



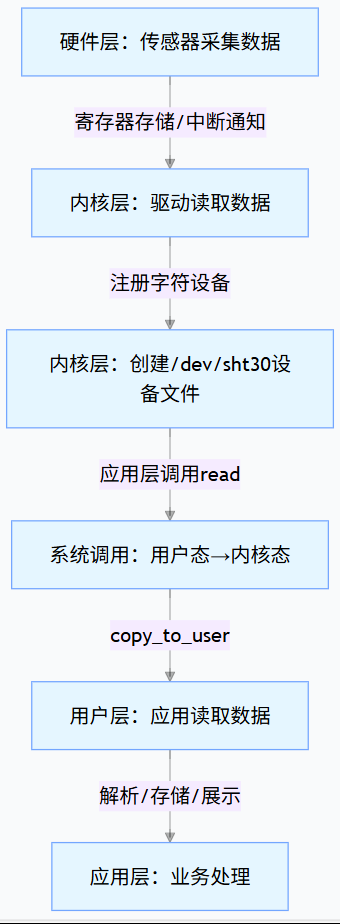
底层数据到应用层的整体流程:
核心前提:(Linux 的 “态隔离” 机制)
内核态:拥有硬件访问权限(可直接读写寄存器、操作外设),运行驱动、内核子系统(如 I2C/SPI 子系统);
用户态:无硬件访问权限,运行应用程序(如数据处理、UI 显示);
数据传递必须通过内核提供的标准接口(如系统调用、设备文件),禁止用户态直接操作硬件(避免破坏系统稳定性)。
二、整体流程:从底层到应用层的 5 个关键步骤
步骤 1:底层硬件产生数据(硬件层)
- 硬件触发:传感器通过硬件总线(I2C/SPI/UART)与 CPU 连接,按预设周期采集数据(如 SHT30 每 1 秒采集一次温度、湿度),并将数据暂存到自身的数据寄存器中;
- 硬件中断(可选):若传感器支持中断,数据就绪后会通过 GPIO 向 CPU 发送中断信号,通知内核 “数据可读取”(避免内核轮询,降低 CPU 占用)。
步骤 2:内核驱动读取硬件数据(内核层 - 驱动层)
内核通过设备驱动(Driver)作为 “硬件与内核的桥梁”,完成硬件数据的读取,核心是驱动的初始化与数据采集逻辑:
-
驱动初始化:
- 驱动加载时(如通过
insmod/modprobe),向内核注册硬件相关信息:- 总线匹配:通过设备树(Device Tree)中的节点(如
i2c@10002000)匹配硬件(I2C 控制器、传感器地址); - 设备文件创建:通过
cdev_init/cdev_add注册字符设备,在/dev目录下创建设备文件(如/dev/sht30),作为应用层访问的 “入口”; - 中断注册(若用中断):通过
request_irq注册中断处理函数,响应传感器的 “数据就绪” 中断。
- 总线匹配:通过设备树(Device Tree)中的节点(如
- 驱动加载时(如通过
-
数据读取逻辑:
- 若用轮询:驱动通过内核的 I2C 子系统接口(如
i2c_transfer),向传感器发送 “读取数据” 命令,从传感器寄存器中读取原始数据(如 2 字节温度、2 字节湿度); - 若用中断:传感器触发中断后,中断处理函数唤醒驱动中的等待队列(
wait_queue_head_t),驱动再执行i2c_transfer读取数据,并将数据暂存到驱动的内核缓冲区(如char data_buf[10])。
- 若用轮询:驱动通过内核的 I2C 子系统接口(如
步骤 3:内核层提供数据访问接口(内核层 - 接口层)
驱动读取数据后,需通过内核定义的标准接口将数据暴露给用户态,常用接口有 3 类:
| 接口类型 | 核心原理 | 适用场景 | 示例(应用层调用) |
|---|---|---|---|
| 字符设备文件 | 驱动注册字符设备,应用层通过文件 IO(open/read/write)访问 | 大多数外设(传感器、UART) | open("/dev/sht30", O_RDONLY) |
| sysfs 接口 | 驱动通过sysfs_create_file在/sys/class/下创建文件,映射硬件属性 | 简单属性读取(如版本、状态) | cat /sys/class/sht30/temperature |
| netlink 通信 | 内核与应用层通过 socket(AF_NETLINK)异步通信 | 高频、实时数据(如网络状态) | socket(AF_NETLINK, SOCK_RAW, ...) |
典型场景(字符设备文件):驱动在file_operations结构体中实现read函数,当应用层调用read时,内核执行驱动的read函数,将内核缓冲区中的数据拷贝到应用层缓冲区。
步骤 4:应用层通过接口读取数据(用户层 - 数据读取)
应用层通过内核提供的接口,发起 “读取数据” 的请求,核心是系统调用(System Call) 的触发:
-
应用层调用文件 IO 函数:
// 应用层代码示例(读取SHT30温度) #include <stdio.h> #include <fcntl.h> #include <unistd.h> int main() { int fd; float temperature; char buf[4]; // 存储传感器原始数据(2字节温度) // 1. 打开设备文件(触发sys_open系统调用,进入内核态) fd = open("/dev/sht30", O_RDONLY); if (fd < 0) { perror("open fail"); return -1; } // 2. 读取数据(触发sys_read系统调用,进入内核态) read(fd, buf, sizeof(buf)); // 内核将数据从驱动缓冲区拷贝到buf // 3. 数据解析(原始数据转实际温度,如SHT30的温度计算:temp = (buf[0]<<8 | buf[1]) * 175.0 / 65535 - 45) temperature = ( (buf[0] << 8) | buf[1] ) * 175.0 / 65535 - 45; printf("Temperature: %.2f°C\n", temperature); // 4. 关闭设备文件 close(fd); return 0; } -
系统调用的 “态切换”:
- 应用层调用
open/read时,CPU 从用户态切换到内核态(通过软中断int 0x80或syscall指令); - 内核执行对应的系统调用函数(如
sys_open/sys_read),最终调用驱动的open/read函数; - 数据读取完成后,CPU 从内核态切换回用户态,应用层继续执行数据解析逻辑。
- 应用层调用
步骤 5:应用层数据处理与展示(用户层 - 数据消费)
应用层读取到底层数据后,根据业务需求进行后续处理:
- 数据解析:将底层原始数据(如传感器的二进制值)转换为人类可读的格式(如温度值
25.5°C、湿度值60%RH); - 数据存储:将数据写入本地存储(如
/tmp/sensor.log)或数据库(如 SQLite); - 数据展示:通过 UI 界面(如 Qt、LVGL)、终端打印或网络上传(如 MQTT 发送到云端);
- 业务逻辑触发:若数据超出阈值(如温度 > 30°C),触发报警逻辑(如点亮 LED、蜂鸣器)。
基于platform注册字符设备流程
platform_device
设备树中定义 platform 设备(描述硬件)
plarform_driver
2.1 驱动核心结构体定义
/* leddev设备结构体 */
struct leddev_dev{
dev_t devid; /* 设备号 */
struct cdev cdev; /* cdev */
struct class *class; /* 类 */
struct device *device; /* 设备 */
int major; /* 主设备号 */
struct device_node *node; /* LED设备节点 */
int led0; /* LED灯GPIO标号 */
};
2.2 字符设备操作接口(用户空间调用)
/* 设备操作函数 */
static struct file_operations led_fops = {
.owner = THIS_MODULE,
.open = led_open,
.write = led_write,
};
2.3 platform 驱动的 probe 函数(设备匹配后执行)
static int led_probe(struct platform_device *dev)
{
printk("led driver and device was matched!\r\n");
/* 1、设置设备号 */
if (leddev.major) {
leddev.devid = MKDEV(leddev.major, 0);
register_chrdev_region(leddev.devid, LEDDEV_CNT, LEDDEV_NAME);
} else {
alloc_chrdev_region(&leddev.devid, 0, LEDDEV_CNT, LEDDEV_NAME);
leddev.major = MAJOR(leddev.devid);
}
/* 2、注册设备 */
cdev_init(&leddev.cdev, &led_fops);
cdev_add(&leddev.cdev, leddev.devid, LEDDEV_CNT);
/* 3、创建类 */
leddev.class = class_create(THIS_MODULE, LEDDEV_NAME);
if (IS_ERR(leddev.class)) {
return PTR_ERR(leddev.class);
}
/* 4、创建设备 */
leddev.device = device_create(leddev.class, NULL, leddev.devid, NULL, LEDDEV_NAME);
if (IS_ERR(leddev.device)) {
return PTR_ERR(leddev.device);
}
/* 5、初始化IO */
