




【n8n教程】:HTML节点,轻松实现网页内容提取!
本教程将教你如何使用 n8n 的 HTML 节点轻松提取网页内容。HTML 节点是 n8n 中用于解析和提取 HTML 数据的核心工具,无需编写复杂代码,你就能通过简单的 CSS 选择器从任何网页中提取所需的数据。本教程包含三个主要操作、详细的实战案例,以及一个完整可执行的工作流代码。
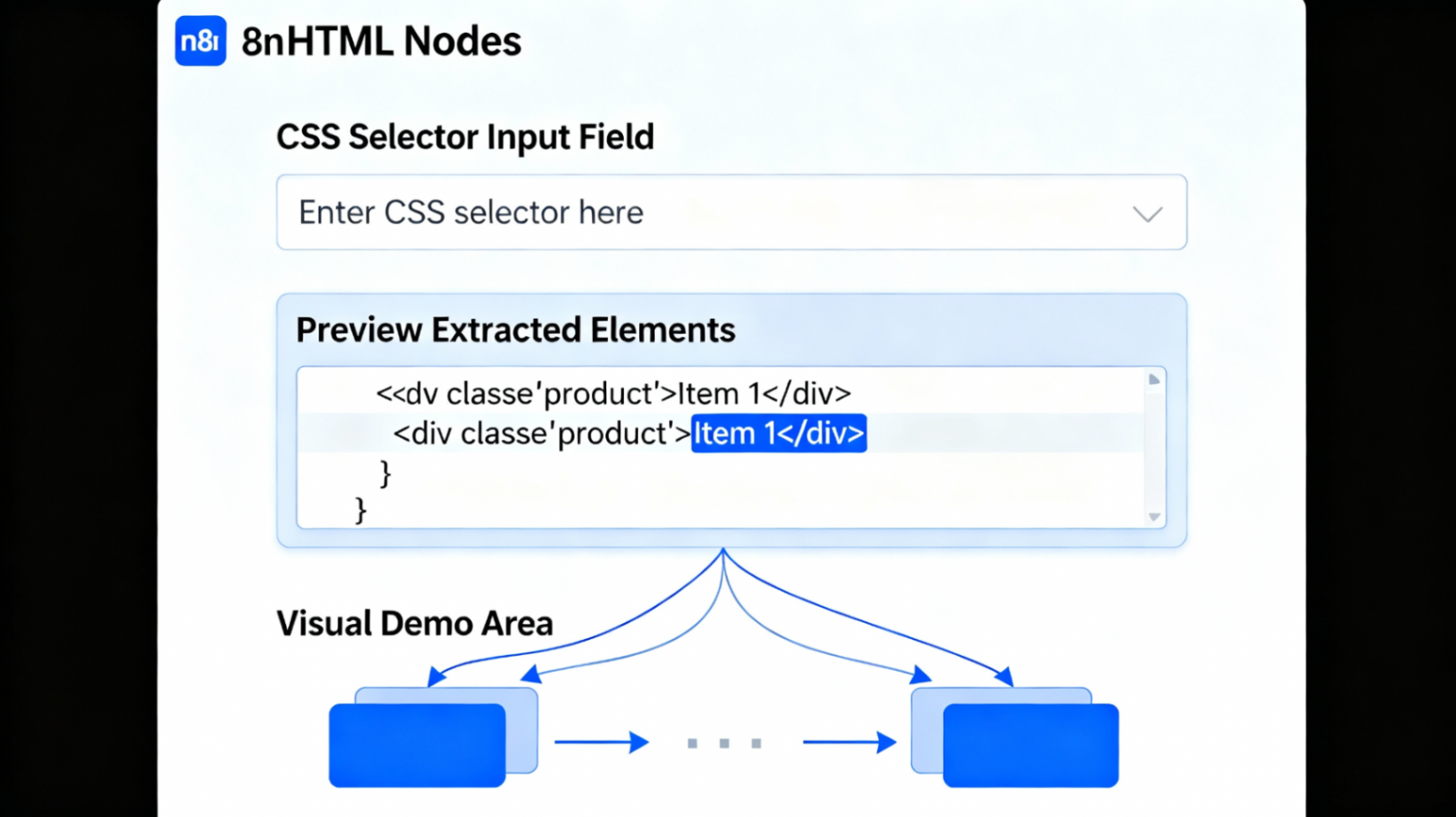
🎯 什么是 n8n HTML 节点?
