




 本文深入探讨了支配树算法,包括直观的节点删除法、数据流迭代算法、Lengauer-Tarjan算法及SEMI-NCA算法。重点讲解了LT算法中的semidominator概念及其计算方法,以及SEMI-NCA算法如何结合NCA优化LT算法。
本文深入探讨了支配树算法,包括直观的节点删除法、数据流迭代算法、Lengauer-Tarjan算法及SEMI-NCA算法。重点讲解了LT算法中的semidominator概念及其计算方法,以及SEMI-NCA算法如何结合NCA优化LT算法。
文章目录
我在《 构造Dominator Tree以及Dominator Frontier》介绍了支配树的相关概念以及它如何参与到SSA的构造过程中,但是在那一篇文章中我只介绍了cooper的基于数据流迭代的算法,但是在工程中还有一些其它的算法,例如llvm最早使用的 Lengauer-Tarjan algorithm 和2017年使用的 SEMI-NCA algorithm。

注:上图来源于《Finding Dominators in Flowgraphs Linear-Time Algorithm 1 and Experimental Study 2: Loukas Georgiadis》
Vertex-removal Algorithm
最直观的方法是节点删除法。例如在删除节点
w
w
w之前,
v
v
v不可达,但是删除
w
w
w后,
v
v
v不可达,我们就说
w
w
w支配
v
v
v。

注:上述算法来自于http://www.cs.au.dk/~gerth/advising/thesis/henrik-knakkegaard-christensen.pdf
The Iterative Algorithm Revisit
数据流迭代的算法的核心是下面的方程式
D
o
m
(
r
o
o
t
)
=
r
o
o
t
Dom(root) = {root}
Dom(root)=root。
D
o
m
′
(
v
)
=
(
⋂
v
∈
p
r
e
d
(
v
)
D
o
m
′
(
u
)
)
⋃
v
,
∀
v
∈
V
−
r
Dom^{'}(v) = (\bigcap_{v\in pred(v)} Dom^{'}(u)) \bigcup {v}, \forall v \in V - r
Dom′(v)=(v∈pred(v)⋂Dom′(u))⋃v,∀v∈V−r
Finally, for any subset U ⊆ V U \subseteq V U⊆V and a tree T T T, N C A ( T , U ) NCA(T, U) NCA(T,U) denotes the nearest common ancestor of U ⋂ T U \bigcap T U⋂T in T T T.
我们使用学到的数据流知识对这个方程式进行分析,首先它是一个MUST分析。
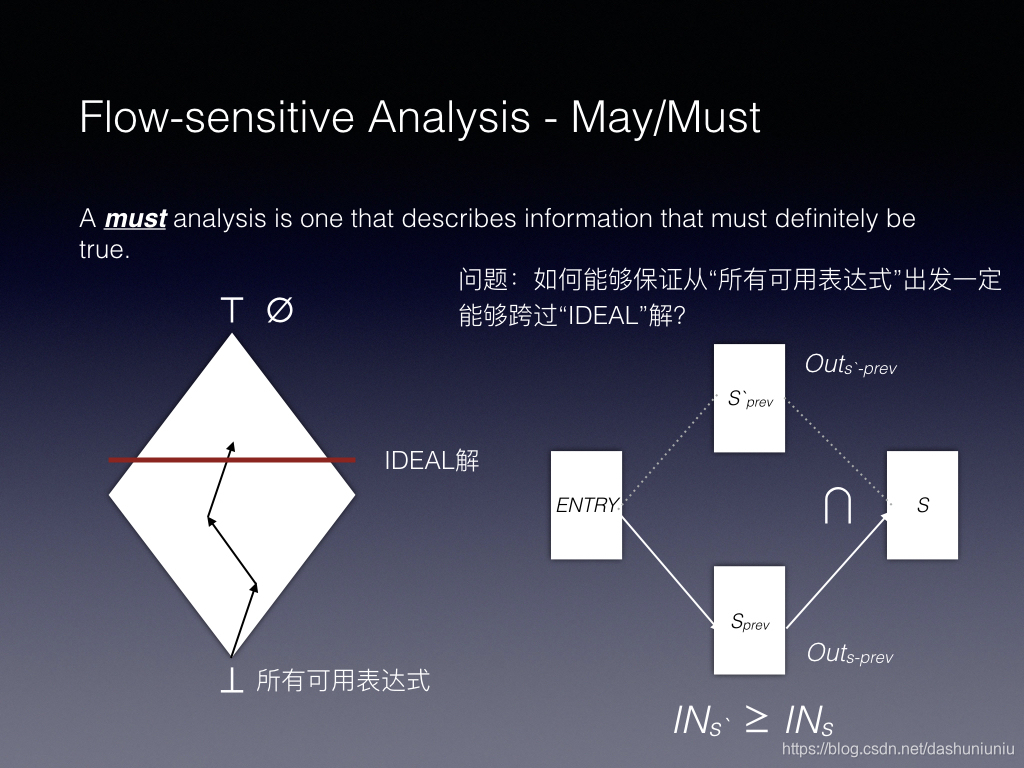
所以对应的算法如下。

注:上述算法来自于Cooper
Cooper对这种传统的基于迭代数据流计算 D o m Dom Dom set的方法进行了总结。
This algorithm produces correct results because the equations for Dom, as shown above, form a distributive data-flow framework as defined by Kam and Ullman [20]. Thus, we know that the iterative algorithm will discover the maximal fixed-point solution and halt. Since the framework is distributive, we know that the maximal fixed-point solution is identical to the meet-over-all paths solution—which matches the definition of Dom.
