




本文来自《老饼讲解-BP神经网络》https://www.bbbdata.com/
交叉熵、信息熵概念基本贯穿了机器学习、深度学习中的类别识别模型,例如KL分布、softmax等等都是基于交叉熵与信息熵的理论进行定义的,本文不妨形象梳理一下什么是交叉熵、信息熵,以此一通百通。
一、信息量
1.1.什么是信息量
信息量是对信息的一种量化指标,用于衡量信息的大小,最常用的是香农信息量,香农信息量的定义与计算公式如下:
h
(
x
)
=
−
ln
(
p
(
x
)
)
h(x)=−\ln(p(x))
h(x)=−ln(p(x))
其中,p是事件x发生的概率,h则为事件x所包含的香农信息量。
从式中可以看到,事件的香农信息量与事件的概率成反比,

即一件事发生的概率越小,则包含的信息量越大
二、什么是信息熵
2.1.什么是信息熵
信息熵通俗来说就是信息量的期望,香农信息熵则是香农信息量的期望
如果已知 x 有 n 种取值,且知道每种取值的概率,则 x 的香农信息熵如下:
H
(
x
)
=
−
∑
i
n
p
(
x
i
)
ln
p
(
x
i
)
\displaystyle H(x) = -\sum\limits_{i}^{n}p(x_i)\ln p(x_i)
H(x)=−i∑np(xi)lnp(xi)
2.2. 信息熵的意义
为什么要单独把"信息量的期望"单独拎出来命名为"信息熵"呢?因为信息熵是一个常用的概念,例如用信息熵来评估事件的混沌程度,当我们对一个事件越不确定时,即越混沌时,在得知该事件的确切值时期望获得的信息量就越多,即事件越混沌,事件的信息熵就越大:
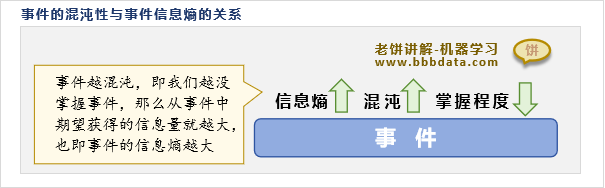
因此,一般可用信息熵来评估一个事件的混沌程度,或者我们对事件的掌握程度
三、交叉熵
3.1.什么是交叉熵
如果已知 X 有 n 种取值,我们认为第 i 种取值的概率为
q
(
x
i
)
q(x_i)
q(xi),事实上第i种取值的概率为
p
(
x
i
)
p(x_i)
p(xi),则定义在知道X的真实取值时所获得的信息量期望为交叉熵
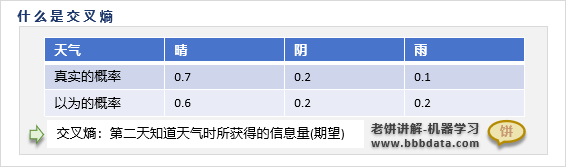
香农交叉信息熵的公式如下:
C
(
p
,
q
)
=
−
∑
i
n
p
(
x
i
)
ln
q
(
x
i
)
\small \displaystyle C(p,q) = -\sum\limits_{i}^{n}p(x_i)\ln q(x_i)
C(p,q)=−i∑np(xi)lnq(xi)
3.2.如何理解交叉熵的意义
交叉熵经常用于评估概率模型的预测效果的准确程度,交叉熵越小,说明模型越准确
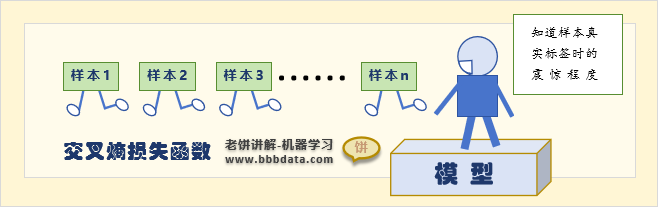
为什么交叉熵越小,模型就越准确呢?
因为交叉熵就是知道X的真实取值时所获得的信息量期望,交叉熵越小,说明信息量越小。
模型的交叉熵越小(知道真实标签时的信息量小),那说明基于模型我们已经基本掌握了样本的标签类别信息了。
相关链接:
《老饼讲解-机器学习》:老饼讲解-机器学习教程-通俗易懂
《老饼讲解-神经网络》:老饼讲解-matlab神经网络-通俗易懂
《老饼讲解-神经网络》:老饼讲解-深度学习-通俗易懂


















 1269
1269

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