leddev.node = of_find_node_by_path("/gpioled");
if (leddev.node == NULL){
printk("gpioled node nost find!\r\n");
return -EINVAL;
}
leddev.led0 = of_get_named_gpio(leddev.node, "led-gpio", 0);
if (leddev.led0 < 0) {
printk("can't get led-gpio\r\n");
return -EINVAL;
}
gpio_request(leddev.led0, "led0");
gpio_direction_output(leddev.led0, 1); /* led0 IO设置为输出,默认高电平 */
return 0;
}
2.4 platform 驱动的 remove 函数(设备移除时执行)
static int led_remove(struct platform_device *dev)
{
gpio_set_value(leddev.led0, 1); /* 卸载驱动的时候关闭LED */
gpio_free(leddev.led0); /* 释放IO */
cdev_del(&leddev.cdev); /* 删除cdev */
unregister_chrdev_region(leddev.devid, LEDDEV_CNT); /* 注销设备号 */
device_destroy(leddev.class, leddev.devid);
class_destroy(leddev.class);
return 0;
}
2.5 设备树匹配表与 platform 驱动结构体
/* 匹配列表 */
static const struct of_device_id led_of_match[] = {
{ .compatible = "atkalpha-gpioled" },
{ /* Sentinel */ }
};
/* platform驱动结构体 */
static struct platform_driver led_driver = {
.driver = {
.name = "imx6ul-led", /* 驱动名字,用于和设备匹配 */
.of_match_table = led_of_match, /* 设备树匹配表 */
},
.probe = led_probe,
.remove = led_remove,
};
2.6 驱动入口与出口
/*
* @description : 驱动模块加载函数
* @param : 无
* @return : 无
*/
static int __init leddriver_init(void)
{
return platform_driver_register(&led_driver);
}
/*
* @description : 驱动模块卸载函数
* @param : 无
* @return : 无
*/
static void __exit leddriver_exit(void)
{
platform_driver_unregister(&led_driver);
}
platform和i2c和spi的区别
| 对比维度 | platform(设备模型) | I2C(总线协议) | SPI(总线协议) |
|---|---|---|---|
| 本质 | 软件抽象(内核设备模型) | 硬件总线(两线制串行通信协议) | 硬件总线(四线制串行通信协议) |
| 硬件依赖 | 无专用总线,外设集成在 SOC 内部(通过寄存器访问) | 依赖 SDA/SCL 两根信号线,有明确电气规范 | 依赖 MOSI/MISO/SCK/CS 四根信号线,电气规范灵活 |
| 通信方式 | 直接读写寄存器(内存映射) | 基于地址的帧格式通信(START/STOP 信号、ACK 应答) | 基于时钟边沿的全双工通信(无应答机制) |
| 速率 | 无 “通信速率” 概念(直接访问寄存器,速度由 CPU 决定) | 较低(最高几 Mbps) | 较高(可达几十 Mbps 以上) |
| 设备数量 | 通常是 SOC 内部固定的外设(数量有限) | 支持多设备(通过 7 位 / 10 位地址区分,理论上 127 个) | 支持多设备(通过 CS 片选线区分,数量取决于 CS 引脚) |
| 典型外设 | 片上 GPIO、UART、定时器、DMA 控制器 | 温湿度传感器(如 SHT30)、EEPROM、触摸 IC | SPI Flash(如 W25Q 系列)、OLED 屏、AD 芯片 |
在代码编写方面基本没有区别。
编写i2c_driver框架
定义设备树匹配表,定义I2C设备ID表
// 设备ID表,用于匹配I2C设备
static const struct i2c_device_id example_i2c_id[] = {
{ "example-i2c-device", 0 },
{ }
};
MODULE_DEVICE_TABLE(i2c, example_i2c_id);
// 设备树匹配表,用于设备树方式匹配
#ifdef CONFIG_OF
static const struct of_device_id example_i2c_of_match[] = {
{ .compatible = "example,i2c-device" },
{ }
};
MODULE_DEVICE_TABLE(of, example_i2c_of_match);
#endif
定义I2C设备驱动的探测函数
// 设备探测函数,当驱动匹配到设备时调用
static int example_i2c_probe(struct i2c_client *client, const struct i2c_device_id *id)
{
struct example_dev *dev;
int ret;
u8 val;
dev_info(&client->dev, "Probing I2C device at address 0x%02x\n", client->addr);
// 分配设备私有数据结构
dev = devm_kzalloc(&client->dev, sizeof(struct example_dev), GFP_KERNEL);
if (!dev)
return -ENOMEM;
dev->client = client;
i2c_set_clientdata(client, dev);
// 示例:读取设备ID寄存器(假设0x00是ID寄存器)
ret = example_i2c_read(dev, 0x00, &val, 1);
if (ret == 0) {
dev_info(&client->dev, "Device ID: 0x%02x\n", val);
} else {
dev_warn(&client->dev, "Failed to read device ID, continuing anyway\n");
}
// 这里可以添加设备初始化代码
return 0;
}
定义I2C设备驱动的移除函数
// 设备移除函数,当设备从系统中移除时调用
static int example_i2c_remove(struct i2c_client *client)
{
struct example_dev *dev = i2c_get_clientdata(client);
dev_info(&client->dev, "Removing I2C device at address 0x%02x\n", client->addr);
// 这里可以添加设备清理代码
return 0;
}
定义I2C设备结构体
// I2C驱动结构体
static struct i2c_driver example_i2c_driver = {
.driver = {
.name = DRIVER_NAME,
.of_match_table = of_match_ptr(example_i2c_of_match),
},
.probe = example_i2c_probe,
.remove = example_i2c_remove,
.id_table = example_i2c_id,
.address_list = example_i2c_addresses,
};
定义模块初始化函数,定义模块退出函数
// 模块初始化和退出函数
module_i2c_driver(example_i2c_driver);
为什么要区分内核态跟用户态
- 内核态:操作系统内核(如 Linux 内核、Windows 内核)运行的特权状态,可直接访问所有硬件资源(CPU、内存、磁盘、网卡等),执行所有机器指令(包括 “特权指令”,如修改内存地址映射、控制 IO 设备)。
- 用户态:应用程序(如浏览器、文档软件、游戏)运行的非特权状态,仅能访问自身被分配的内存空间,无法直接操作硬件,需通过 “系统调用” 向内核发起请求,由内核代其完成特权操作。
保障操作系统的安全、稳定与资源的有序管理
内核态就没有虚拟地址吗?,内核态虚拟地址跟用户态虚拟地址有什么区别?