对于上面的描述,稍微岔开一下话题,介绍其中的几个关键点。因为有很多学习数据流分析的同学对这几个概念理解不是很透彻。
Distributive Data-Flow Framework

注:上图来源于#55 Distributive Framework for Data Flow Analysis
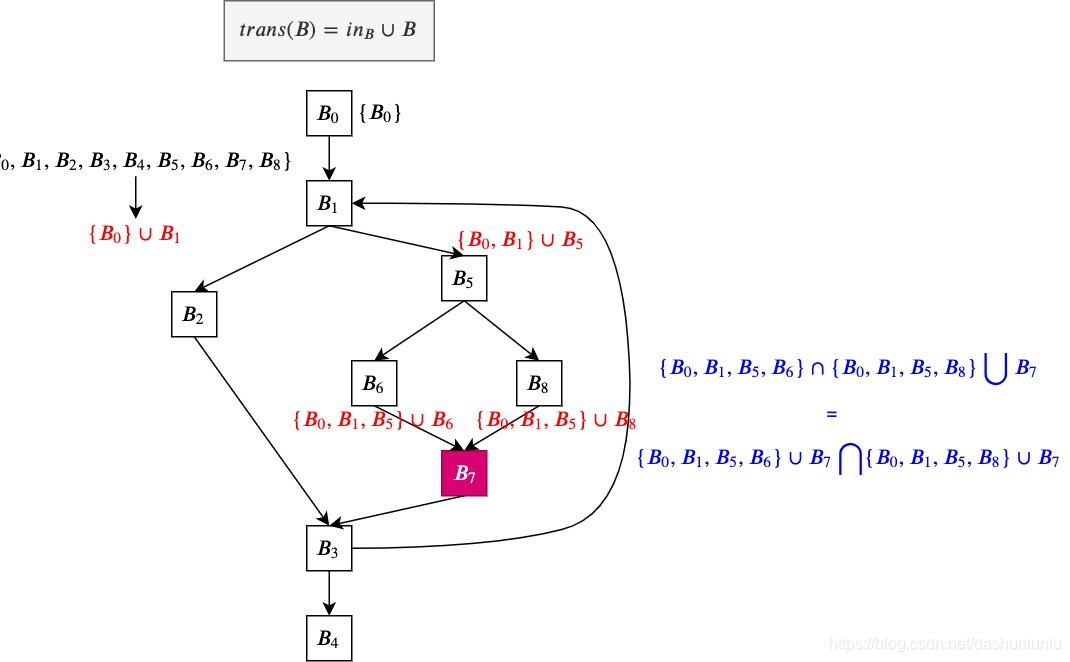
其实最开始的方程式分为两部分,
- 一部分是control flow equotion,也就是 i n B = ⋂ v ∈ p r e d ( B ) D o m ′ ( B ) in_B = \bigcap_{v\in pred(B)} Dom^{'}(B) inB=⋂v∈pred(B)Dom′(B)
- 一部分是data flow equotion,也就是 o u t B = i n B ∪ B out_B = in_B \cup B outB=inB∪B
我们能明显看到
t
r
a
n
s
B
trans_B
transB是distribute的,如下图所示。
Distributive Framework最好的地方是能够保证 MFP解 = MOP解。
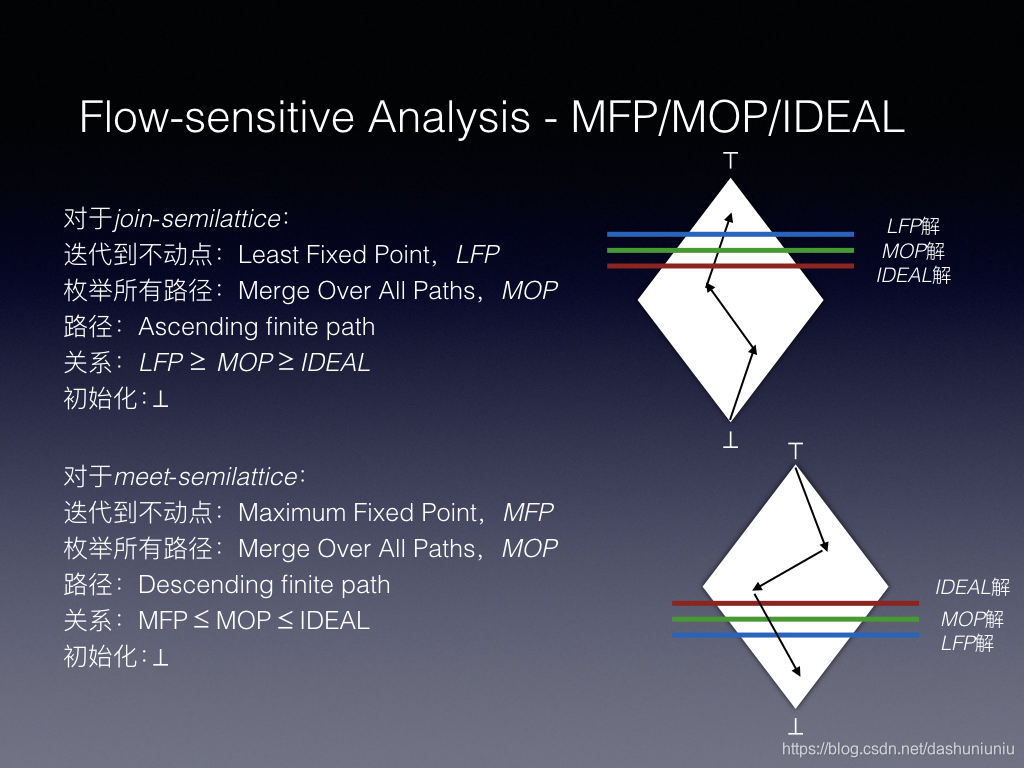
未来我再找机会解释
M
O
P
MOP
MOP解为什么能够保证
s
o
u
n
d
sound
sound。相关文章数据流分析中的Distributive Dataflow Problems
而Cooper对实现方式进行了改进,但是并没有改变数据流迭代的本质。可以参照构造Dominator Tree以及Dominator Frontier。主要是抽象出了dominator tree的概念,然后使用一个array存储了所有的dominator信息。
To improve the iterative algorithm’s performance, we need a memory-efficient data structure that supports a fast intesection.
