




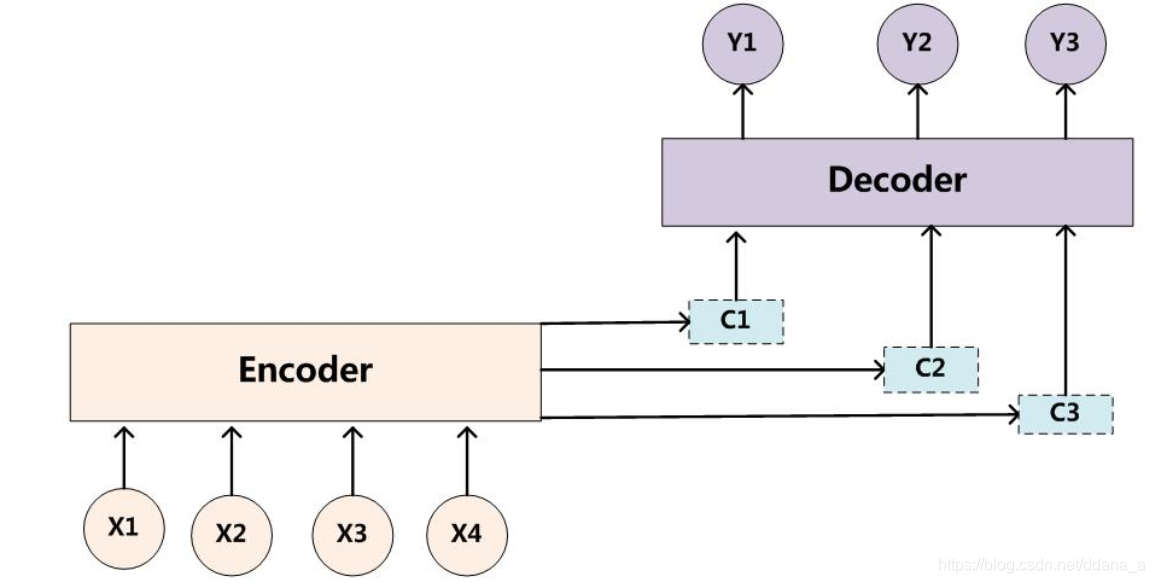
1.Encoder-Decoder模型及RNN的实现
encoder-decoder模型虽然非常经典,但是局限性也非常大。最大的局限性就在于编码和解码之间的唯一联系就是一个固定长度的语义向量C。也就是说,编码器要将整个序列的信息压缩进一个固定长度的向量中去。但是这样做有两个弊端,一是语义向量无法完全表示整个序列的信息,还有就是先输入的内容携带的信息会被后输入的信息稀释掉,或者说,被覆盖了。输入序列越长,这个现象就越严重。这就使得在解码的时候一开始就没有获得输入序列足够的信息, 那么解码的准确度自然也就要打个折扣了.这种固定长度的上下文矢量设计的一个关键和明显的缺点是系统无法记住更长的序列。一旦处理完整个序列,通常会忘记序列的早期部分。注意机制的诞生是为了解决这个问题。
2.Attention模型
为了解决这个问题,作者提出了Attention模型,或者说注意力模型。简单的说,这种模型在产生输出的时候,还会产生一个“注意力范围”表示接下来输出的时候要重点关注输入序列中的哪些部分,然后根据关注的区域来产生下一个输出,如此往复。模型的大概示意图如下所示