内核态有虚拟地址,虚拟地址通过内存管理单元映射到物理地址。
| 维度 | 内核态虚拟地址 | 用户态虚拟地址 |
|---|---|---|
| 地址范围 | 高地址区域(如 32 位 Linux 的 0xC0000000 以上) | 低地址区域(如 32 位 Linux 的 0x00000000~0xBFFFFFFF) |
| 映射共享性 | 全局共享(所有进程看到相同映射) | 进程私有(每个进程映射独立) |
| 访问权限 | 内核级(仅内核态可访问,权限高) | 用户级(仅用户态可访问,权限低) |
| 映射内容 | 内核代码、数据、物理内存、硬件 IO | 应用代码、堆、栈、共享库 |
| 特殊映射机制 | 线性映射、高端内存映射 | 无特殊机制,依赖动态分配 |
内核态的进程/线程跟用户态进程/线程的有什么区别
| 对比维度 | 内核态进程 / 线程(内核线程) | 用户态进程 / 线程 |
|---|---|---|
| 运行空间 | 内核空间(共享内核地址空间) | 用户空间(每个进程独立的虚拟地址空间) |
| 特权级别 | Ring 0(最高特权,可执行所有指令) | Ring 3(低特权,仅能执行非特权指令) |
| 资源访问 | 直接访问硬件和内核数据结构 | 仅访问自身用户空间,依赖系统调用访问硬件 |
| 调度切换 | 内核直接调度,切换开销较小(无地址空间切换) | 内核调度(或用户态线程库调度),跨进程切换开销大 |
| 内存独立性 | 共享内核资源,无独立用户空间 | 进程间地址隔离,线程共享所属进程的用户空间 |
| 创建者与生命周期 | 内核创建,随系统启动 / 关闭 | 用户程序创建,由用户或内核控制终止 |
| 典型用途 | 内核任务(内存管理、IO 调度、中断处理) | 应用逻辑(用户交互、数据处理、网络服务) |
MMU是用户态的虚拟地址转换还是内核态的虚拟地址
MMU(内存管理单元,Memory Management Unit)并非只处理用户态或内核态某一种虚拟地址的转换,而是负责整个系统中所有虚拟地址(包括用户态虚拟地址和内核态虚拟地址)到物理地址的映射与转换。
用户态触发异常后,内核怎么处理
硬件触发→内核接管→异常分析→处理与恢复
当用户态程序执行了非法操作,CPU会立即触发异常,暂停当前用户态执行,保存上下文(将用户态的关键寄存器(如程序计数器PC、栈指针SP、状态寄存器CPSR等)压入内核栈(而非用户栈,防止用户态篡改),记录异常发生的位置和状态), 切换成内核态,跳转到异常向量表(根据异常类型(如页错误、未定义指令),CPU 自动跳转到内核预设的 “异常向量表” 中对应的入口地址(内核初始化时已设置好))。
共享内存,往里面写一个东西,对方能知道吗?
写入方将数据写入共享内存后,对方(读取方)不会被操作系统 “自动通知” 数据已更新,读取方可以通过主动检查或配合其他同步 / 通知机制,感知到共享内存中的数据变化。‘
同步机制:
1、基于 “标志位” 的主动检查
2、信号量
3、互斥锁
4、消息队列或管道
信号量的原理是什么呢?他是怎么做到通知对方的呢?
- 通过原子的 P/V 操作修改 “资源计数器”,控制进程对共享资源的访问;
- 借助等待队列管理阻塞的进程,当资源可用时(V 操作),自动唤醒等待队列中的进程,实现 “通知对方” 的功能。
代码中要模拟一个信号量的功能,你应该怎么做呢?底层怎么通知对方的呢?等待这个值肯定需要一个锁,你认为用什么锁?或者说这个进程要等待是吧,等待要睡眠,怎么睡眠?用什么方式让他睡眠?
设计信号量的核心结构
需包含 3 个关键组件,缺一不可:
- 计数器(count):记录当前可用资源数量(初始值由业务场景决定,如 “缓冲区空位置数”“允许并发的线程数”)。
- 互斥锁(mutex):保护计数器的原子性修改(确保 P/V 操作不会被并发线程打断)。
- 条件变量(cond):维护一个 “等待队列”,用于存放资源不足时需要阻塞(睡眠)的线程。
P 操作(申请资源):
- 加互斥锁:确保后续操作原子性,避免多线程同时修改计数器。
- 检查资源:若
count <= 0(资源不足),通过条件变量的wait函数让线程释放锁并睡眠(进入阻塞态,放入等待队列);被唤醒后重新获取锁,再次检查资源(用while循环避免虚假唤醒)。 - 获取资源:若
count > 0,计数器减 1(count--),表示成功占用资源。 - 释放互斥锁:允许其他线程执行 P/V 操作。
V 操作(释放资源并通知):
- 加互斥锁:确保计数器修改的原子性。
- 释放资源:计数器加 1(
count++),表示资源数量增加。 - 通知等待线程:若
count <= 0(说明有线程在等待队列中),通过条件变量的signal函数唤醒一个等待线程(从阻塞态转为就绪态)。 - 释放互斥锁:允许其他线程执行 P/V 操作。
如何用cmake生成静态链接库动态链接库,private public区别
CMake 通过add_library命令生成链接库,通过指定类型(STATIC/SHARED)区分静态库和动态库。
动态库:
编译的时候,只记录库的引用,运行时动态加载,优点是可执行文件小,库更新无需重新编译主程序。
静态库:
编译的时候将库文件直接嵌入到可执行文件,运行时不依赖外部文件,缺点是可执行文件体积大,库更新需要重新编译。
链接做了什么东西呢?(不单是打包的过程)
整合多个目标文件和库文件的代码与数据,修正符号引用(找到定义)和地址偏移(分配绝对地址)。
13.c++左值和右值,为什么要区分左值引用右值引用,右值引用本身就带了资源转交,还是说要调用函数去实现呢?move这个操作资源会不会转交资源?
-
左值:可以取地址,有明确的名称,生命周期较长(通常与作用域绑定)。
例如:变量(int a = 5;中的a)、数组元素(arr[0])、返回左值引用的函数(int& func())。 -
右值:不能取地址,没有名称,是临时的(生命周期通常在当前表达式结束后结束)。
例如:字面量(5、"hello")、临时对象(A(),调用构造函数生成的匿名对象)、返回非引用的函数(int func()的返回值)。
什么是中断上下文,为什么在中断处理函数中不能休眠
中断上下文是硬件中断触发后,操作系统执行中断处理函数时所处的运行环境(寄存器值、程序计数器(PC)、栈空间、资源句柄等)。
引伸:注意不是进程上下文,二者区别在于触发中断前的函数属于进程。
4. 继续问什么是进程上下文
包含 CPU 寄存器状态(寄存器值、程序计数器(PC))、内存映射、资源句柄等所有必要信息
介绍DMA,继续追问是什么驱使我用DMA而不是CPU
硬件辅助数据传输技术,通过专门的 “DMA 控制器(DMAC)”,让外设(如硬盘、网卡、声卡、ADC/DAC)直接与系统内存交换数据,无需 CPU 全程参与,仅在 “传输初始化” 和 “传输完成” 时需要 CPU 介入。
| 对比维度 | 用 CPU 处理数据传输 | 用 DMA 处理数据传输 |
|---|---|---|
| CPU 资源占用 | 100% 占用:CPU 需全程参与 “读外设→写内存” 或 “读内存→写外设” 的每一步,期间无法做其他事 | 几乎 0 占用:仅在 “请求” 和 “完成” 阶段通知 CPU,传输过程 CPU 可并行处理计算任务 |
| 传输效率 | 低:CPU 的设计目标是 “复杂计算”,而非 “高速数据搬运”,每笔数据都需经过 CPU 寄存器中转,存在延迟 | 高:DMA 直接对接总线,数据无需 CPU 中转,传输速度仅受总线带宽和外设速度限制 |
| 系统响应性 | 差:若 CPU 忙于搬运大文件(如拷贝 10GB 数据),会 “阻塞” 其他任务(如打开浏览器、点击文件夹),导致系统卡顿 | 好:DMA 负责搬运数据时,CPU 可同时处理用户操作、应用计算,系统流畅度不受影响 |
| 能耗与发热 | 高:CPU 在 “计算” 和 “搬运数据” 间频繁切换,且全程高负载,会增加能耗和发热 | 低:DMA 芯片的功耗远低于 CPU,用 DMA 处理传输可降低整体系统能耗(尤其对笔记本、手机等移动设备重要) |
I2C、SPI、Uart等通信协议中,用DMA比较频繁,比如我项目中的XX项目,在录音时,系统就采用DMA去搬运音频数据。
如果遇到IIC读写错误的问题,你会怎么排查
首先先区分是软件或硬件引发的错误。
硬件错误:I2C两个数据线是否属于通路,上拉电阻阻值是否合适,不能一概使用4.7kΩ电阻,这个过程使用示波器。
软件错误:
1、从机设备地址
能否通过从机设备地址找到从机,若找不到,有两种可能,从设备无法启动;设备地址错误或多设备地址冲突。
2、正在读取线程被打断
在XX项目中,向写入长序列固件时,如果被其他线程打断,会出现序列不完整,从设备不知道你还在写入,从而导致错误。
3、读取的寄存器不存在
从机无法识别该寄存器,会出现两种结果,未应答,应答后返回数据错误。
有无用过中断下半部的工作队列和Tasklet
中断上半部:中断发生时立即执行的处理程序,是中断响应的 “紧急部分”
中断下半部:延迟执行的中断处理部分,负责处理上半部遗留的、耗时较长的任务