Lengauer-Tarjan Algorithm Revisit
首先介绍一下Lengauer-Tarjan algorithm,我在《构造Dominator Tree以及Dominator Frontier》中提到过这个算法,但是当时我没有看懂,取而代之介绍了《Engineering a Compiler》中提到的迭代数据流的算法A Simple, Fast Dominance Algorithm。
LT算法基于下面已有的三个概念:
- preorder depth first search
- spanning tree
- immediate dominator
LT算法首先前序深度优先遍历Graph,然后给每个符号编号,如下图所示:
注:上图源于http://www.cse.unt.edu/~sweany/CSCE5934/HANDOUTS/LengaurTarjanOverheads.pdf
由于前序深度优先遍历得到的编号,LT算法创造了一个新的概念 s e m i d o m i n a t o r semidominator semidominator,简称为 s d o m ( w ) sdom(w) sdom(w)。 s d o m sdom sdom可以看做是对 i d o m idom idom的一种逼近。
s d o m ( w ) sdom(w) sdom(w) = m i n min min { v v v | there is a path v = v 0 , v 1 , . . . , v k = w v = v_0, v_1, ..., v_k = w v=v0,v1,...,vk=w such that v i > w v_i > w vi>w for 1 ≤ i ≤ k − 1 1 \le i \le k -1 1≤i≤k−1}
注:注意 i i i的范围, s d o m ( w ) sdom(w) sdom(w)一定是 w w w在spanning tree上的ancestor
A semidominator for a vertex v v v in a Graph G G G is an ancestor of v v v in a DFS tree T T T of G G G and is used as an approximation of the immediate dominator of v v v. - 《Algorithms for Finding Dominators in Directed Graphs》
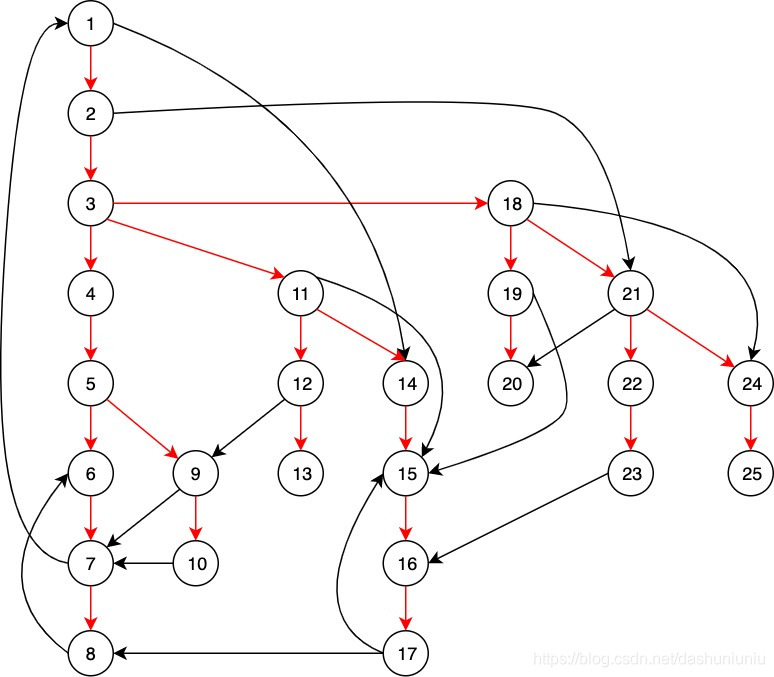