HTML 节点是 n8n 内置的核心节点,用于处理 HTML 内容。它替代了旧版本中的"HTML 提取"节点,提供了更强大的功能。简单来说,HTML 节点的作用是:
- 从网页中提取数据:通过 CSS 选择器准确定位和提取网页中的特定内容
- 转换 HTML 为可用数据:将原始 HTML 转换为结构化的 JSON 数据
- 生成 HTML 模板:用数据动态生成 HTML 页面或邮件
- 转换为 HTML 表格:将数据快速转换为美观的 HTML 表格
应用场景:
- 📊 爬取电商网站的商品信息(名称、价格、评分)
- 📰 提取新闻网站的文章标题和摘要
- 💼 采集求职网站的招聘信息
- 📧 生成动态邮件内容
- 🔍 监控竞争对手的价格变化
🛠️ HTML 节点的三大核心操作
1️⃣ 提取 HTML 内容(Extract HTML Content)
这是最常用的操作,用来从 HTML 中提取特定的数据。该操作允许你使用 CSS 选择器从 HTML 源中精准定位并提取数据。
配置步骤:
| 参数 | 说明 | 示例 |
|---|---|---|
| 操作 | 选择"提取 HTML 内容" | Extract HTML Content |
| 源数据类型 | JSON 或二进制 | JSON(来自 HTTP 请求) |
| JSON 属性 | 指定包含 HTML 的字段名 | body(通常是 HTTP 返回的 body 字段) |
| 键(Key) | 提取结果的字段名 | title / price |
| CSS 选择器 | 用于定位元素 | .product-name 或 h1 |
| 返回值 | 提取什么内容 | Text(文本)/ HTML / Attribute(属性) |
| 返回数组 | 是否返回数组 | ✅ 启用(提取所有匹配项) |
如何找到正确的 CSS 选择器? 右键点击浏览器中要提取的元素,选择"检查"打开开发者工具。在高亮的 HTML 元素上右键,选择"复制" → “复制选择器”,然后粘贴到 n8n 的 CSS 选择器字段。
返回值类型详解:
- Text(文本):最常用,返回元素内的纯文本内容
- HTML:返回元素及其内部的完整 HTML 代码
- Attribute(属性):返回 HTML 元素的特定属性值(如 src、href)
- Value(值):用于 input、select、textarea 等表单元素
2️⃣ 生成 HTML 模板(Generate HTML Template)
用于动态生成 HTML 页面或邮件模板。你可以在模板中使用数据表达式,包括标准 HTML 标签、CSS 样式和 JavaScript 代码。
支持的内容:
- ✅ 标准 HTML 标签
- ✅ CSS 样式(在
<style>标签中) - ✅ JavaScript 代码(在
<script>标签中,但不执行) - ✅ 数据表达式(用
{{}}包装,调用 n8n 内置方法和变量)
简单示例:
<h1>{{$json.title}}</h1>
<p>价格:¥{{$json.price}}</p>
<div style="color: blue;">{{$json.description}}</div>
3️⃣ 转换为 HTML 表格(Convert to HTML Table)
快速将数据转换为格式化的 HTML 表格。该操作不需要配置参数,会自动处理任何来自前置节点的数据。
常用选项:
- 标头大小写:自动将表头转为大写
- 自定义样式:应用自定义 CSS 样式
- 标题:为表格添加标题文字
- 表格属性:设置表格样式(如 border、color 等)
💡 实战案例:提取电商网站商品信息
让我们通过一个真实案例来学习如何使用 HTML 节点提取网页数据。
目标
从网站上自动提取商品列表,包括商品名称、商品价格和商品评分。
工作流架构
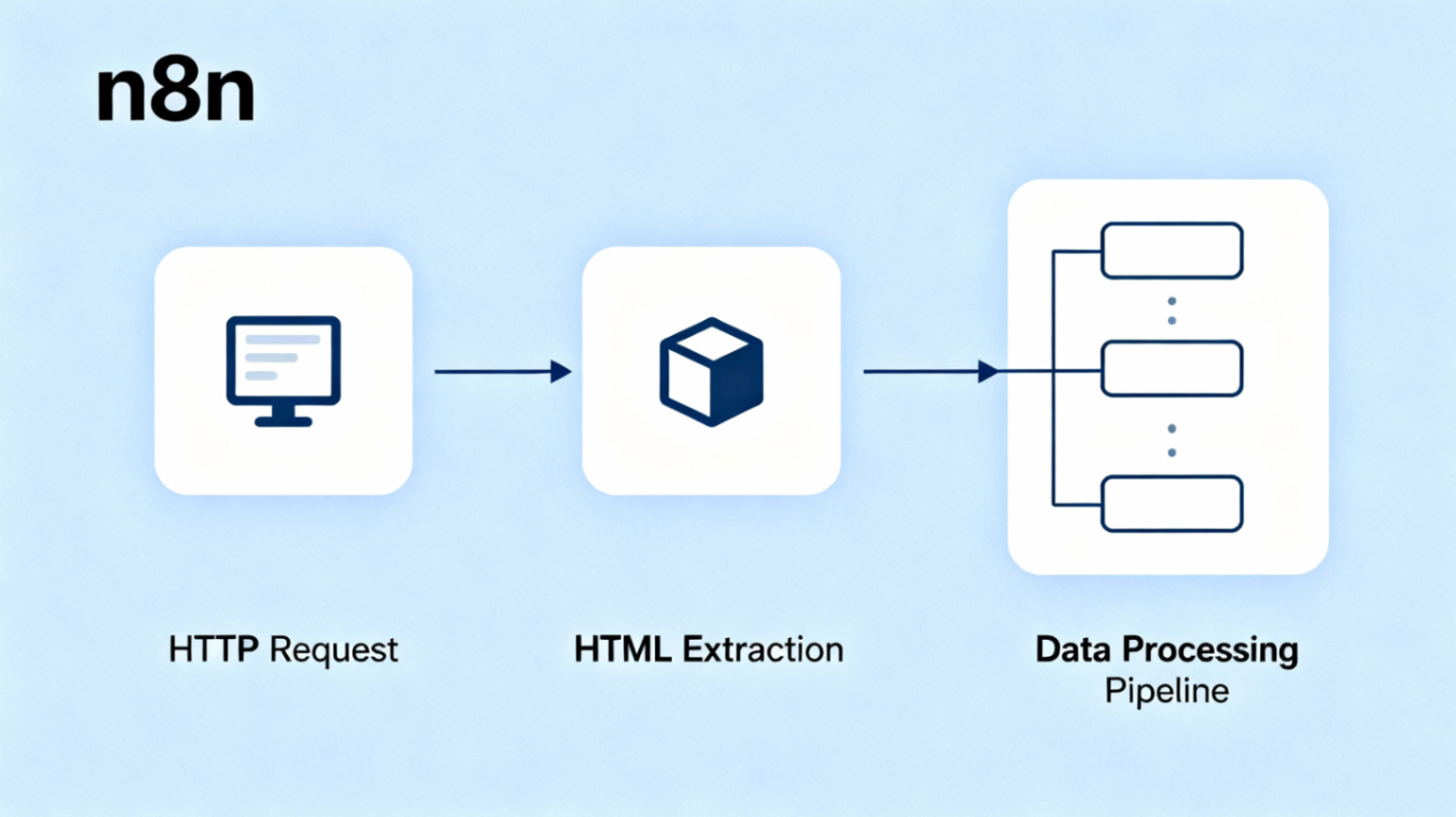
手动触发 → HTTP 请求 → HTML 提取 → 数据清理 → JSON 导出
详细步骤
第 1 步:添加触发节点 - 添加"手动触发"节点作为工作流的起点