1、softirq:静态定义(编译时注册),优先级高于任务,可在多个 CPU 上并行执行,内核定义了 10 种预定义软中断(如NET_TX_SOFTIRQ、NET_RX_SOFTIRQ对应网络收发),用户驱动一般不建议使用,因为静态注册难以扩展,且并行执行需处理复杂的同步问题
2、tasklet:内部实现实际调用了softirq,它的实现方法是将中断下半部,放入到内核线程的一个软中断链表(SOFTIRQD)中,内核线程会自动执行链表的方法。
注意的是这个线程是运行在中断上下文中的,只要涉及到中断,就不可以使用休眠或延时等阻塞函数。中断不允许有这样的操作。
实现步骤:
1、定义一个TASKLET对象:struct tasklet_struct my_tasklet;
2、初始化结构体对象:
tasklet_init(struct tasklet_struct * t, void(* func)(unsigned long), unsigned long data)
在初始化的时候就创建了一个软中断链表,所以用完之后要销毁
参数一、对象地址,参数二,中断下半部函数,参数三、给函数传的值
static int __init tasklet_demo_init(void)
{
int ret;
unsigned int irq = 12; // 虚拟中断号(实际需替换)
// 动态初始化tasklet(运行时调用)
tasklet_init(&my_tasklet, tasklet_handler, 0);
// 注册中断
ret = request_irq(irq, irq_handler, IRQF_SHARED, "tasklet_demo", &my_tasklet);
if (ret) {
printk(KERN_ERR "中断注册失败: %d\n", ret);
return ret;
}
printk(KERN_INFO "模块加载完成,tasklet已动态初始化\n");
return 0;
}
3,编写我们的中断下半部函数
// tasklet处理函数(下半部)
static void tasklet_handler(unsigned long data)
{
printk(KERN_INFO "Tasklet: 处理数据: %s\n", shared_buffer);
}
4,在中断上半部在放入到内核线程中–启动下半部
tasklet_schedule(&key_dev->mytasklet);
static irqreturn_t irq_handler(int irq, void *dev_id)
{
printk(KERN_INFO "IRQ: 上半部开始处理\n");
// 模拟读取硬件数据
snprintf(shared_buffer, sizeof(shared_buffer), "动态tasklet测试数据");
// 调度tasklet执行
tasklet_schedule(&my_tasklet);
return IRQ_HANDLED;
}
5,卸载结构体对像
tasklet_kill(&key_dev->mytasklet);
static void __exit tasklet_demo_exit(void)
{
unsigned int irq = 12;
free_irq(irq, &my_tasklet);
tasklet_kill(&my_tasklet); // 确保tasklet执行完毕
printk(KERN_INFO "模块卸载完成\n");
}
3、workqueue:
工作队列和软中断链表相似。不同的就是工作队列不需要手动创建,它内核启动后会创建一个工作线程和一个工作队列,也就是说内核会提供一个工作队列给所有进程共用 ,因此自然而然的也就不需要释放这个工作队列的内存资源。
注意这个队列是运行在进程上下文中,所以可以使用延时,休眠等阻塞操作。
1、在装载模块中初始化工作队列
INIT_WORK(struct work_struct *work, work_func_t func);
static int __init workqueue_demo_init(void)
{
int ret;
unsigned int irq = 12; // 虚拟中断号(实际需替换)
printk(KERN_INFO "Workqueue demo: 模块加载中...\n");
// 初始化工作项
INIT_WORK(&my_work_item.work, workqueue_handler);
// 注册中断,将工作项作为dev_id传递
ret = request_irq(irq, irq_handler, IRQF_SHARED,
"workqueue_demo", &my_work_item);
if (ret) {
printk(KERN_ERR "Workqueue demo: 中断注册失败: %d\n", ret);
return ret;
}
printk(KERN_INFO "Workqueue demo: 模块加载完成\n");
return 0;
}
2、实现工作队列的下半部函数
// 工作队列处理函数(下半部,运行在进程上下文)
static void workqueue_handler(struct work_struct *work)
{
// 通过container_of获取自定义数据结构
struct my_work *mw = container_of(work, struct my_work, work);
struct work_data *data = &mw->data;
printk(KERN_INFO "Workqueue: 开始处理数据\n");
// 工作队列运行在进程上下文,可以:
// 1. 调用可能阻塞的内存分配函数
char *buf = kmalloc(1024, GFP_KERNEL); // GFP_KERNEL允许睡眠
if (buf) {
snprintf(buf, 1024, "处理后的数据: %s", data->buffer);
printk(KERN_INFO "Workqueue: %s\n", buf);
kfree(buf); // 释放内存
}
// 2. 执行耗时较长的处理(合理范围内)
printk(KERN_INFO "Workqueue: 数据值=%d\n", data->value);
// 3. 使用可能引起阻塞的同步机制(如mutex)
// mutex_lock(&my_mutex);
// ... 处理共享资源
// mutex_unlock(&my_mutex);
printk(KERN_INFO "Workqueue: 数据处理完成\n");
}
3、在中断上半部在放入到内核线程中–启动下半部
schedule_work(&key_dev->mywork);
// 中断处理函数(上半部)
static irqreturn_t irq_handler(int irq, void *dev_id)
{
struct my_work *mw = (struct my_work *)dev_id;
printk(KERN_INFO "IRQ: 上半部开始处理\n");
// 1. 上半部:处理紧急事务,收集数据
mw->data.value = 0x1234; // 模拟硬件数据
snprintf(mw->data.buffer, sizeof(mw->data.buffer),
"硬件数据: %d,时间戳: %ld", mw->data.value, jiffies);
// 2. 调度工作队列(下半部)处理后续任务
schedule_work(&mw->work);
printk(KERN_INFO "IRQ: 上半部处理完成,已调度工作队列\n");
return IRQ_HANDLED;
}
| 特性 | 软中断(Softirq) | tasklet | 工作队列(Workqueue) |
|---|---|---|---|
| 执行上下文 | 中断上下文(不可睡眠 / 阻塞) | 中断上下文(不可睡眠 / 阻塞) | 进程上下文(可睡眠 / 阻塞) |
| 并发性 | 可在多个 CPU 上并行执行 | 同一 tasklet 不可并行(自动序列化) | 可由多线程并行执行(需手动同步) |
| 注册方式 | 编译时静态注册(不可动态添加) | 运行时动态创建 | 运行时动态创建 |
| 调度触发 | raise_softirq() | tasklet_schedule() | schedule_work() |
| 适用场景 | 高频、高性能需求(如网络 / 块设备) | 驱动中简单的延迟任务(如数据处理) | 需要阻塞操作的场景(如 I/O、内存分配) |
| 是否可重入 | 是(需手动处理同步) | 否(同一 tasklet 串行执行) | 是(需手动处理同步) |
| 依赖的机制 | 内核直接支持的底层机制 | 基于软中断实现(HI_SOFTIRQ/TASKLET_SOFTIRQ) | 基于内核线程(kworker)实现 |
在工作队列中可以休眠吗
可以。与软中断不同的是,工作队列处于进程。
工作队列是工作在进程上下文还是中断上下文
进程上下文。
驱动能直接访问用户空间的内存吗?那如何实现间接访问?