例如要计算sdom(15),最小的值为2,下图中加粗的路径表示这条路径。其实除了这条路径之外,还有
- 14 → 15 14 \rightarrow 15 14→15
- 11 → 15 11 \rightarrow 15 11→15
- 3 → 18 → 19 → 15 3 \rightarrow 18 \rightarrow 19 \rightarrow 15 3→18→19→15
- … 其实
19
→
15
19 \rightarrow 15
19→15也算,但是既然找
m
i
n
min
min值,所以我只把值得考虑的列了上来。
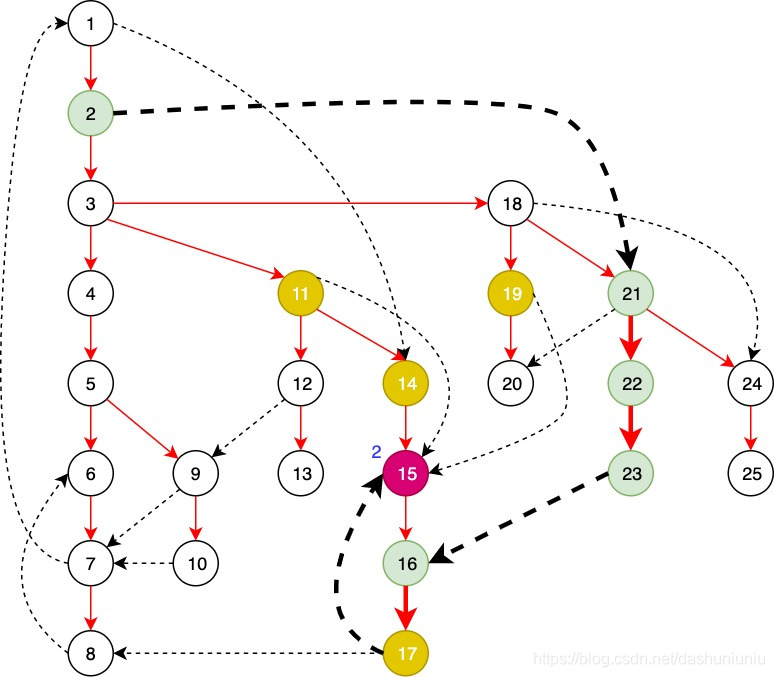
注:我把非spanning tree的边描成了虚线
如果我们把所有节点的 s d o m sdom sdom值列出来的话,如下图所示。我们可以发现对于大部分节点来说, s d o m sdom sdom和 i d o m idom idom值都相同。而7、15、16、24的 s d o m sdom sdom和 i d o m idom idom不相同,而导致不相同的路线我都用绿色加粗标识了出来。
- 7 7 7 的 s d o m sdom sdom 是3, i d o m idom idom 是1。
- 15 15 15 的 s d o m sdom sdom 是2, i d o m idom idom 是1。
- 16 16 16 的 s d o m sdom sdom 是2, i d o m idom idom 是1。
- 24 24 24 的 s d o m sdom sdom 是18, i d o m idom idom 是2
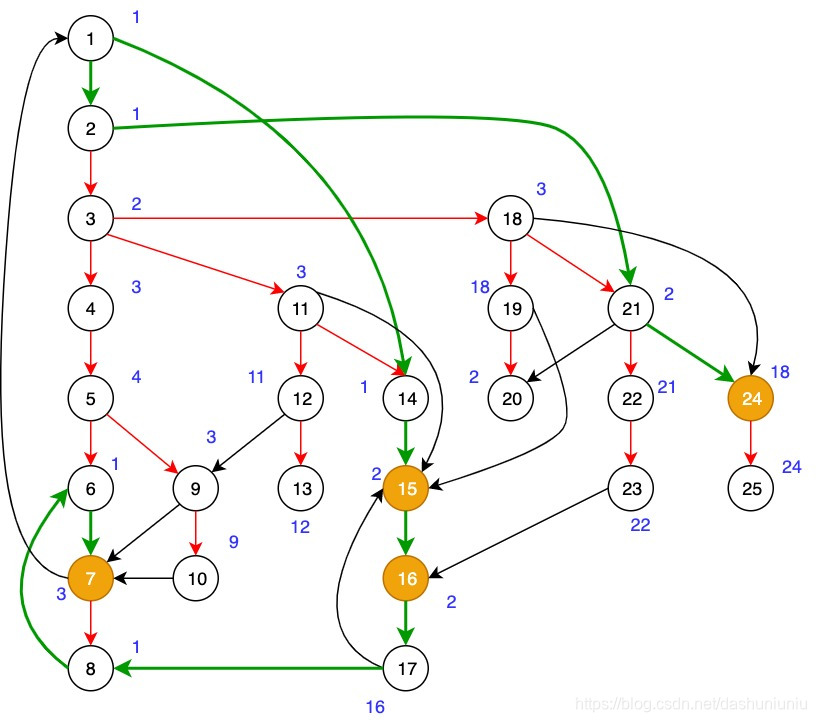
所以这里有以下两个问题:
- 如何 s d o m → i d o m sdom \rightarrow idom sdom→idom
- 如何计算 s d o m sdom sdom
为了解决上述的两个问题,我们先列出以下几个核心事实:
- If w ≠ r w \neq r w=r is any vertex, then s d o m ( w ) sdom(w) sdom(w) is a proper ancestor of w w w in T T T.
- i d o m ( w ) idom(w) idom(w) is a (not necessarily proper) ancestor of s d o m ( w ) sdom(w) sdom(w).