第 2 步:获取网页 HTML - 添加 HTTP 请求 节点,方法选择 GET,输入目标 URL(如 https://scrapeme.live/shop/)。如果遇到 403 错误,添加 User-Agent 请求头:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36
第 3 步:提取商品信息 - 添加 HTML 节点,操作选择"提取 HTML 内容",源数据为 JSON,JSON 属性为 body,然后添加提取规则:
| 键 | CSS 选择器 | 返回值 |
|---|---|---|
| name | .product-title | Text |
| price | .product-price | Text |
| rating | .star-rating | Attribute → data-rating |
第 4 步:启用数据数组 - 勾选"返回数组"选项,这样可以提取所有匹配的商品而非仅第一个
第 5 步:清理文本 - 启用"修剪值"移除多余的空格,启用"清理文本"规范化换行符和空格
第 6 步:导出数据 - 添加"转换为文件"节点,格式选择 JSON 或 CSV,执行工作流并下载结果
🚀 完整可执行工作流:自动化商品爬虫
下面是一个完整的可执行 n8n 工作流,你可以直接导入到你的 n8n 实例中使用:
{
"name": "网页爬虫:商品信息提取",
"nodes": [
{
"parameters": {},
"id": "82e3e47a-7e7e-4bc3-8c5f-7f1c2a3e4f5g",
"name": "Start",
"type": "n8n-nodes-base.start",
"typeVersion": 1,
"position": [250, 300]
},
{
"parameters": {
"method": "GET",
"url": "https://scrapeme.live/shop/",
"options": {}
},
"id": "a2b3c4d5-e6f7-8a9b-0c1d-2e3f4a5b6c7d",
"name": "HTTP 请求",
"type": "n8n-nodes-base.httpRequest",
"typeVersion": 4.1,
"position": [450, 300]
},
{
"parameters": {
"sourceData": "json",
"jsonProperty": "body",
"extractionValues": [
{
"key": "name",
"cssSelectorExtract": "h2 a",
"returnValue": "text",
"regex": ""
},
{
"key": "price",
"cssSelectorExtract": ".price",
"returnValue": "text",
"regex": ""
},
{
"key": "inStock",
"cssSelectorExtract": ".instock",
"returnValue": "text",
"regex": ""
}
],
"returnArray": true,
"trimValues": true,
"cleanUpText": true
},
"id": "b3c4d5e6-f7a8-9b0c-1d2e-3f4a5b6c7d8e",
"name": "HTML 提取",
"type": "n8n-nodes-base.html",
"typeVersion": 1,
"position": [650, 300]
},
{
"parameters": {
"mode": "each",
"expression": "={{ Object.assign({}, $json) }}"
},
"id": "c4d5e6f7-a8b9-0c1d-2e3f-4a5b6c7d8e9f",
"name": "设置字段",
"type": "n8n-nodes-base.set",
"typeVersion": 3.2,
"position": [850, 300]
},
{
"parameters": {
"fileFormat": "json",
"dataIsBase64": false
},
"id": "d5e6f7a8-b9c0-1d2e-3f4a-5b6c7d8e9f0a",
