







 本文详细解读Spark独立集群中Worker和Executor的概念,阐述它们的角色区别:Worker作为硬件容器,提供CPU和内存资源;Executor是执行任务的应用程序,有特定的资源需求。当资源配置不当,可能导致任务无法执行或集群资源浪费。
本文详细解读Spark独立集群中Worker和Executor的概念,阐述它们的角色区别:Worker作为硬件容器,提供CPU和内存资源;Executor是执行任务的应用程序,有特定的资源需求。当资源配置不当,可能导致任务无法执行或集群资源浪费。
.
(一)Spark独立集群Worker和Executor的概念
1.1 Worker(容器)
工作节点,相当于工作站,一台虚拟的计算机,有自己的CPU核心数,内存数。
我们把Worker假设成一台计算机,那么CPU核心数(假设2核),内存数(假设32GB)就是它的硬件条件。
实际上在Spark里面是这些配置决定的:
export SPARK_WORKER_CORES=2
export SPARK_WORKER_MEMORY=32g
1.2 Executor(程序)
工作程序,相当于计算机上运行的一个程序,有它要求CPU核心数,要求的内存数。
我们把Executor假设成一个程序,那么它需要运行在计算机上,它它对CPU核心数(假设1核),内存数(假设4GB),就是它运行的基本要求。
PS:同理driver也是个程序。
我们提交时可以指定这些参数:
SparkLauncher aL = new org.apache.spark.launcher.SparkLauncher()
.setXXX(...)
.setConf(SparkLauncher.DRIVER_MEMORY, "4g")
.setConf(SparkLauncher.EXECUTOR_MEMORY,"4g")
.setConf(SparkLauncher.EXECUTOR_CORES,"1")
1.3 无法满足条件的Worker不工作
如果EXECUTOR_MEMORY,EXECUTOR_CORES参数指定超过了某些Worker的配置,
则这些Work不会参加到这个任务的计算中。
如果EXECUTOR_MEMORY,EXECUTOR_CORES参数指定超过了全部Worker的配置,
那么集群中就没有资源可以供这个任务使用了,任务会无限等待下去,等待可用资源。
每个worker可以配置多个CPU核心,一定量的内存。
根据主机实际情况进行配置,比如我这里:
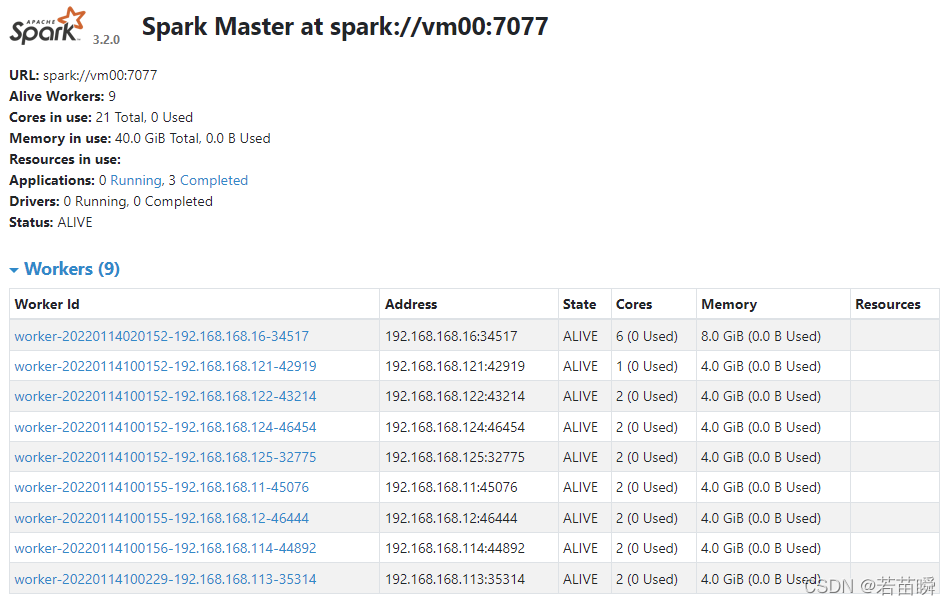
💎这不是问题,只是个概念。
.

















 674
674

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









