







1.操作题需求
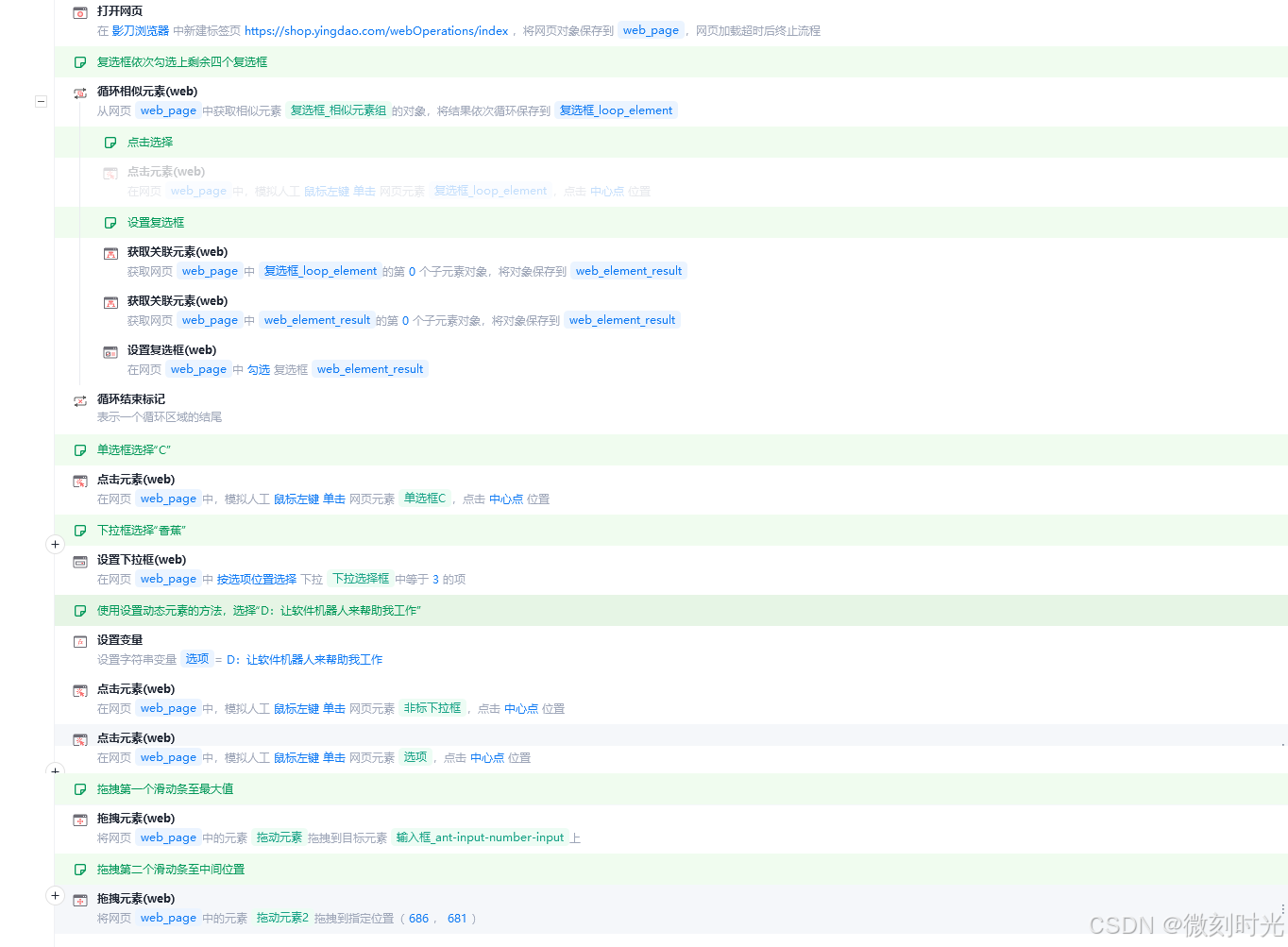
按要求实现以下流程: 1. 进入影刀商城 — 网页操作页面,网址 影刀商城 账号:admin 密码:58T2$!hm 2. 复选框依次勾选上剩余四个复选框 3. 单选框选择“C” 4. 下拉框选择“香蕉” 5. 使用设置动态元素的方法,选择“D:让软件机器人来帮助我工作” 6. 拖拽第一个滑动条至最大值 7. 拖拽第二个滑动条至中间位置
2.实战代码
2.1 打开网页

2.2 复选框依次勾选上剩余四个复选框
可以依次捕获复选框元素,通过点击元素实现,这里使用循环相似元素组实现
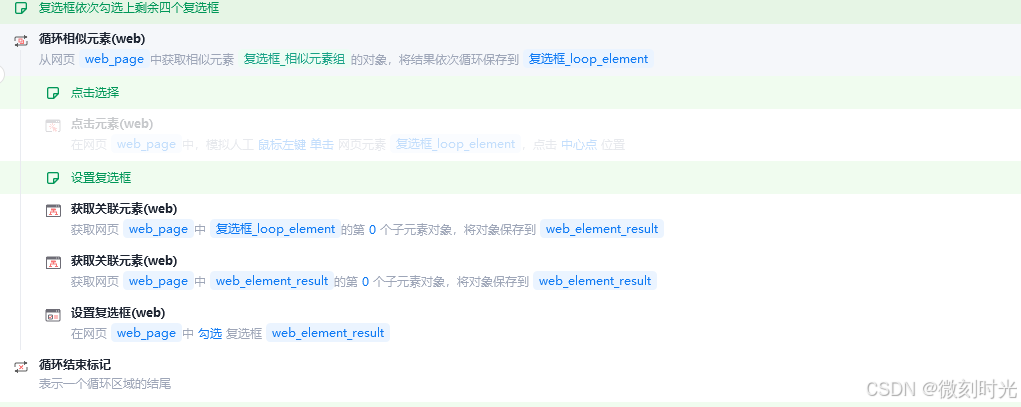
2.3 单选框选择“C”

2.4 下拉框选择“香蕉”

2.5 使用设置动态元素的方法选择

2.6 拖拽元素

这个作业还是比较简单的,都是基础指令操作。
整体代码
3.知识点
- 网页元素复选框
- 网页元素单选
- 网页元素下拉选择,非标准下拉框选择,主要是非标准下拉框,很多网站都是这种网页布局
- 网页元素拖拽
4.最后
感谢大家,请大家多多支持。


















 2320
2320

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











