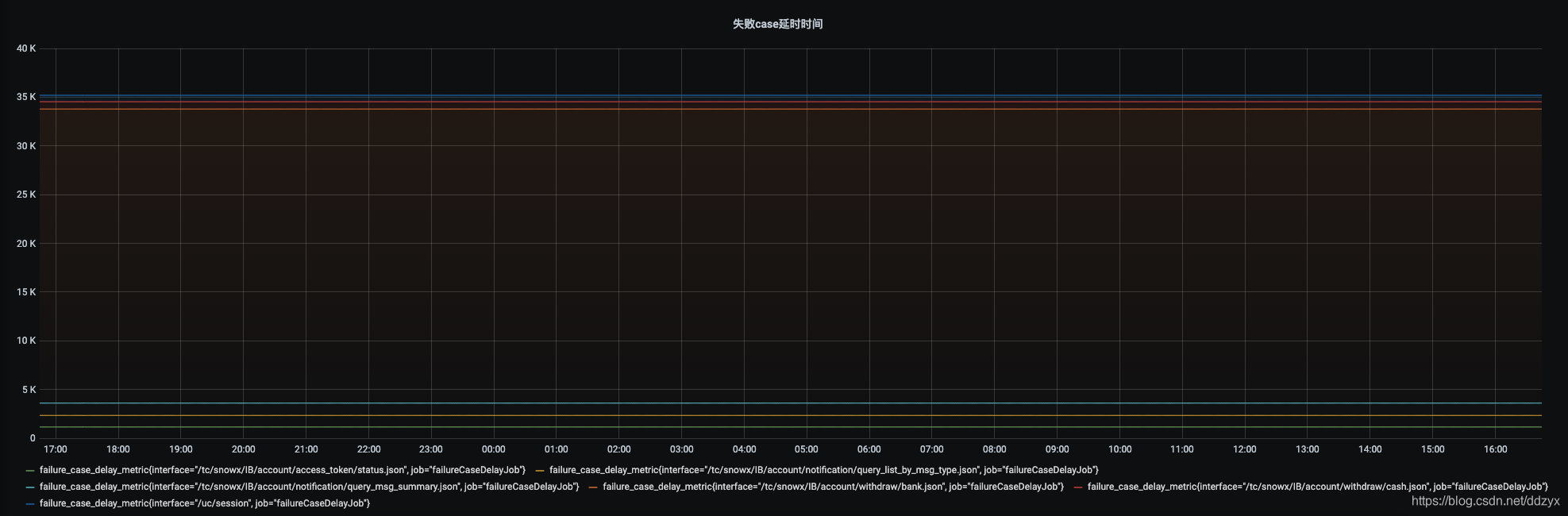
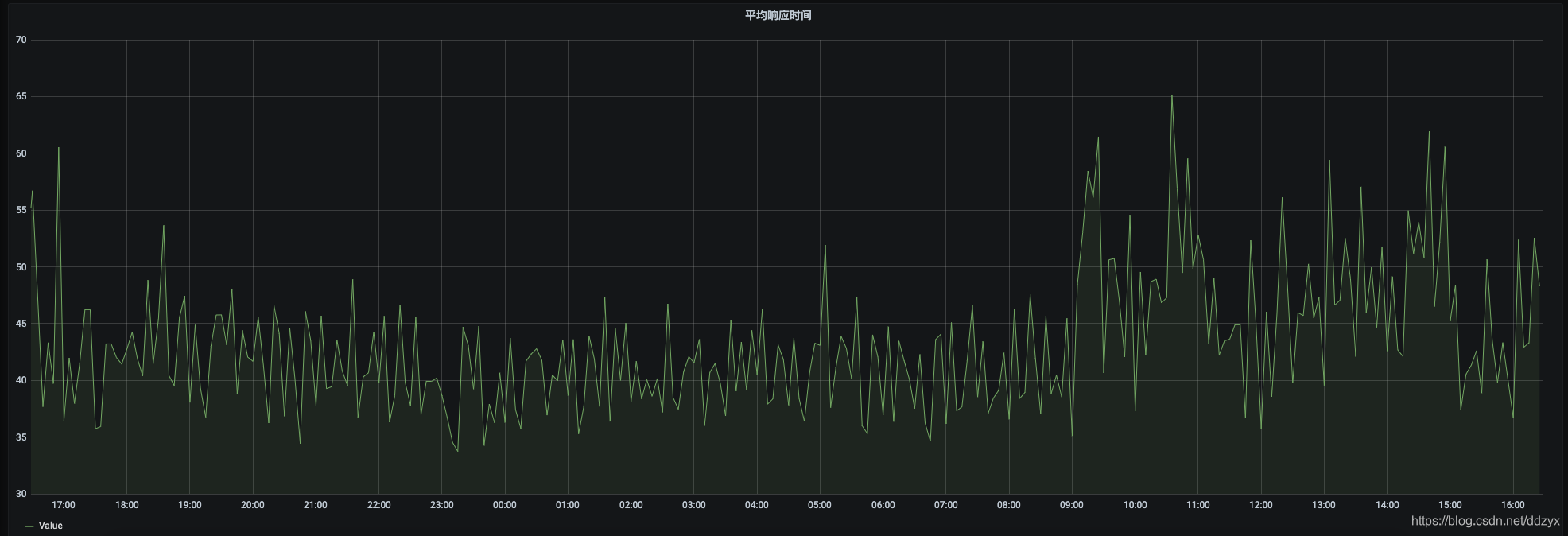
