




 文章介绍了如何利用Python进行多元回归分析,通过训练/测试法确定最佳拟合阶数,以提高模型在测试集上的R²分数。通过sklearn库计算拟合优度,并找到最优的多项式阶数来提升模型的表现。在示例中,数据集包括页面加载速度和购物金额,最终发现6阶多项式提供了最佳的拟合效果。
文章介绍了如何利用Python进行多元回归分析,通过训练/测试法确定最佳拟合阶数,以提高模型在测试集上的R²分数。通过sklearn库计算拟合优度,并找到最优的多项式阶数来提升模型的表现。在示例中,数据集包括页面加载速度和购物金额,最终发现6阶多项式提供了最佳的拟合效果。
0.理论
多元回归使用R²衡量整体的拟合度。R²的值越接近1,说明回归直线对观测值的拟合程度越好。拟合度r2计算公式:R2=ESS/TSS=1-RSS/TSS。
1.用训练/测试法找出拟合给定数据集的正确阶数
import matplotlib.pyplot as plt
import numpy as np
from pylab import *
# 生成随机种子
np.random.seed(2)
# 生成页面载入速度和购物金额
pageSpeeds = np.random.normal(3.0, 1.0, 100)
purchaseAmount = np.random.normal(50.0, 30.0, 100) / pageSpeeds
# 画散点图
scatter(pageSpeeds, purchaseAmount)
<matplotlib.collections.PathCollection at 0x1c9269b9570>

# 将80%的数据作为训练数据
trainX = pageSpeeds[:80]
testX = pageSpeeds[80:]
trainY = purchaseAmount[:80]
testY = purchaseAmount[80:]
x = np.array(trainX)
y = np.array(trainY)
# 8阶多项式
p = np.poly1d(np.polyfit(x, y, 8))
# 打印8阶多项式方程
print(np.poly1d(p))
8 7 6 5 4 3 2
0.734 x - 17.01 x + 165.7 x - 881.9 x + 2788 x - 5315 x + 5898 x - 3442 x + 838.4
# 训练集
trainX = np.array(trainX)
trainY = np.array(trainY)
# 8阶多项式
p = np.poly1d(np.polyfit(x, y, 8))
# 打印8阶多项式方程
print(np.poly1d(p))
# 画图
xp = np.linspace(0, 7, 100)
axes = plt.axes()
axes.set_xlim([0,7])
axes.set_ylim([0, 200])
# 散点图
plt.scatter(trainX, trainY)
# 拟合曲线
plt.plot(xp, p(xp), c='r')
plt.show()
8 7 6 5 4 3 2
0.734 x - 17.01 x + 165.7 x - 881.9 x + 2788 x - 5315 x + 5898 x - 3442 x + 838.4

# 查看测试集的拟合度
testx = np.array(testX)
testy = np.array(testY)
axes = plt.axes()
axes.set_xlim([0,7])
axes.set_ylim([0, 200])
plt.scatter(testx, testy)
plt.plot(xp, p(xp), c='r')
plt.show()
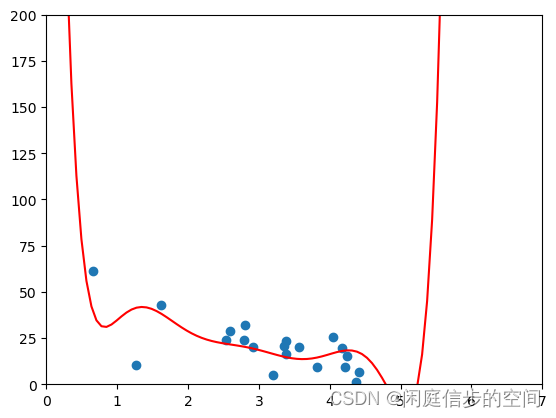
# 拟合优度
from sklearn.metrics import r2_score
print(r2_score(testy, p(testx)))
0.3001816861141787
# 寻找使拟合优度最高的N次方
def find_degree():
ans = []
# 训练集
X_train = np.array(trainX)
y_train = np.array(trainY)
# 测试集
X_test = np.array(testX)
y_test = np.array(testY)
for degree in range(1, 21):
# 拟合,得到N阶多项式方程
p = np.poly1d(np.polyfit(X_train, y_train, degree))
# 预测
y_pred = p(X_test)
# 拟合优度
r2 = r2_score(y_test, y_pred)
# 存入结果
ans.append((r2, degree))
ans.sort(reverse= True)
print('最优拟合优度为: {}\n最优阶数为: {}'.format(ans[0][0], ans[0][1]))
# 可视化,查看测试集的拟合度
axes = plt.axes()
axes.set_xlim([0,7])
axes.set_ylim([0, 200])
plt.scatter(X_test, y_test)
xp = np.linspace(0, 7, 100)
plt.plot(xp, p(xp), c='r')
plt.show()
find_degree()
最优拟合优度为: 0.6050119470355618
最优阶数为: 6
C:\Users\Administrator\AppData\Local\Temp\ipykernel_8636\1203016730.py:30: RankWarning: Polyfit may be poorly conditioned
find_degree()
C:\Users\Administrator\AppData\Local\Temp\ipykernel_8636\1203016730.py:30: RankWarning: Polyfit may be poorly conditioned
find_degree()
C:\Users\Administrator\AppData\Local\Temp\ipykernel_8636\1203016730.py:30: RankWarning: Polyfit may be poorly conditioned
find_degree()

2. 参考资料
Python数据科学与机器学习:从入门到实践
作者:
[美]弗兰克•凯恩(Frank Kane)

















 1870
1870

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









