




 这篇博客详细介绍了如何使用Halcon进行深度学习分类任务的数据准备,包括设置输入输出路径、参数配置、数据集划分、预处理步骤以及预处理数据的查看。通过read_dl_dataset_classification和split_dl_dataset创建并分割数据集,然后利用create_dl_prepeocess_param和preprocess_dl_dataset进行预处理,最后通过get_dict_tuple和find_dl_samples等函数对预处理数据进行展示。整个流程覆盖了从数据准备到预处理的完整过程,对于理解Halcon的深度学习应用非常有帮助。
这篇博客详细介绍了如何使用Halcon进行深度学习分类任务的数据准备,包括设置输入输出路径、参数配置、数据集划分、预处理步骤以及预处理数据的查看。通过read_dl_dataset_classification和split_dl_dataset创建并分割数据集,然后利用create_dl_prepeocess_param和preprocess_dl_dataset进行预处理,最后通过get_dict_tuple和find_dl_samples等函数对预处理数据进行展示。整个流程覆盖了从数据准备到预处理的完整过程,对于理解Halcon的深度学习应用非常有帮助。
学习halocon自带的分类学习的例子:
创建网络和数据预处理
训练网络
评估训练的效果
测试新图像
①设置输入输出路径:1.分类图像数据路径RawImageBaseFolder 2.设置样本数据文件夹ExampleDataDir
②设置参数:LabelSource/TraningPercent/ValidationPercent/ImageWidth/ImageHeight/ImageNumChannels/NormalizationType/DomainHanding 为了设置可再生或者说可复制的分割我们需要设置一个随机种子。(这意味着重新运行脚本将导致DLDataset的相同拆分。)
③读取标记数据,分割成train, validation and test:
read_dl_dataset_classification (RawImageBaseFolder, LabelSource, DLDataset) 产生一个用来分类DLDataset数据集字典。
RawImageFolder是包含图像的文件夹的元组。这些文件夹中的所有图像及其子文件夹都添加到词典DLDataset中
LabelSource确定用于提取图像基本真值标签的模式。
告诉字典里面的东西,样本路径/分类的名字/标签ID等。这个算子的目的就是根据输入的样本的路径,得到样本的字典。
在Halcon里面这个DLDataset内部结构是这个样子的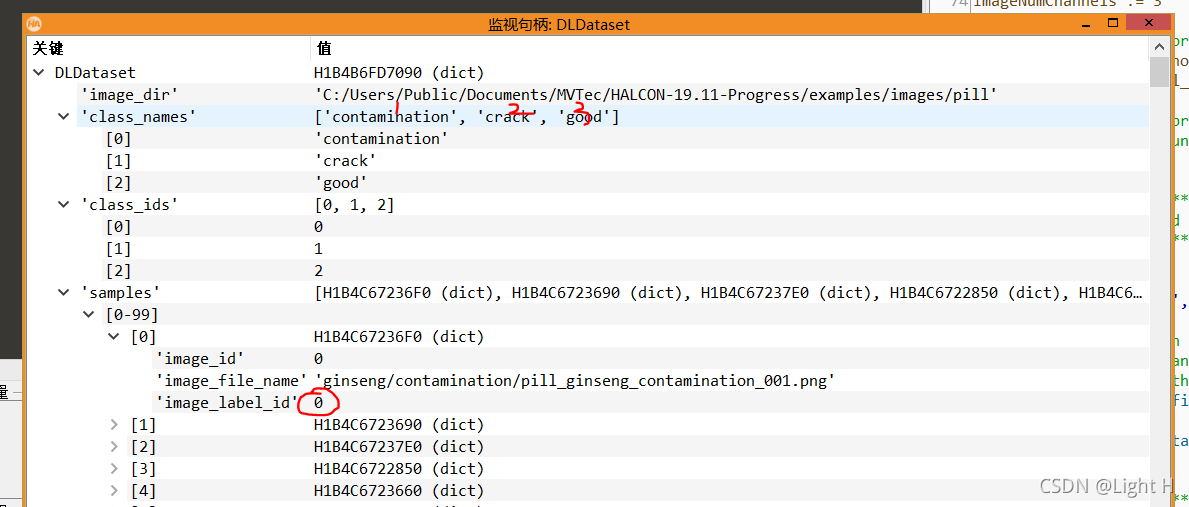
split_dl_dataset (DLDataset, TrainingPercent, ValidationPercent, [])分割数据集
④预处理数据集
1.判断存不存
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7261
7261

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