相比于之前的encoder-decoder模型,attention模型最大的区别就在于它不在要求编码器将所有输入信息都编码进一个固定长度的向量之中。相反,此时编码器需要将输入编码成一个向量的序列,而在解码的时候,每一步都会选择性的从向量序列中挑选一个子集进行进一步处理。这样,在产生每一个输出的时候,都能够做到充分利用输入序列携带的信息。而且这种方法在翻译任务中取得了非常不错的成果。
用于翻译任务的结构。解码部分使用了attention模型,而在编码部分,则使用了BiRNN(bidirectional RNN,双向RNN)
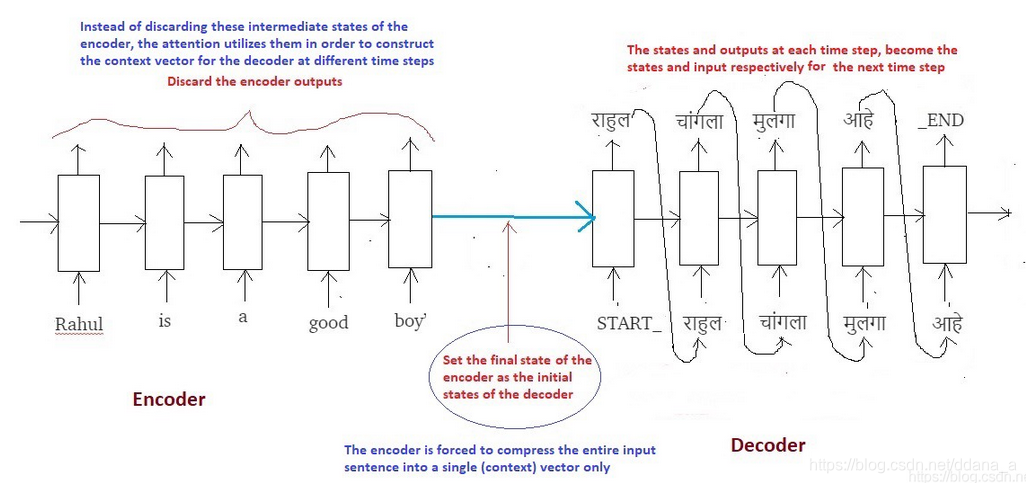
在传统的Seq2Seq模型中,我们丢弃编码器的所有中间状态,并仅使用其最终状态(向量)来初始化解码器。该技术适用于较小的序列,但随着序列长度的增加,单个载体成为瓶颈,并且很难将长序列汇总到单个载体中。这种观察是凭经验进行的,因为注意到随着序列尺寸的增加,系统的性能急剧下降。
注意力背后的核心思想不是抛弃那些中间编码器状态,而是利用所有状态以构造解码器生成输出序列所需的上下文向量
让我们将编码器的每个中间状态命名为:
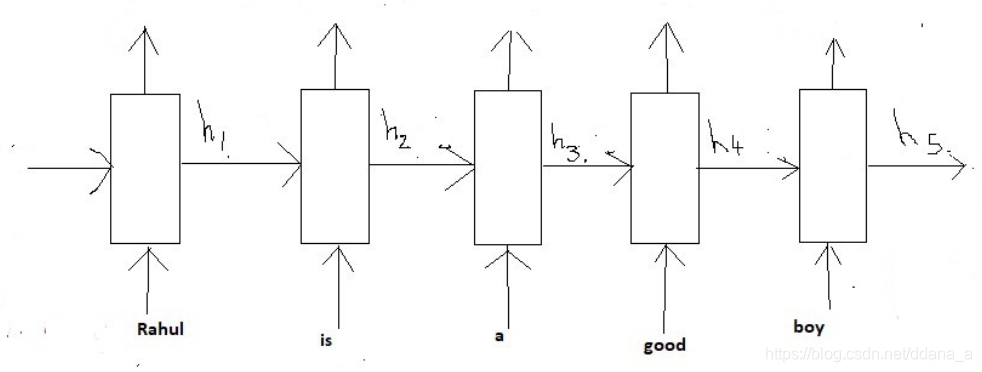
这些状态(h1到h5)只不过是固定长度的矢量。为了发展一些直觉,可以将这些状态视为在序列中存储局部信息的向量。例如;h1存储序列开头的信息(像’Rahul’和’is’这样的单词),而h5存储序列后面部分的信息(像’good’和’boy’这样的单词.