驱动不可以直接访问用户控件,但是可以通过一些Linux有提供专门的内核函数间接访问(copy_from_user/copy_to_user)。
介绍堆栈的区别
1、管理方式:
栈:完全由编译器控制。
当函数被调用时,编译器自动在栈上为函数的参数、局部变量分配内存;当函数返回时,编译器自动释放这些内存(通过移动栈顶指针实现),无需程序员干预。
堆:完全由程序员控制。
需要手动调用分配函数(如 C++ 的new、C 的malloc),并在使用完毕后手动释放(如delete、free)。若忘记释放,会导致内存泄漏(直到程序结束才被操作系统回收)。
2、空间大小与增长方向
栈:
大小有限(通常默认 1-8MB,可通过编译器或系统配置调整,但不宜过大)。增长方向是 “向下”(从高地址向低地址扩展),栈顶指针(esp寄存器)随分配 / 释放移动。若栈空间耗尽(如递归过深),会触发栈溢出(Stack Overflow)错误。
堆:
大小几乎不受限(理论上可达虚拟内存上限,如 32 位系统约 4GB,64 位系统更大)。增长方向是 “向上”(从低地址向高地址扩展),通过链表管理空闲内存块。堆空间耗尽时,分配函数会返回nullptr(C++)或NULL(C)。
3、分配效率与碎片
栈:
分配效率极高,因为本质是 “移动栈指针”(如sub esp, 4分配 4 字节),无需复杂计算,时间复杂度为 O (1)。且栈内存的分配和释放严格遵循 “先进后出”(FILO)顺序,不会产生碎片。
堆:
分配效率较低,因为需要遍历 “空闲内存块链表”,找到足够大的块(称为 “内存分配算法”,如首次适应、最佳适应等),时间复杂度通常为 O (n)。频繁分配 / 释放不同大小的堆内存会产生 “内存碎片”(小块空闲内存无法被利用),导致可用内存减少。
4、存储内容与生命周期
-
栈:
主要存储短期存在的数据:- 函数的参数和局部变量;
- 函数返回地址(用于函数调用结束后回到原执行点);
- CPU 寄存器现场(用于函数切换时保存 / 恢复状态)。
生命周期与 “作用域” 绑定:出作用域(如函数返回、}执行)后立即释放。
-
堆:
主要存储长期存在或动态大小的数据:- 动态创建的对象(如
new Object()); - 长度不确定的数组(如用户输入决定大小的数组);
- 跨函数传递的大型数据(避免栈空间不足)。
生命周期由程序员控制:从new/malloc分配开始,到delete/free释放结束,与作用域无关。
- 动态创建的对象(如
| 特性 | 栈(Stack) | 堆(Heap) |
|---|---|---|
| 管理方式 | 由编译器自动分配和释放(无需手动干预) | 由程序员手动分配和释放(如new/delete、malloc/free) |
| 空间大小 | 通常较小(默认几 MB,由系统限制) | 通常较大(可达 GB 级,受物理内存和虚拟内存限制) |
| 增长方向 | 向下增长(从高地址向低地址分配) | 向上增长(从低地址向高地址分配) |
| 分配效率 | 极高(仅需移动栈指针,O (1) 时间复杂度) | 较低(需遍历空闲链表查找合适内存块,O (n) 或更复杂) |
| 存储内容 | 函数参数、局部变量、返回地址、寄存器现场等 | 动态分配的对象、数组、大型数据结构等 |
| 碎片问题 | 无碎片(分配释放严格遵循 “先进后出”) | 容易产生碎片(频繁分配释放不同大小的内存块) |
| 访问速度 | 快(栈内存通常被 CPU 高速缓存缓存) | 慢(需通过指针间接访问,可能未被缓存) |
| 生命周期 | 与作用域绑定(出作用域自动释放) | 与代码逻辑绑定(需手动释放,否则导致内存泄漏) |
16.有没有分析过内存泄露和内存溢出的问题
内存泄漏:程序在动态分配内存后,未释放或无法释放已不再使用的内存,导致这部分内存长期被占用,直到程序结束才被操作系统回收。
freertos经常使用内存空间大小查看的函数。
内存溢出:程序申请的内存超过了系统能提供的最大限制,或向一块内存写入的数据超过了其分配的大小,导致内存访问越界。
介绍一下之前用gdb调试的经历
定位底层错误(如内存越界、空指针、逻辑漏洞等)
- 确定可疑范围(数组 / 缓冲区的地址和大小);
- 设置监控断点(内存断点或条件断点),捕捉越界瞬间;
- 分析上下文(变量值、调用栈),定位越界原因。
(1)GDB 调试崩溃现场
当程序因空指针崩溃时,通过 GDB 查看崩溃位置和调用栈:
有没有用gdb调试过踩内存的问题
两个线程同时删除锁
什么是优先级反转
高优先级任务因等待低优先级任务占用的资源,导致中等优先级任务意外优先执行。
临界资源:
临界资源指的是一次只能被一个进程(或线程)访问的共享资源。
临界区:
临界区 —— 指进程 / 线程中访问临界资源的那段代码。
多个进程 / 线程的临界区不会同时执行,从而保护临界资源不被错误访问。
线程间有哪些同步机制,怎么解决并发竞争的问题
| 机制 | 核心优势 | 核心劣势 | 适用场景 |
|---|---|---|---|
| 互斥锁 | 实现简单,保证独占访问 | 单线程并发,读操作性能低 | 多线程互斥访问共享资源(读写频率均衡) |
| 条件变量 | 避免忙等,实现线程间条件通信 | 依赖互斥锁,需处理虚假唤醒 | 线程需等待特定条件(如生产者 - 消费者模型) |
| 信号量 | 支持多线程并发访问,可跨进程 | 实现较复杂,易因计数错误导致 bug | 有限资源的并发控制(线程池、缓冲区) |
| 读写锁 | 读操作并发,提升多读场景性能 | 写操作独占,可能导致写饥饿 | 多读少写场景(配置读取、缓存访问) |
| 原子操作 | 无锁,性能极高 | 仅支持单个变量,功能有限 | 简单变量同步(计数器、标志位) |
| 屏障 | 确保多线程同步到达执行节点 | 仅支持分阶段同步,适用场景单一 | 多线程分阶段任务(如并行计算) |
进程间的通信方式有哪些
一、管道(Pipes)
管道是单向的、基于字节流的通信通道,适用于具有亲缘关系(如父子进程)的进程间通信。
#include <unistd.h>
int main() {
int fd[2];
pipe(fd); // 创建管道,fd[0]读端,fd[1]写端
if (fork() == 0) { // 子进程
close(fd[1]); // 关闭写端
char buf[100];
read(fd[0], buf, sizeof(buf)); // 从管道读数据
} else { // 父进程
close(fd[0]); // 关闭读端
write(fd[1], "hello", 5); // 向管道写数据
}
return 0;
}
二、信号(Signals)
信号是操作系统向进程发送的异步通知,用于处理异常或特定事件(如中断、退出)。
#include <signal.h>
void handle_sigint(int sig) {
printf("收到中断信号\n");
}
int main() {
signal(SIGINT, handle_sigint); // 注册信号处理函数
while(1); // 等待信号
return 0;
}
| 维度 | 信号(软件中断) | 硬件中断(硬件触发) |
|---|---|---|
| 触发源 | 由进程(kill())或内核(如异常)触发 | 由外部硬件设备(如键盘、定时器)触发 |
| 处理上下文 | 在用户态执行信号处理函数 | 在内核态执行中断服务程序(ISR) |
| 优先级 | 信号之间有优先级,但由内核统一调度 | 硬件中断有严格的硬件优先级(如 CPU 的中断控制器决定) |
| 可屏蔽性 | 大部分信号可被阻塞(sigprocmask()) | 硬件中断可通过中断屏蔽寄存器(IMR)屏蔽 |
| 处理函数限制 | 可调用大部分用户态函数(需注意重入性) | ISR 需极简(禁止睡眠、复杂操作) |
三、共享内存(Shared Memory)
共享内存是多个进程直接访问同一块物理内存的通信方式,是效率最高的 IPC 机制。
- 进程 A 创建共享内存并写入数据;
- 进程 B 将共享内存映射到自己的地址空间,直接读取数据;
- 通信完成后,通过
shmdt()解除映射,shmctl()删除共享内存。
接收:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <unistd.h>
// 与writer相同的数据结构(必须一致,否则解析错误)
struct shared_data {
int flag; // 同步标志:0表示无数据,1表示有数据
char message[256]; // 消息内容
};
int main() {
key_t key;
int shmid;
struct shared_data *shm_ptr;
// 1. 使用相同的键值获取共享内存(与writer保持一致)
key = ftok("shm_file", 65);
if (key == -1) {
perror("ftok failed");
exit(EXIT_FAILURE);
}
// 2. 获取已创建的共享内存(不创建新的,只获取)
shmid = shmget(key, sizeof(struct shared_data), 0666);
if (shmid == -1) {
