






为什么做领域模型设计
传统开发模式为事务脚本模式,即面向过程编程,主要以贫血模型和过程范式为主。DDD即领域驱动设计模式倡导的是充血模型和对象范式,核心还是基于面向对象编程,是复杂业务逻辑的显性化表达
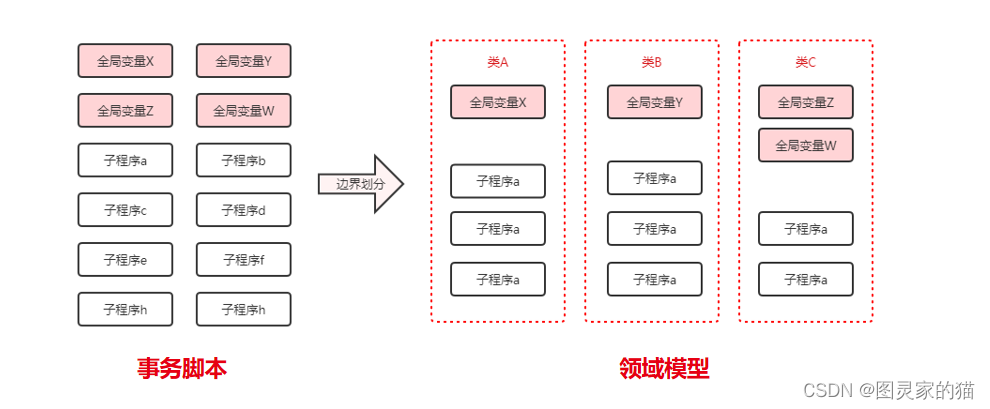
面向对象技术,相比较过程分解,可以减少构建数量,通过领域封装(对象封装、包封装、组件封装、服务封装......)的层级结构,把问题控制在可以理解的范围,而不至于失控
什么是领域驱动设计
领域驱动设计=对象建模+ER建模+微服务架构
关键概念
子域
整个领域拆分成多个子域,如订单、发票、库存、物流等
限界上下文
业务领域范围的描述,对于系统实现而言,相当于一个子系统或者一个模块
下图可以解释上述两者之间的关系:
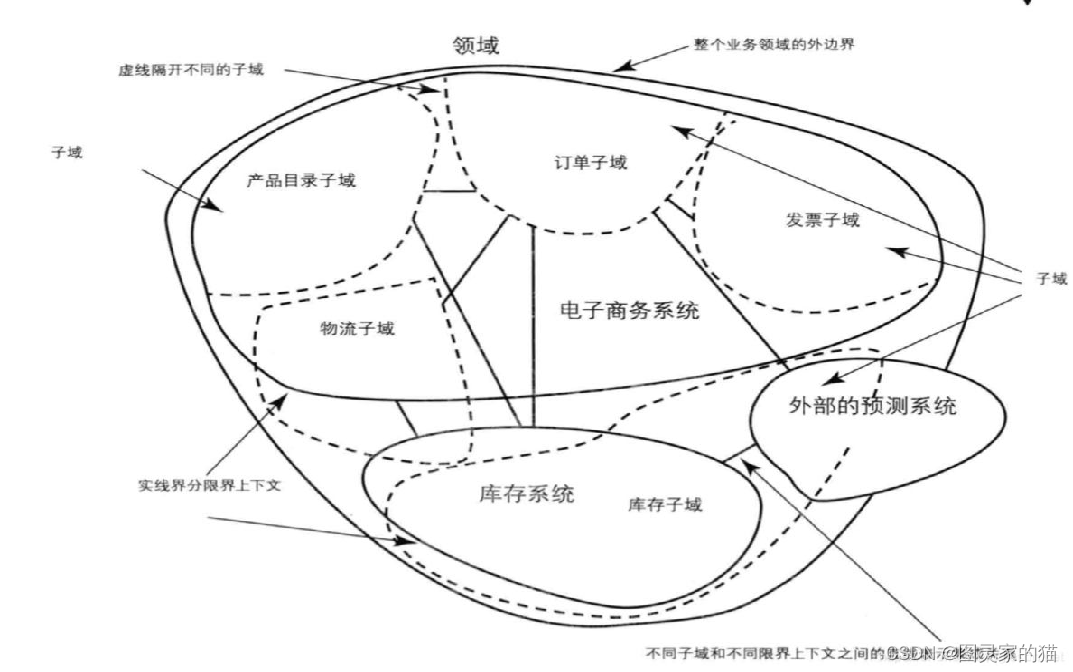
上下文映射
不同的限界上下文也就是不同子系统或模块之前,会有各种交互合作。如何设计这些交互合作呢?DDD使用了上下文映射来完成。共享内核和防腐层两种解决方案,是复用和解耦的权衡
实体
具有唯一标识的对象
值对象
度量或描述的对象,不变性。 只读,new而非set
聚合根
一个对象内聚的整体。每个聚合有一个根和一个边界,边界定义了一个聚合内部有哪些实体或值对象,根是聚合内有独立存在的意义并且可以和外部直接进行交互的实体