- If we replace the set of nontree edges of G G G by the set of edges { ( s d o m ( w ) , w ) ∣ w ∈ V a n d w ≠ r } \{(sdom(w), w) | w \in V and\ w \neq r\} {(sdom(w),w)∣w∈Vand w=r}, then the dominators of vertices in G G G are unchanged.
- Thus if we know the spanning tree and the semidominators, we can compute the dominators.
注:上面的 T T T表示的是深度优先遍历得到的spanning tree, G G G表示原始的图
为了解决上述两个问题,给出四个个引理:
LEMMA 2. For any vertex
w
≠
r
w \neq r
w=r,
i
d
o
m
(
w
)
→
+
w
idom(w) \stackrel{+}\rightarrow w
idom(w)→+w
LEMMA 3. For any vertex
w
≠
r
w \neq r
w=r,
s
d
o
m
(
w
)
→
+
w
sdom(w) \stackrel{+}\rightarrow w
sdom(w)→+w
LEMMA 4. For any vertex
w
≠
r
w \neq r
w=r,
i
d
o
m
(
w
)
→
∗
s
d
o
m
(
w
)
idom(w) \stackrel{*}\rightarrow sdom(w)
idom(w)→∗sdom(w)
LEMMA 5. For any vertices
v
v
v,
w
w
w satisfy
v
→
∗
w
v \stackrel{*}\rightarrow w
v→∗w. Then
v
→
∗
i
d
o
m
(
w
)
v \stackrel{*}\rightarrow idom(w)
v→∗idom(w) or
i
d
o
m
(
w
)
→
∗
i
d
o
m
(
v
)
idom(w) \stackrel{*}\rightarrow idom(v)
idom(w)→∗idom(v)
通过Lemma 5,我们就可以通过 semidominators 计算 immediate dominators 。
THEOREM 2. Let w ≠ r w \neq r w=r. Suppose every u u u for which s d o m ( w ) → + u → ∗ w sdom(w) \stackrel{+}\rightarrow u \stackrel{*}\rightarrow w sdom(w)→+u→∗w satifies s d o m ( u ) ≥ s d o m ( w ) sdom(u) \ge sdom(w) sdom(u)≥sdom(w). Then i d o m ( w ) = s d o m ( w ) idom(w) = sdom(w) idom(w)=sdom(w).
THEOREM 3. Let w ≠ r w \ne r w=r and let u u u be a vertex for which s d o m ( u ) sdom(u) sdom(u) is minimum among vertices u u u satisfying s d o m ( w ) → + u → ∗ w sdom(w) \stackrel{+}\rightarrow u \stackrel{*}\rightarrow w sdom(w)→+u→∗w. Then s d o m ( u ) ≤ s d o m ( w ) sdom(u) \le sdom(w) sdom(u)≤sdom(w) and i d o m ( u ) = i d o m ( w ) idom(u) = idom(w) idom(u)=idom(w).
COROLLARY 1. Let w ≠ r w \ne r w=r and let u u u be a vertex for which s d o m ( u ) sdom(u) sdom(u) is minimum among vertices u u u satisfying s d o m ( w ) → + u → ∗ w sdom(w) \stackrel{+}\rightarrow u \stackrel{*}\rightarrow w sdom(w)→+u→∗w. Then