"name": "转换为 JSON 文件",
"type": "n8n-nodes-base.convertToFile",
"typeVersion": 1,
"position": [1050, 300]
}
],
"connections": {
"Start": {
"main": [[{"node": "HTTP 请求", "type": "main", "index": 0}]]
},
"HTTP 请求": {
"main": [[{"node": "HTML 提取", "type": "main", "index": 0}]]
},
"HTML 提取": {
"main": [[{"node": "设置字段", "type": "main", "index": 0}]]
},
"设置字段": {
"main": [[{"node": "转换为 JSON 文件", "type": "main", "index": 0}]]
}
},
"active": false,
"settings": {}
}
如何导入和使用这个工作流?
- 复制上面的 JSON 代码
- 进入你的 n8n 工作区
- 点击"新建工作流"
- 在工作流编辑器中,使用快捷键
Ctrl+V(或Cmd+V)粘贴 JSON - n8n 会自动解析并生成完整的工作流
- 点击"执行"运行工作流
- 在右侧输出面板查看结果
- 点击"下载"按钮下载提取的数据
工作流节点说明
| 节点 | 功能 | 说明 |
|---|---|---|
| Start | 触发点 | 手动启动工作流 |
| HTTP 请求 | 获取数据 | 向目标 URL 发送 GET 请求,获取原始 HTML |
| HTML 提取 | 解析数据 | 使用 CSS 选择器从 HTML 中提取名称、价格、库存状态 |
| 设置字段 | 数据处理 | 可选的数据转换步骤 |
| 转换为 JSON | 导出数据 | 将提取的数据转换为 JSON 格式并保存 |
🎓 初学者常见问题
Q1:什么是 CSS 选择器?
CSS 选择器是用来在 HTML 中找到特定元素的语法。常见类型包括:
.classname- 按 class 查找#id- 按 ID 查找tag- 按标签名查找tag.class- 按标签和 class 查找tag > child- 按子元素查找
Q2:如何处理分页网站?
使用 循环 节点配合动态 URL,通过递增 pageNumber 实现分页爬取
Q3:遇到 403 错误怎么办?
添加 User-Agent 请求头使请求看起来像来自真实浏览器。如果 User-Agent 不起作用,考虑使用代理或专门的爬虫 API 服务
Q4:如何提取动态加载的内容?
如果网页使用 JavaScript 动态加载,使用专门的爬虫 API(如 ScrapeNinja 或 Firecrawl)或浏览器自动化工具
Q5:可以提取多个属性吗?
可以!在"提取值"部分点击"添加值",为不同的数据字段添加多个 CSS 选择器规则
💪 进阶技巧
1. 使用"跳过选择器"排除不需要的元素
如果 CSS 选择器会匹配你不需要的元素,使用"跳过选择器"排除它们。例如提取文本时,可以跳过特定的 HTML 标签
2. 多步提取工作流
HTTP 请求 → HTML 提取(第一层) → Split Out → HTML 提取(第二层) → 数据清理
这样可以处理嵌套的 HTML 结构
3. 条件判断
使用 If 节点 根据提取结果进行条件判断,例如标记价格低于 100 元的商品为"便宜"
4. 自动化定时爬取
将工作流改为"定时触发"而非"手动触发",实现自动化爬虫
⚠️ 网页爬虫的最佳实践
- 尊重网站规则 - 检查
robots.txt和网站条款,不爬取受保护的数据 - 控制请求频率 - 使用 Wait 节点添加延迟,避免对服务器造成压力
- 添加错误处理 - 使用 Try-Catch 处理异常情况
- 轮换 IP - 对于大规模爬取,考虑使用代理服务
- 定期维护 - 网站设计变更时,更新 CSS 选择器


















 470
470

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












{kind=link}