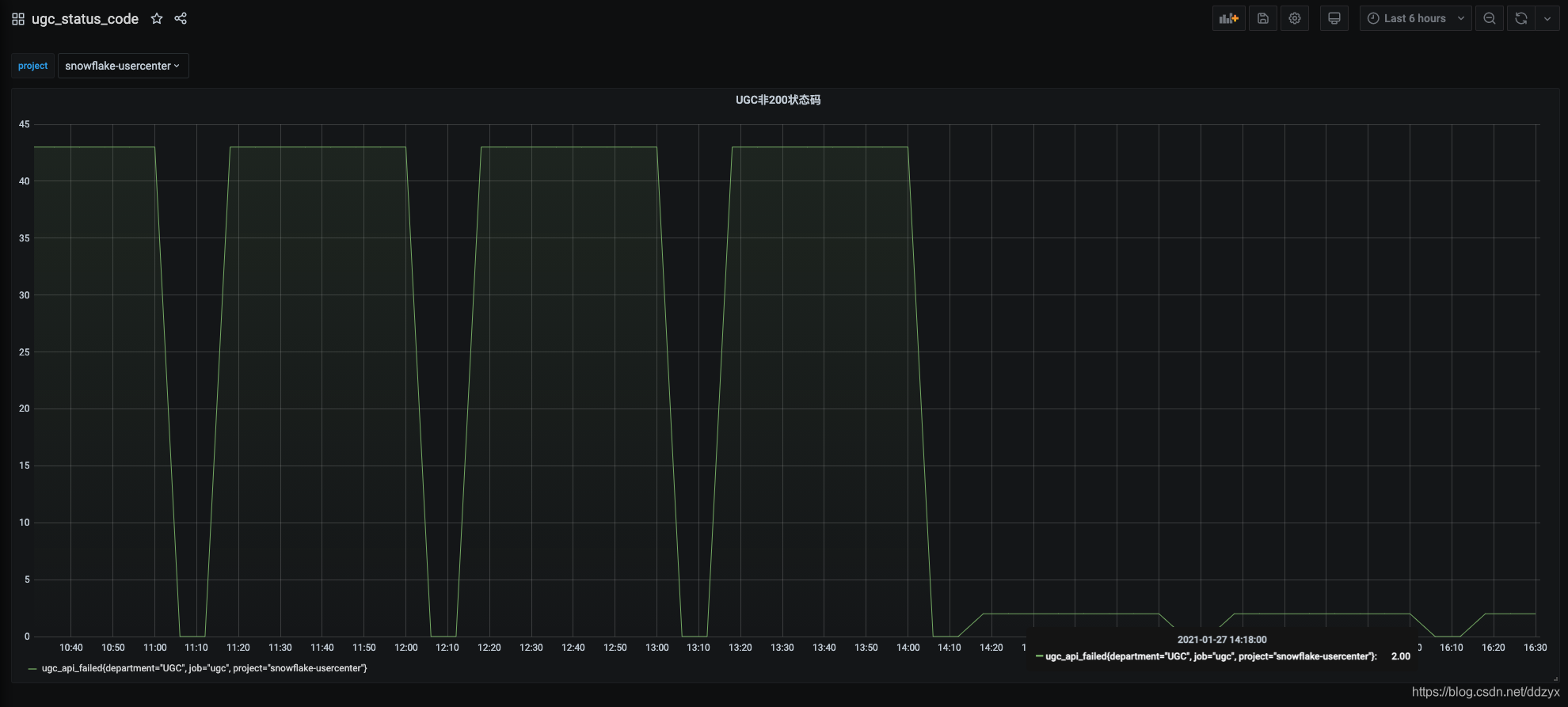
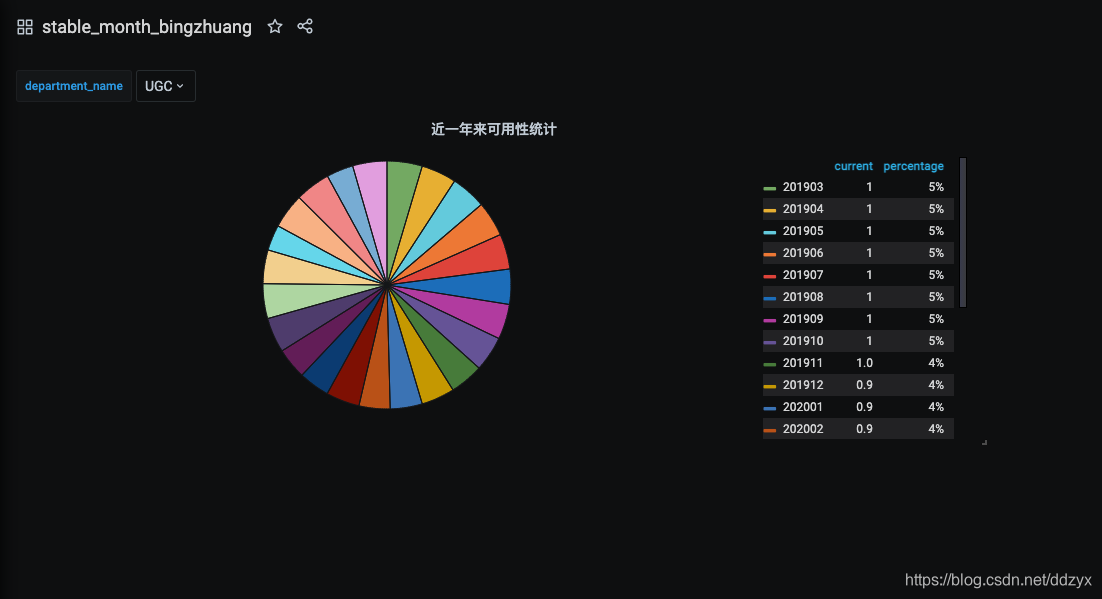
