




0前言
本人计算机研二,专业带队数学建模,长期更新建模教学,有需要的同学欢迎讨论~
本篇文章,本系列学长讲解一部分数学建模常用算法,会陆续更新每个算法的详细实现和使用教程
1 ID3算法概述
ID3算法的核心是在决策树各个结点上对应信息增益准则选择特征,递归地构建决策树。
具体方法是:从根结点(root node)开始,对结点计算所有可能的特征的信息增益,选择信息增益最大的特征作为结点的特征,由该特征的不同取值建立子节点;再对子结点递归地调用以上方法,构建决策树;直到所有特征的信息增益均很小或没有特征可以选择为止,最后得到一个决策树。ID3相当于用极大似然法进行概率模型的选择。
2 递归终止的条件:
(1)所有类的标签完全相同,则直接返回该类标签。
(2)使用完所有即当前属性集为空,仍不能将数据集划分成仅包含唯一类别的分组,则挑选出现次数最多的类别作为返回值。
3 使用案例
3.1 数据集描述
共分为四个属性特征:年龄段,有工作,有自己的房子,信贷情况; 现根据这四种属性特征来决定是否给予贷款 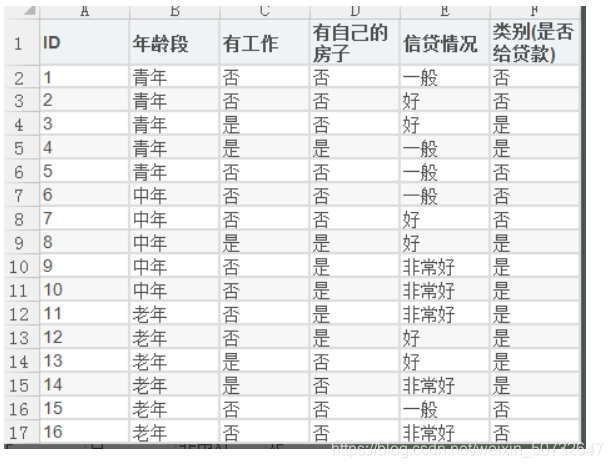
为了方便,我对数据集进行如下处理:在编写代码之前,我们先对数据集进行属性标注。
- (0)年龄:0代表青年,1代表中年,2代表老年;
- (1)有工作:0代表否,1代表是;
- (2)有自己的房子:0代表否,1代表是;
- (3)信贷情况:0代表一般,1代表好,2代表非常好;
- (4)类别(是否给贷款):no代表否,yes代表是。
存入txt文件中:
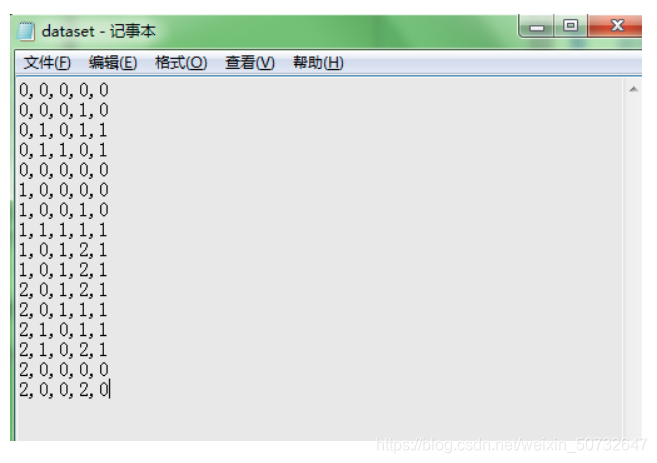
然后分别利用ID3,C4.5,CART三种算法对数据集进行决策树分类;
数据集的读取:
def read_dataset(filename):
"""
年龄段:0代表青年,1代表中年,2代表老年;
有工作:0代表否,1代表是;
有自己的房子:0代表否,1代表是;
信贷情况:0代表一般,1代表好,2代表非常好;
类别(是否给贷款):0代表否,1代表是
"""
fr = open(filename,'r')
all_lines = fr.readlines() ## list形式,每行为1个str
#print(all_lines)
labels = ['年龄段','有工作','有自己的房子','信贷情况']
dataset = []
for line in all_lines[0:]:
line = line.strip().split(',') #以逗号为分割符拆分列表
dataset.append(line)
return dataset,labels
dataset,labels = read_dataset('./data/dataset.txt')
print(dataset,labels)

3.2 计算信息熵

def inforEntropy(dataset):
m = len(dataset) #数据集的长度
labelCounts = {
} #给所有可能分类创建字典
for featvec in dataset:
currentlabel = featvec[-1] #获取当前样本的label
if currentlabel not in labelCounts.keys():
labelCounts[currentlabel] = 0
labelCounts[curren 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 320
320

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