i d o m ( w ) = { s d o m ( w ) if sdom(w) = sdom(u) i d o m ( u ) otherwise idom(w) = \begin{cases} sdom(w) \ \ \ \ \text{if sdom(w) = sdom(u)} \\ idom(u) \ \ \ \ \text{otherwise} \end{cases} idom(w)={sdom(w) if sdom(w) = sdom(u)idom(u) otherwise
具体实现
DFS
第一步深度优先遍历得到一个DFS Tree,并给各个节点标preorder number。
计算semidominators
首先,深度优先遍历Graph给各个节点标 preorder 序号。然后以reverse preorder的方式处理每一个节点,因为根据 s d o m ( v ) sdom(v) sdom(v)的定义,我们需要考虑一些order大于 v v v 的节点的信息,以reverse order的方式处理的话,每当我们处理一个节点时,所需要的信息已经准备好了。
- 对于节点 v v v来说,我们可以轻松找到所有 predecessor 中小于 v v v的节点中最小的那一个。例如最开始图中的节点15,它有两个predecessor小于15,分别是11和14,我们可以很轻松的得到11是这些predecessor中最小的一个。
- 收集predecessor序号大于 v v v的的path。假设predecessor为 q q q, q q q的semidominator path为 ( v 0 , v 1 , . . . , v k = q ) (v_0, v_1, ..., v_k = q) (v0,v1,...,vk=q), q > v q \gt v q>v,我们需要通过这些 q q q的 s d o m ( q ) sdom(q) sdom(q)值计算 s d o m ( v ) sdom(v) sdom(v)。如果 v 0 > v v_0 \gt v v0>v,那么递归地找 s d o m ( s d o m ( . . . ( s d o m ( v 0 ) ) ) sdom(sdom(...(sdom(v_0))) sdom(sdom(...(sdom(v0))),直到找到一个 v i < v v_i \lt v vi<v。
- 最终求1和2中的最小值。
如果对于下图来说,假设我们需要计算 s d o m ( 15 ) sdom(15) sdom(15),我们已经收集到
- predecessor值小于 15 15 15的有 11 11 11, 14 14 14
- 对于predecessor 19 19 19, s d o m ( s d o m ( 19 ) ) = 3 sdom(sdom(19))=3 sdom(sdom(19))=3
- 对于predecessor 17 17 17, s d o m ( s d o m ( 17 ) ) = 2 sdom(sdom(17))=2 sdom(sdom(17))=2
- m i n ( 11 , 14 , 3 , 2 ) = 2 min(11, 14, 3, 2) = 2 min(11,14,3,2)=2
注:predecessor对应于Graph,parent对应于Tree
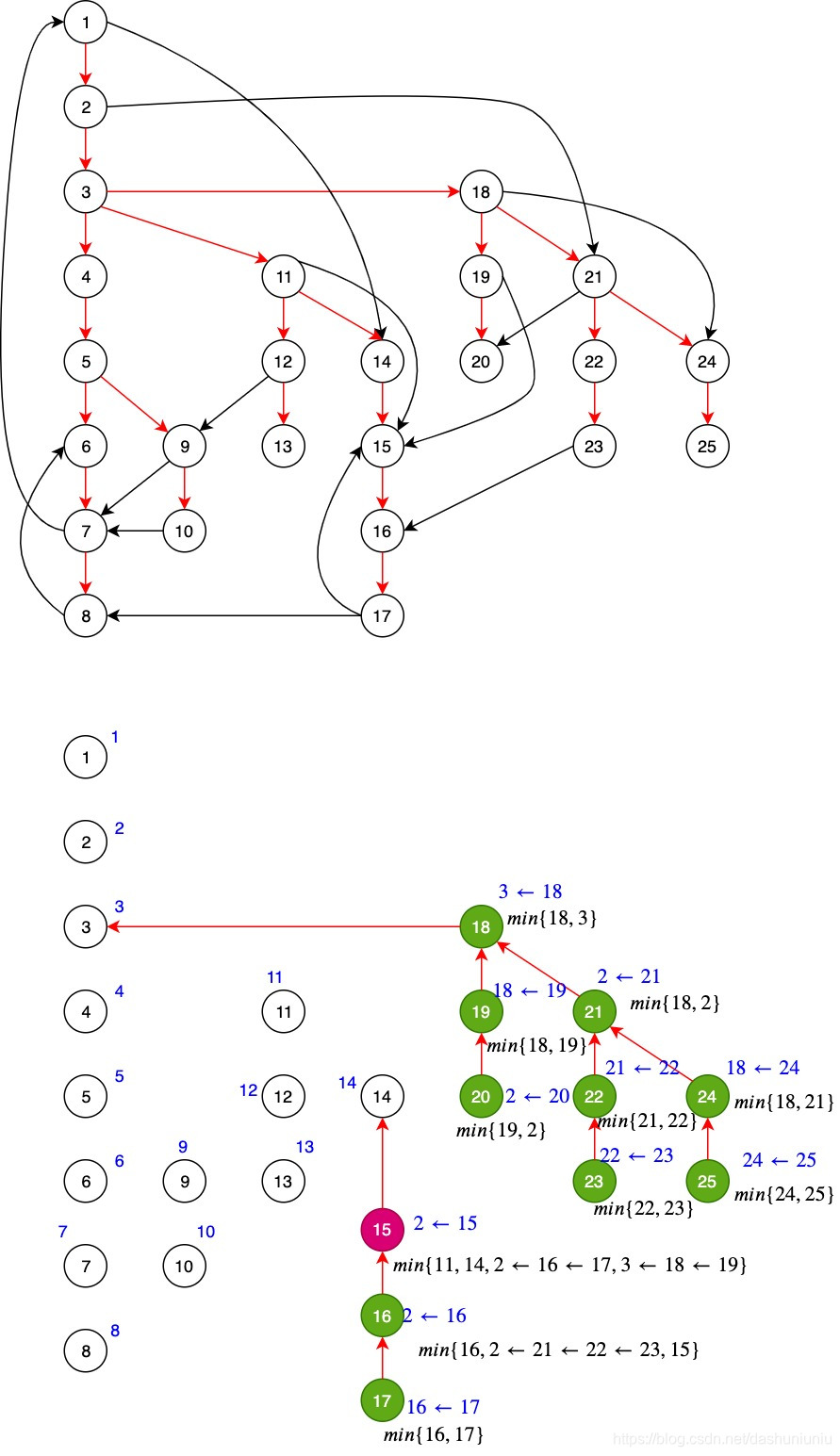
整体算法框架如下图所示:

注:上图来源于http://www.cs.au.dk/~gerth/advising/thesis/henrik-knakkegaard-christensen.pdf
eval & link

注:上图来源于《Finding Dominators in Flowgraphs Linear-Time Algorithm and Experimental Study》
在实现过程中,还是但很多可以优化的点。
计算 i d o m idom idom
前面我们已经计算得到了各个节点的 s d o m sdom sdom,而且根据COROLLARY 1,我们已经知道什么情况下 s d o m sdom sdom等于 i d o m idom idom,什么情况下 i d o m idom idom需要通过 s d o m sdom sdom推导出来。
我们重新回顾一下前面介绍的几条定理,
THEOREM 2. Let
w
≠
r
w \neq r
w=r. Suppose every
u
u
u for which
s
d
o
m
(
w
)
→
+
T
u
→
∗
T
w
sdom(w) \stackrel{+}\rightarrow_T u \stackrel{*}\rightarrow_T w
sdom(w)→+Tu→∗Tw satifies
s
d
o
m
(
u
)
≥
s
d
o
m
(
w
)
sdom(u) \ge sdom(w)
sdom(u)≥sdom(w). Then
i
d
o
m
(
w
)
=
s
d
o
m
(
w
)
idom(w) = sdom(w)
idom(w)=sdom(w).