工厂
用来封装创建一个复杂对象尤其是聚合时所需的知识,工厂的作用是将创建对象的细节隐藏起来。可联想工厂模式
仓储
领域模型中的对象自从被创建出来后不会一直留在内存中活动的,当它不活动时会被持久化到数据库中,只对聚合设计仓储
领域服务
模型关注个体行为,服务关注群体行为。操作是无状态的
领域模型和数据模型
| 区别点 | 领域模型 | 数据模型 |
|---|---|---|
| 表达形式 | 类图 | ER图 |
| 关注点 | 行为 | 数据 |
| entity定义 | 业务对象 | 表实体 |
转换关系:仓储层实现领域模型到数据模型的转换,也就是对象和表的转换。仓储接口层属于领域模型层,仓储实现层属于数据模型层
映射关系:领域模型:数据模型关系=N:1 一张表对应N个实体=1:N N个表对应1个聚合根=N:N。一模型修改N张表N个字段
怎么做领域驱动设计
领域统一语言
要求团队在进行所有的交流是都使用一致的语言,在代码中也是这样。一种基于模型的语言。因为模型是软件满足领域的共同点
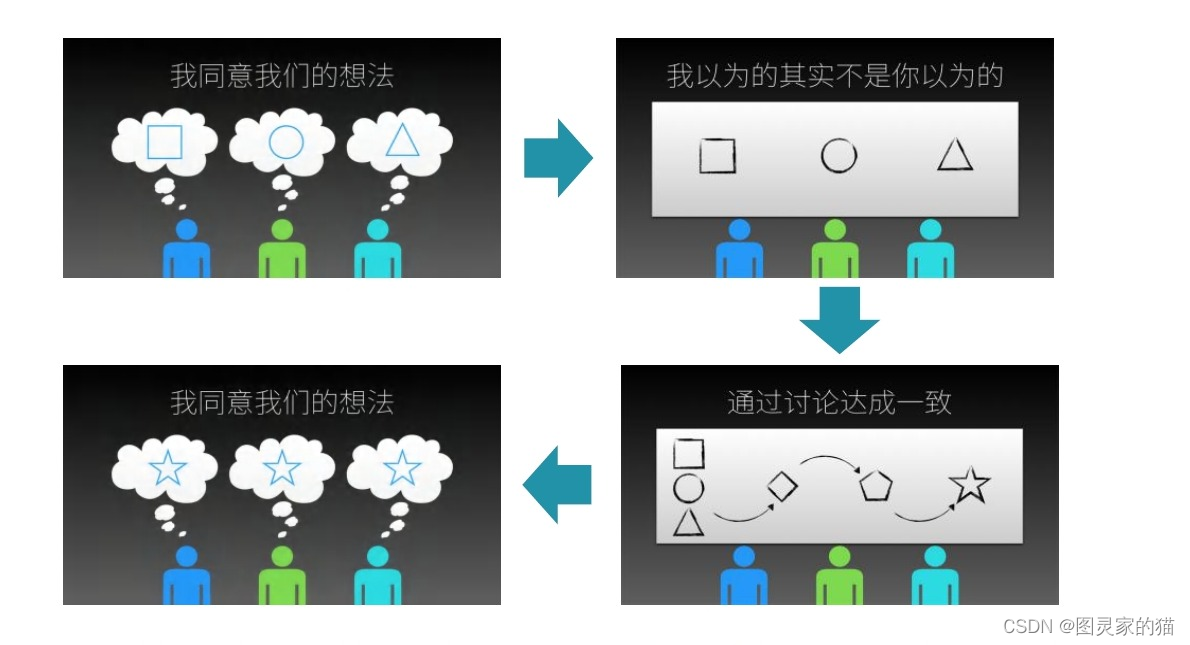
没有领域统一语言,就会存在上图中的问题。所以软件专家和领域专家通力合作开发出一个领域的模型。对于统一语言,建议每个项目都要有一份自己的核心领域词汇表。
建模方法论
-