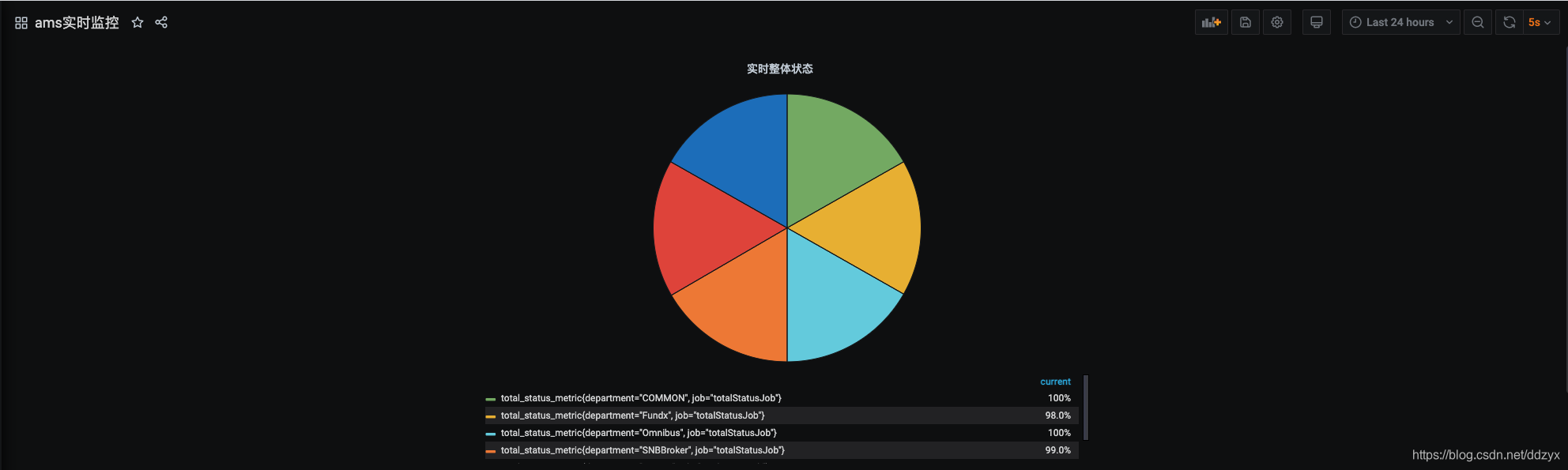
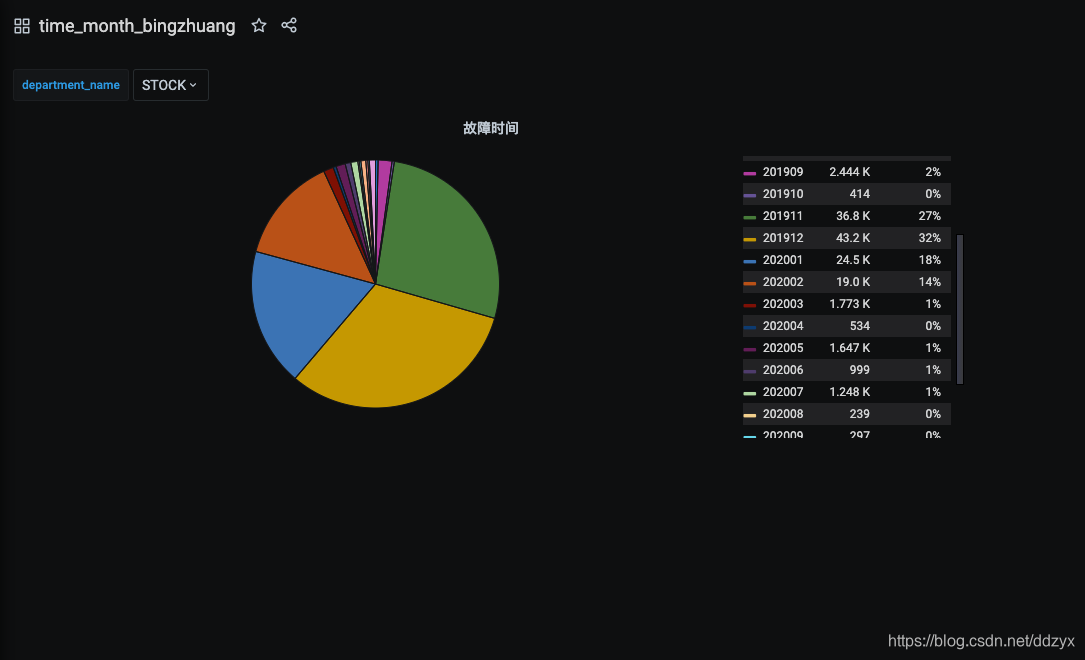
九、总结


















 209
209

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