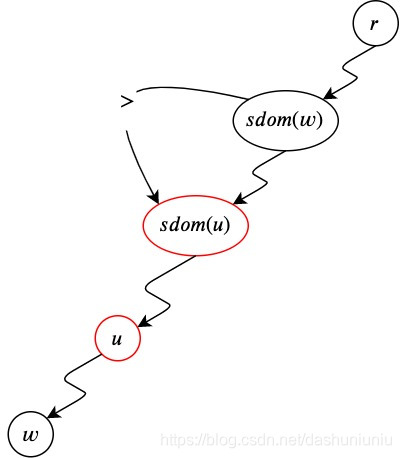
类似于下图中的节点
9
9
9,
s
d
o
m
(
9
)
=
3
→
T
4
→
T
5
→
T
9
sdom(9)=3 \rightarrow_T 4 \rightarrow_T 5 \rightarrow_T 9
sdom(9)=3→T4→T5→T9,其中
s
d
o
m
(
4
)
=
3
<
s
d
o
m
(
9
)
sdom(4)=3 \lt sdom(9)
sdom(4)=3<sdom(9),
s
d
o
m
(
5
)
=
4
<
s
d
o
m
(
9
)
sdom(5)=4 \lt sdom(9)
sdom(5)=4<sdom(9),所以
i
d
o
m
(
9
)
=
s
d
o
m
(
9
)
idom(9) = sdom(9)
idom(9)=sdom(9)。
THEOREM 3. Let w ≠ r w \ne r w=r and let u u u be a vertex for which s d o m ( u ) sdom(u) sdom(u) is minimum among vertices u u u satisfying s d o m ( w ) → + T u → ∗ T w sdom(w) \stackrel{+}\rightarrow_T u \stackrel{*}\rightarrow_T w sdom(w)→+Tu→∗Tw. Then s d o m ( u ) ≤ s d o m ( w ) sdom(u) \le sdom(w) sdom(u)≤sdom(w) and i d o m ( u ) = i d o m ( w ) idom(u) = idom(w) idom(u)=idom(w).
对于定理3,可以参见上图中的节点 16 16 16, s d o m ( 16 ) = 2 → T 3 → T 11 → T 14 → T 15 → T 16 sdom(16)=2 \rightarrow_T 3 \rightarrow_T 11 \rightarrow_T 14 \rightarrow_T 15 \rightarrow_T 16 sdom(16)=2→T3→T11→T14→T15→T16。 i d o m ( 16 ) = m i n { s d o m ( 3 ) = 2 , s d o m ( 11 ) = 3 , s d o m ( 14 ) = 1 } = 1 idom(16) = min\{sdom(3)=2,sdom(11)=3, sdom(14)=1 \} = 1 idom(16)=min{sdom(3)=2,sdom(11)=3,sdom(14)=1}=1。注意这两个定理中的 path 不是 semidominator path,二是在 spanning tree中的path。
整个LT算法如下图所示:


注:上图中算法来自于http://www.cs.au.dk/~gerth/advising/thesis/henrik-knakkegaard-christensen.pdf
LT算法真的是复杂的一批。核心思想是求得 i d o m idom idom的逼近值 s d o m sdom sdom,然后基于 s d o m sdom sdom,根据不同的情况推导出 i d o m idom idom,算法细节见《Algorithms for Finding Dominators in Directed Graphs》。
The SEMI-NCA Algorithm
从算法的名字我们可以看出来,这个算法是 semidominator + nearest common ancestor(NCA) 组合起来的。