事件风暴法:以领域事件为引线,向前或向后遍历模型
-
用例分析法:user stroy找名词和动词,梳理关系,绘制模型
-
四色原型分析法:蓝{description},绿{party,place,thing},黄{role},红{MI and MI detail}
模型演化
再稳固的模型,也不可能一成不变,毕竟现实世界一直在变,当现实世界变化到模型不能支撑时,要能马上修改模型才行
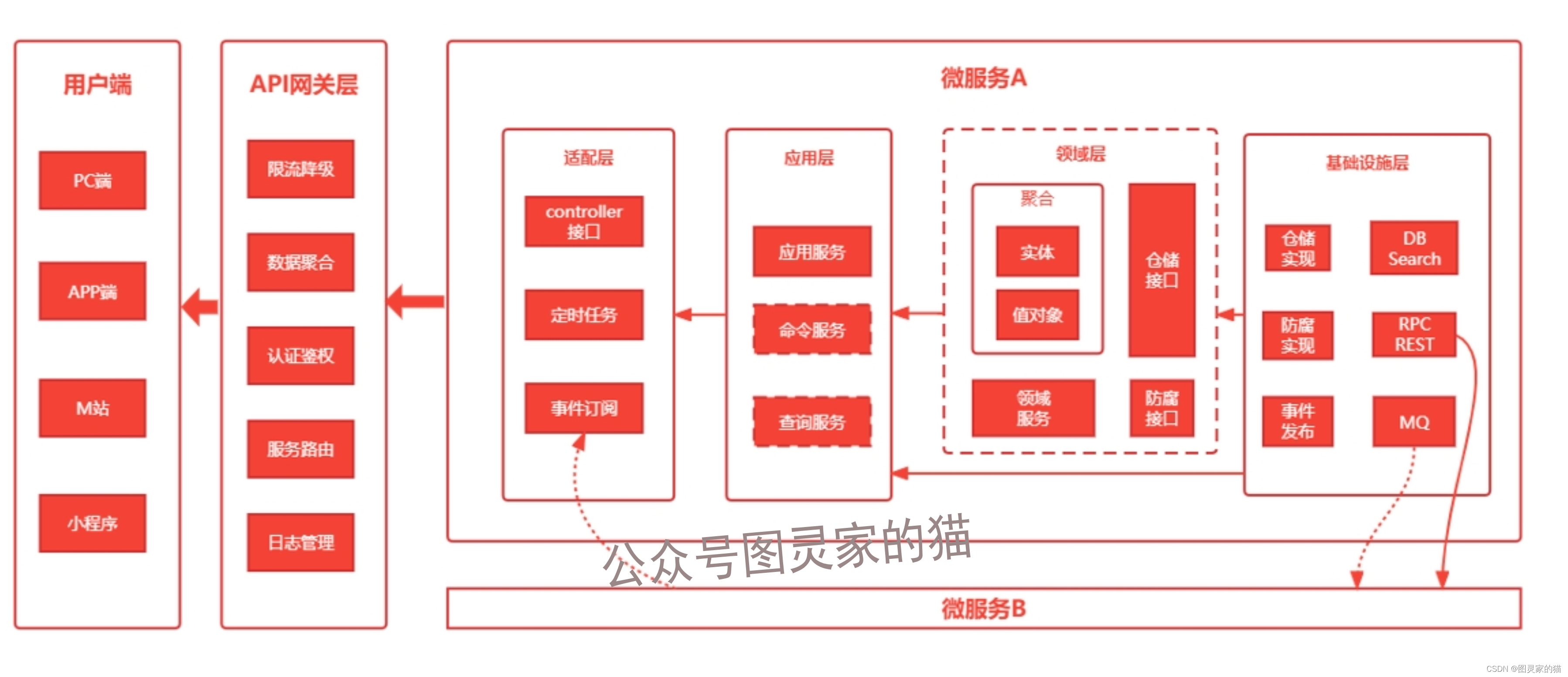
四层架构风格
下图为典型的四层架构,风格依据具体项目具体场景而定,切莫强行套用,可以灵活剪裁,也可以和其他架构风格组合使用(比如CQRS架构,本文不再做介绍,感兴趣者可自行网上搜索)
总结
软件开发的本质是在计算机的虚拟空间中,根据现实需求创造一个新世界,但大道无常,我们需要把握住核心的不变性,也是DDD的核心:领域模型
在ChatGPT爆火的今天,一个混迹江湖多年的研发人员,真正有优势的在于他在一个业务领域的多年沉淀,对业务领域有深刻的理解和认知。可以更好的把握领域模型在不断的需求变更中的演进,使得系统维持更强的活力,并因此体现自己真正的价值!

















 1564
1564

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