现在的想法是集体利用所有这些本地信息,以便在解码目标句子时决定下一个序列。
在我们开始解码之前,我们首先需要将输入序列编码为一组内部状态(在我们的例子中为h1,h2,h3,h4和h5)。
现在的假设是,输出序列中的下一个字取决于解码器的当前状态(解码器也是GRU)以及编码器的隐藏状态。因此,在每个时间步,我们考虑这两件事,并按照以下步骤:
步骤1 - 计算每个编码器状态的分数
由于我们预测第一个字本身,因此解码器没有任何当前的内部状态。出于这个原因,我们将编码器的最后状态(即h5)视为先前的解码器状态。
现在使用这两个组件(所有编码器状态和解码器的当前状态),我们将训练一个简单的前馈神经网络学习通过为要关注的状态生成高分来识别相关的编码器状态,同时为要忽略的状态的低分获得。
设s1,s2,s3,s4和s5是相应地为状态h1,h2,h3,h4和h5生成的分数。由于我们假设我们需要更多地关注状态h1和h2并忽略h3,h4和h5以便预测“राहुल”,我们期望上述神经元产生得分,使得s1和s2高,而s3,s4和s5相对较低。
步骤2-计算注意力权重
一旦生成了这些分数,我们对这些分数应用softmax以产生如上所示的注意权重e1,e2,e3,e4和e5。应用softmax的优点如下:
a)所有权重介于0和1之间,即0≤e1,e2,e3,e4,e5≤1b)
所有权重总和为1,即e1 + e2 + 3 + e4 + e5 = 1
因此,我们得到了注意力量的一个很好的概率解释。
在我们的例子中,我们期望如下的值:(仅用于直觉)
e1 = 0.75,e2 = 0.2,e3 = 0.02,e4 = 0.02,e5 = 0.01
这意味着在预测单词“राहुल”时,解码器需要更多地关注状态h1和h2(因为e1和e2的值很高)而忽略状态h3,h4和h5(因为e3的值, e4和e5非常小)
步骤3-计算上下文向量
一旦我们计算了注意力权重,我们就需要计算解码器将使用的上下文向量(思维向量),以便预测序列中的下一个单词。计算方法如下:
context_vector = e1 * h1 + e2 * h2 + e3 * h3 + e4 * h4 + e5 * h5
显然,如果e1和e2的值高并且e3,e4和e5的值低,则上下文向量将包含来自状态h1和h2的更多信息以及来自状态h3,h4和h5的相对更少的信息.
步骤4-将上下文向量与前一时间步的输出连接
最后,解码器使用以下两个输入向量来生成序列中的下一个字
a)上下文向量
b)从前一时间步骤生成的输出字。
我们简单地连接这两个向量并将合并的向量馈送到解码器。
步骤5-解码器输出
解码器然后生成序列中的下一个字(在这种情况下,期望生成“राहुल”)并且与输出一起,解码器还将生成内部隐藏状态,并将其称为“d1”。
注意,与传统Seq2Seq模型的情况下用于所有解码器时间步长的固定上下文向量不同,这里在注意的情况下,我们通过每次计算注意权重来为每个时间步计算单独的上下文向量。
因此,使用这种机制,我们的模型能够在输入序列的不同部分和输出序列的相应部分之间找到有趣的映射。
使用LSTM层代替GRU并在编码器上添加双向lstm也有助于提高性能.
注意机制的唯一缺点是它非常耗时且难以并行化系统。为了解决这个问题,谷歌大脑提出了“Transformer Model”,它只使用了注意力并摆脱了所有的卷积和循环层,从而使其具有高度可并行化和计算效率。
Encoder-Decoder模型和Attention模型
最新推荐文章于 2025-08-01 13:55:01 发布
 本文深入探讨了Encoder-Decoder模型及其RNN实现的局限性,并详细介绍了Attention机制如何解决这些问题。通过生成注意力权重,模型能更好地利用输入序列信息,提高了翻译等任务的准确性。
本文深入探讨了Encoder-Decoder模型及其RNN实现的局限性,并详细介绍了Attention机制如何解决这些问题。通过生成注意力权重,模型能更好地利用输入序列信息,提高了翻译等任务的准确性。

















 394
394

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