这个算法使用LT算法的前半部分,也就是计算 s d o m sdom sdom的部分。而后半部分使用下面的引理计算 i d o m idom idom。它核心思想是,在 preorder 的方式遍历DFS spanning tree,以递增的方式创建dominator tree D D D。
Lemma 1: For any vertex v ≠ s v \ne s v=s is the nearest common ancestor in D D D for s d o m ( v ) sdom(v) sdom(v) and p a r e n t T ( v ) parent_T(v) parentT(v):
i d o m ( v ) = N C A D ( p a r e n t T ( v ) , s d o m ( v ) ) idom(v) = NCA_D(parent_T(v), sdom(v)) idom(v)=NCAD(parentT(v),sdom(v))
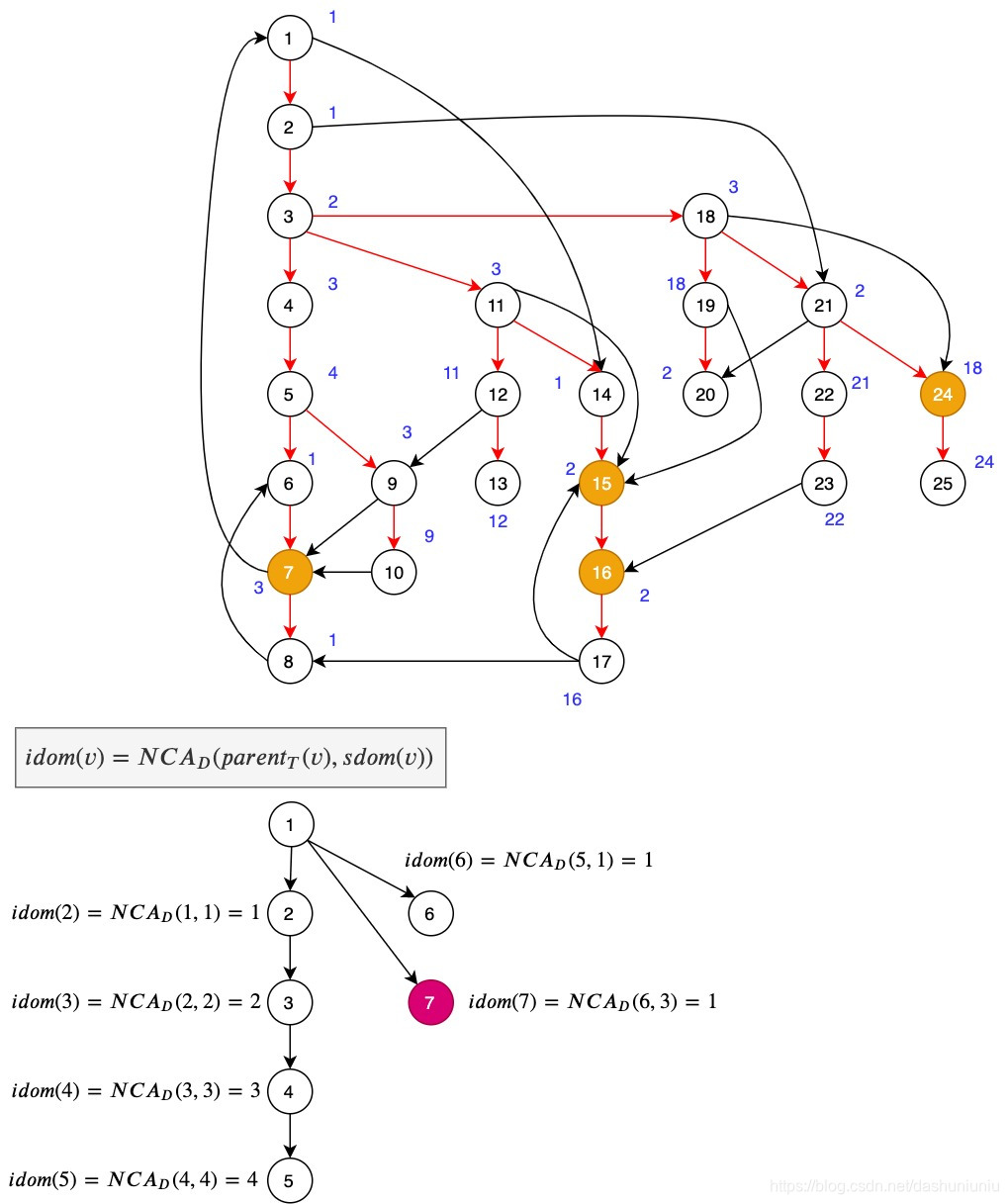
如上图中的
7
7
7,
s
d
o
m
(
7
)
=
3
sdom(7) = 3
sdom(7)=3,那么
i
d
o
m
(
7
)
=
N
C
A
D
(
6
,
3
)
=
1
idom(7)=NCA_D(6, 3)=1
idom(7)=NCAD(6,3)=1。
整个算法过程如下图所示:

注:上图算法来自于Algorithms for Finding Dominators in Directed Graphs
我们可以看到SEMI-NCA比原始的LT算法好理解多了。llvm在2017年将LT算法替换为SEMI-NCA算法,具体的实现细节见视频《2017 LLVM Developers’ Meeting: J. Kuderski “Dominator Trees and incremental updates that transcend time》介绍了开发人员在应用SEMI-NCA算法时的方方面面。
当然dominator算法还有很多可以挖掘的细节,但是semi-nca算法看起来是当前比较稳定的最优选择的算法。
论文列表
- Algorithms for Finding Dominators in Directed Graphs
- https://renatowerneck.files.wordpress.com/2016/06/gwtta04-dominators.pdf
- https://www.cs.princeton.edu/courses/archive/fall03/cs528/handouts/a%20fast%20algorithm%20for%20finding.pdf
- https://www.cs.princeton.edu/courses/archive/spr11/cos423/Lectures/DominatorsA.pdf
- https://www.doc.ic.ac.uk/~livshits/classes/CO444H/reading/dom14.pdf
- Finding dominators revisited: Extended abstract
- Linear-Time Algorithms for Dominators and Related Problems
其中Loukas的《Linear-Time Algorithms for Dominators and Related Problems》和《Algorithms for Finding Dominators in Directed Graphs》的描述比较完整。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