perror("shmget failed");
exit(EXIT_FAILURE);
}
printf("Reader: 找到共享内存,ID = %d\n", shmid);
// 3. 将共享内存映射到当前进程的地址空间
shm_ptr = (struct shared_data *)shmat(shmid, NULL, 0);
if (shm_ptr == (void *)-1) {
perror("shmat failed");
exit(EXIT_FAILURE);
}
// 4. 从共享内存读取数据(循环直到收到exit信号)
while (1) {
// 等待写入方产生数据
while (shm_ptr->flag == 0) {
sleep(1); // 无数据,等待
}
// 读取并处理数据
printf("Reader: 收到消息: %s\n", shm_ptr->message);
// 检查是否退出
if (strcmp(shm_ptr->message, "exit") == 0) {
break;
}
shm_ptr->flag = 0; // 标记数据已读取
sleep(1); // 模拟处理时间
}
// 5. 解除共享内存映射
if (shmdt(shm_ptr) == -1) {
perror("shmdt failed");
exit(EXIT_FAILURE);
}
printf("Reader: 已解除共享内存映射\n");
// 6. 删除共享内存(释放资源)
if (shmctl(shmid, IPC_RMID, NULL) == -1) {
perror("shmctl failed");
exit(EXIT_FAILURE);
}
printf("Reader: 已删除共享内存\n");
return 0;
}
发送方:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <unistd.h>
// 共享内存中存储的数据结构
struct shared_data {
int flag; // 用于同步:0表示无数据,1表示有数据
char message[256]; // 存储的消息
};
int main() {
key_t key;
int shmid;
struct shared_data *shm_ptr;
// 1. 创建唯一的键值(ftok根据文件和项目ID生成)
key = ftok("shm_file", 65); // 当前目录需有shm_file文件,可touch创建
if (key == -1) {
perror("ftok failed");
exit(EXIT_FAILURE);
}
// 2. 创建共享内存(大小为struct shared_data,权限0666)
shmid = shmget(key, sizeof(struct shared_data), IPC_CREAT | 0666);
if (shmid == -1) {
perror("shmget failed");
exit(EXIT_FAILURE);
}
printf("Writer: 共享内存创建成功,ID = %d\n", shmid);
// 3. 将共享内存映射到当前进程的地址空间
shm_ptr = (struct shared_data *)shmat(shmid, NULL, 0);
if (shm_ptr == (void *)-1) {
perror("shmat failed");
exit(EXIT_FAILURE);
}
// 4. 向共享内存写入数据(循环3次)
for (int i = 0; i < 3; i++) {
// 等待读取方处理完上一条数据
while (shm_ptr->flag == 1) {
sleep(1); // 有数据未读取,等待
}
// 写入数据
snprintf(shm_ptr->message, sizeof(shm_ptr->message),
"这是第 %d 条消息:Hello from Writer!", i + 1);
shm_ptr->flag = 1; // 设置标志:数据已就绪
printf("Writer: 已写入消息: %s\n", shm_ptr->message);
sleep(2); // 模拟处理时间
}
// 5. 发送结束信号
while (shm_ptr->flag == 1) sleep(1);
strcpy(shm_ptr->message, "exit");
shm_ptr->flag = 1;
// 6. 解除共享内存映射
if (shmdt(shm_ptr) == -1) {
perror("shmdt failed");
exit(EXIT_FAILURE);
}
printf("Writer: 已解除共享内存映射\n");
// (此处不删除共享内存,由reader删除)
return 0;
}
四、消息队列(Message Queues)
消息队列是内核维护的链表结构,进程可按类型发送 / 接收消息(结构化数据)。
- 特点:
- 消息有类型和数据字段,支持按类型读取(避免管道的字节流无序问题);
- 生命周期由内核管理(进程退出后消息可保留);
- 相比管道,适合多进程间的复杂通信(如客户端 - 服务器模型)。
- 不足:数据大小有限制(内核参数限制),效率低于共享内存。
msg_receiver.c:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/ipc.h>
#include <sys/msg.h>
#include <unistd.h>
// 与发送端保持一致的消息结构体
struct msg_buffer {
long msg_type; // 消息类型
char msg_text[1024]; // 消息内容
};
int main() {
key_t key;
int msgid;
struct msg_buffer message;
// 1. 生成与发送端相同的键值
key = ftok("msg_file", 65);
if (key == -1) {
perror("ftok failed");
exit(EXIT_FAILURE);
}
// 2. 获取已创建的消息队列
msgid = msgget(key, 0666);
if (msgid == -1) {
perror("msgget failed");
exit(EXIT_FAILURE);
}
printf("Receiver: 成功连接消息队列,ID = %d\n", msgid);
// 3. 循环接收消息(只接收类型1的消息)
printf("Receiver: 开始接收类型1的消息...\n");
while (1) {
// msgrcv的第4个参数指定接收类型:1表示只接收类型1的消息
msgrcv(msgid, &message, sizeof(message.msg_text), 1, 0);
printf("Receiver: 收到类型1消息: %s\n", message.msg_text);
// 检查退出条件
if (strcmp(message.msg_text, "exit") == 0) {
break;
}
}
// 4. 删除消息队列(释放资源)
if (msgctl(msgid, IPC_RMID, NULL) == -1) {
perror("msgctl failed");
exit(EXIT_FAILURE);
}
printf("Receiver: 消息队列已删除\n");
return 0;
}
msg_sender.c:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/ipc.h>
#include <sys/msg.h>
#include <unistd.h>
// 消息结构体(必须以long型开头,用于指定消息类型)
struct msg_buffer {
long msg_type; // 消息类型(正数)
char msg_text[1024]; // 消息内容
};
int main() {
key_t key;
int msgid;
struct msg_buffer message;
// 1. 生成唯一键值(与接收端使用相同的文件和项目ID)
key = ftok("msg_file", 65);
if (key == -1) {
perror("ftok failed");
exit(EXIT_FAILURE);
}
// 2. 创建或获取消息队列(0666表示读写权限)
msgid = msgget(key, 0666 | IPC_CREAT);
if (msgid == -1) {
perror("msgget failed");
exit(EXIT_FAILURE);
}
printf("Sender: 消息队列创建成功,ID = %d\n", msgid);
// 3. 发送不同类型的消息
// 发送类型1的消息(普通文本)
message.msg_type = 1;
strcpy(message.msg_text, "这是类型1的普通消息");
msgsnd(msgid, &message, sizeof(message.msg_text), 0);
printf("Sender: 发送类型1消息: %s\n", message.msg_text);
sleep(1);
// 发送类型2的消息(警告信息)
message.msg_type = 2;
strcpy(message.msg_text, "这是类型2的警告消息");
msgsnd(msgid, &message, sizeof(message.msg_text), 0);
printf("Sender: 发送类型2消息: %s\n", message.msg_text);
sleep(1);
// 发送类型1的退出消息
message.msg_type = 1;
strcpy(message.msg_text, "exit");
msgsnd(msgid, &message, sizeof(message.msg_text), 0);
printf("Sender: 发送类型1退出消息\n");
return 0;
}
五、信号量(Semaphores)
信号量是用于进程同步与互斥的计数器,不直接传递数据,而是控制对共享资源的访问。
- 互斥:确保同一时间只有一个进程访问共享资源(如用二元信号量
0/1实现锁); - 同步:协调多个进程的执行顺序(如生产者 - 消费者模型中控制缓冲区访问)。
sem_consumer.c:
#include <stdio.h>
#include <stdlib.h>
#include <sys/ipc.h>
#include <sys/sem.h>
#include <sys/shm.h>
#include <unistd.h>
// 复用与生产者相同的信号量操作函数
void sem_op(int semid, int semnum, int op) {
struct sembuf sb;
sb.sem_num = semnum;
sb.sem_op = op;
sb.sem_flg = 0;
semop(semid, &sb, 1);
}
// 与生产者相同的共享缓冲区结构体
#define BUFFER_SIZE 5
struct shared_buffer {
int data[BUFFER_SIZE];
int in;
int out;
};
int main() {
key_t key;
int semid, shmid;
struct shared_buffer *buf;
// 1. 使用与生产者相同的键值
key = ftok("sem_file", 66);
if (key == -1) {
perror("ftok failed");
exit(EXIT_FAILURE);
}
// 2. 获取已创建的信号量和共享内存
semid = semget(key, 3, 0666);
if (semid == -1) {
perror("semget failed");
exit(EXIT_FAILURE);
}
shmid = shmget(key, sizeof(struct shared_buffer), 0666);
if (shmid == -1) {
perror("shmget failed");
exit(EXIT_FAILURE);
}
buf = (struct shared_buffer *)shmat(shmid, NULL, 0);
// 3. 消费者逻辑:循环消费5个数据
for (int i = 0; i < 5; i++) {
// 等待满缓冲区(sem2减1,若为0则阻塞)
sem_op(semid, 2, -1);
// 获取互斥锁(sem0减1,确保独占缓冲区)
sem_op(semid, 0, -1);
// 从缓冲区读取数据
int data = buf->data[buf->out];
printf("消费者: 从位置 %d 读取数据 %d\n", buf->out, data);
buf->out = (buf->out + 1) % BUFFER_SIZE; // 循环移动读取位置
// 释放互斥锁(sem0加1)
sem_op(semid, 0, 1);
// 增加空缓冲区计数(sem1加1,唤醒生产者)
sem_op(semid, 1, 1);
sleep(2); // 模拟消费耗时
}
// 4. 清理资源(删除共享内存和信号量)
shmdt(buf);
shmctl(shmid, IPC_RMID, NULL);
semctl(semid, 0, IPC_RMID);
printf("消费者: 完成消费,释放资源\n");
return 0;
}
sem_producer.c:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/ipc.h>
#include <sys/sem.h>
#include <sys/shm.h>
#include <unistd.h>
// 定义信号量操作函数
void sem_op(int semid, int semnum, int op) {
struct sembuf sb;
sb.sem_num = semnum; // 信号量编号
sb.sem_op = op; // 操作:+1释放,-1获取
sb.sem_flg = 0; // 无特殊标志
semop(semid, &sb, 1); // 执行操作
}
// 共享缓冲区结构体
#define BUFFER_SIZE 5
struct shared_buffer {
int data[BUFFER_SIZE]; // 缓冲区数据
int in; // 写入位置
int out; // 读取位置
};
int main() {
key_t key;
int semid, shmid;
struct shared_buffer *buf;
// 1. 创建唯一键值(与消费者共享)
key = ftok("sem_file", 66);
if (key == -1) {
perror("ftok failed");
exit(EXIT_FAILURE);
}
// 2. 创建3个信号量:
// sem0: 互斥锁(0/1,控制缓冲区互斥访问)
// sem1: 空缓冲区数量(初始=BUFFER_SIZE,生产者等待)
// sem2: 满缓冲区数量(初始=0,消费者等待)
semid = semget(key, 3, IPC_CREAT | 0666);
if (semid == -1) {
perror("semget failed");
exit(EXIT_FAILURE);
}
// 初始化信号量值
semctl(semid, 0, SETVAL, 1); // 互斥锁初始为1(可用)
semctl(semid, 1, SETVAL, BUFFER_SIZE); // 空缓冲区初始为5
semctl(semid, 2, SETVAL, 0); // 满缓冲区初始为0
// 3. 创建共享内存(存储缓冲区)
shmid = shmget(key, sizeof(struct shared_buffer), IPC_CREAT | 0666);
if (shmid == -1) {
perror("shmget failed");
exit(EXIT_FAILURE);
}
buf = (struct shared_buffer *)shmat(shmid, NULL, 0);
buf->in = 0;
buf->out = 0;
// 4. 生产者逻辑:循环生产5个数据
for (int i = 0; i < 5; i++) {
int data = i + 100; // 生产的数据(100, 101, ..., 104)
// 等待空缓冲区(sem1减1,若为0则阻塞)
sem_op(semid, 1, -1);
// 获取互斥锁(sem0减1,确保独占缓冲区)
sem_op(semid, 0, -1);
// 写入数据到缓冲区
buf->data[buf->in] = data;
printf("生产者: 写入数据 %d 到位置 %d\n", data, buf->in);
buf->in = (buf->in + 1) % BUFFER_SIZE; // 循环移动写入位置
// 释放互斥锁(sem0加1)
sem_op(semid, 0, 1);
// 增加满缓冲区计数(sem2加1,唤醒消费者)
sem_op(semid, 2, 1);
sleep(1); // 模拟生产耗时
}
// 5. 清理资源(保持共享内存,由消费者最后删除)
shmdt(buf);
printf("生产者: 完成生产,退出\n");
return 0;
}
六、套接字(Sockets)
- 支持 TCP(可靠、面向连接)和 UDP(不可靠、无连接)协议;
- 本地进程通信可使用
AF_UNIX域套接字(效率高于网络套接字); - 是网络编程的基础(如客户端与服务器通信)。
| 通信方式 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| 管道 / 命名管道 | 简单数据传输、亲缘 / 非亲缘进程 | 实现简单 | 半双工、数据无序 |
| 信号 | 异步通知(如异常处理) | 实时性高 | 携带信息少 |
| 共享内存 | 高频、大数据量通信 | 效率最高 | 需手动同步 |
| 消息队列 | 结构化数据、多进程复杂通信 | 按类型读取、持久化 | 数据大小有限制 |
| 信号量 | 同步与互斥 | 控制资源访问 | 不传递数据 |
| 套接字 | 跨网络或本地进程通信 | 通用、支持网络 | 协议开销(本地通信可优化) |
串口通信空闲中断:
本质是检测串口是否处于空闲状态,串口通信在接收完一阵状态下,检测在一帧数据时间内,如果没有接收到新的信息,就会产生中断,通常用于不定长帧格式的数据,配合DMA使用
串口通信接收中断:
接收到一帧数据之后,就会产生一次中断,告诉cpu我接收到一帧数据。
自旋锁和互斥锁:
自旋锁:
自旋锁适用于持有锁线程所需要的时间较短的场景,且持有锁的线程不可以进入阻塞,否则会产生类似死锁的现象(死锁:多个进程因互相等待对方资源而形成的永久阻塞状态)。等待锁的线程会一直忙等,不进入阻塞。
互斥锁:
与自旋锁不同的是,等待锁的线程不会处于忙等状态,会进入阻塞状态,等下一次起来在读取是否有资源。
项目里的udp通信协议你是怎么实现的,应用了哪些函数
创建套接字 → 绑定端口(可选,通常服务器必做) → 发送 / 接收数据 → 关闭套接字
int sockfd = socket(AF_INET, SOCK_DGRAM, 0);//创建udp套接字
bind(sockfd, (struct sockaddr*)&local_addr, sizeof(local_addr));//绑定地址和端口
recvfrom(sockfd, recv_buf, BUF_SIZE-1, 0,(struct sockaddr*)&client_addr, &client_addr_len);//UDP服务器接收数据
inet_ntop(AF_INET, &client_addr.sin_addr, client_ip, INET_ADDRSTRLEN);
sendto(sockfd, reply, strlen(reply), 0,(struct sockaddr*)&client_addr, client_addr_len);//发送数据
close(sockfd);//关闭socket
GPIO 的输出速度,它决定了 GPIO 引脚从高电平切换到低电平(或反之)的最大翻转速率
U-Boot的基本概念与作用:
U-Boot(Universal Boot Loader)是一个开源的、跨平台的引导加载程序,主要用于嵌入式系统。其主要作用包括:
- 硬件初始化:初始化CPU、内存控制器、时钟等关键硬件
- 加载操作系统:将存储设备中的操作系统内核加载到内存并执行
- 提供命令行界面:允许用户通过串口等接口与系统交互
- 环境变量管理:存储和管理系统启动参数
- 外设驱动支持:提供基本的外设驱动,如网络、存储设备等
- 系统恢复机制:提供系统恢复和固件更新功能
uboot启动流程:
大致流程:硬件复位 → 汇编初始化(关看门狗/中断、时钟/DDR初始化、搬移自身) → C语言初始化(外设/环境变量/存储设备) → 加载并启动内核
- 第一阶段(SPL/TPL):执行最小化硬件初始化设置时钟和内存控制器加载主U-Boot镜像到RAM
- 第二阶段(主U-Boot):完成更全面的硬件初始化设置内存映射初始化串口等通信设备初始化环境变量显示启动信息
- 命令处理阶段:检查自动启动倒计时如果倒计时中断,进入命令行界面否则,执行预设的启动命令
- 操作系统加载阶段:从指定存储设备加载内核镜像准备内核启动参数跳转到内核入口点执行
U-Boot支持哪些网络功能?如何使用网络加载内核?
支持的网络协议:
- TFTP:用于文件传输
- NFS:网络文件系统
- DHCP:动态主机配置
- BOOTP:引导协议
- ARP:地址解析协议
网络相关环境变量:
- serverip:服务器IP地址
- ipaddr:本机IP地址
- gatewayip:网关IP地址
- netmask:子网掩码
- ethaddr:MAC
通过 TFTP 加载 Linux 内核的核心步骤是:搭建 TFTP 服务器 → 配置 U-Boot 网络 → 下载内核和设备树到内存 → 启动内核。这种方式无需烧写 Flash,适合频繁调试内核的场景,配合 NFS 挂载根文件系统可大幅提高开发效率。
Linux移植流程:
硬件分析 → 环境搭建(工具 + 源码) → Bootloader 适配 → 内核配置与设备树编写 → 根文件系统构建 → 烧写调试 → 外设完善。
Linux启动流程:
链接脚本指定入口stext(head.S)→stext汇编初始化(CPU 检查、页表创建、MMU 使能)→__mmap_switched跳转至start_kernel(C 层总初始化)→rest_init创建核心进程(PID1 init、PID2 kthreadd)→init进程(kernel_init)(设备初始化、挂载根文件系统、运行用户 init)→用户空间启动完成
Linux内核启动流程:
先找到Linux的入口地址,入口地址在链接脚本vmlinux.lds中定义
启动前在启动之前,确保MMU,D-cache,I-cache关闭,R0寄存器置空,R1寄存器存入机器ID,用于标识硬件平台型号,R2寄存器存放设备树指针地址
阶段一:汇编层初始化(检查硬件兼容性、准备内存映射环境、为 C 语言运行铺路)
具体步骤:
1、确保 CPU 处于SVC 模式(超级用户模式,拥有最高权限),并关闭所有中断(避免初始化被中断打断),为后续操作提供稳定环境。
2、读CPU ID,获取当前CPU硬件标识,在kernel预设的proc数组中匹配CPU,匹配成功的话,就返回该CPU的procinfo结构体(MMU flags、缓存操作函数),存入R5寄存器中。
3、验证R2寄存器中的dtb合法性,如果出现异常,则后续内核可能无法获取硬件资源。
4、创建临时页表,为后续 “使能 MMU” 做准备(MMU 需要页表实现 “物理地址→虚拟地址” 映射),仅映射内核代码段、数据段和关键硬件寄存器地址,无需完整映射所有内存(后续会扩展)
5、最终调用start_kernel,调用(CPU结构体)procinfo中预设的 CPU 初始化函数(如缓存控制器配置、MMU 准备),使能 MMU,CPU 开始使用虚拟地址,MMU 使能完成后,自动跳转到r13存储的__mmap_switched,进入 C 层初始化。
阶段二:C 语言层内核层初始化
start_kernel是内核 C 层的 “总入口”,相当于内核的 “main 函数”,会调用数十个初始化函数,完成:
1、内存管理子系统初始化(如页表扩建、内存分配器buddy初始化);
2、中断控制器初始化(GIC初始化,使能中断响应)
3、进程调度器初始化()
4、虚拟文件系统初始化(VFS)(为后续挂在根文件系统做准备)
5、调用rest_init,进入“核心进程初始化”阶段
阶段三:核心进程创建
rest_init的核心目标是 “创建 Linux 系统的 3 个核心进程”,奠定系统进程模型
1、启动 RCU 锁调度器(Read-Copy-Update,内核并发控制机制),为多核环境下的进程同步提供支持。
2、创建PID=1 的 init 进程(kernel_init),核心任务:完成设备驱动初始化、挂载根文件系统、启动用户空间的 init 程序。
3、创建PID=2 的 kthreadd 进程,负责创建和调度所有内核线程(如 I/O 线程、定时器线程)。
4、初始化并启动idle 进程(空闲进程)(当前进程,PID=0),CPU 空闲时运行的 “空闲进程”,优先级最低,仅在无其他进程可调度时执行。
阶段四、衔接用户空间,kernel_init函数
kernel_init是 PID=1 的 init 进程的核心逻辑,目标是 “完成内核到用户空间的过渡”,分为 “前期初始化” 和 “启动用户空间 init 程序” 两部分:
前期初始化:
1、wait_for_completion(&kthreadd_done) 等待 kthreadd 进程完全就绪,避免 init 进程创建内核线程时 kthreadd 未初始化。
2、smp_init() → sched_init_smp() 初始化 SMP(对称多处理):唤醒多核 CPU(如 ARM Cortex-A7 的其他核心);初始化多核进程调度逻辑,确保多核心能协同工作。
3、调用driver_init,初始化内核驱动模型子系统(如 platform 总线、USB 总线),遍历并初始化所有已注册的设备驱动(如 GPIO、UART、存储控制器驱动),让硬件具备工作能力。
4、初始化系统控制台:打开/dev/console(由 Bootloader 的bootargs指定,如console=ttymxc0,115200对应串口 1),文件描述符为0(标准输入);
5、挂载根文件系统:读取bootargs中的root参数(如root=/dev/mmcblk1p2表示根文件系统在 EMMC 分区 2);初始化存储设备(如 EMMC、SD 卡),挂载根文件系统(如 ext4 格式),让内核能访问用户空间的文件。
启动用户空间 init 程序:init 进程的最终目标是启动用户空间的init程序(系统第一个用户进程)

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









