




在微服务架构里,一个服务故障可能引发连锁反应,拖垮整个系统。为了避免 “服务雪崩”,限流、降级、熔断 成了必备的高可用策略。它们像三把防护伞,从流量控制、功能取舍、故障隔离三个维度,守护系统稳定。今天结合实际场景,聊聊这三板斧的逻辑和落地方法。
一、限流:控制流量,守住系统阈值
核心逻辑:限制单位时间内的请求量,避免流量洪峰压垮系统。就像景区限流,超过承载量就停止售票,保障游客体验。
(一)为什么需要限流?
看一个典型场景:
- 某电商大促,瞬间涌入 10 万并发请求,而系统最大只能承载 5 万 QPS(每秒请求数)。如果不限流,数据库、服务器会被打满,最终 服务雪崩(所有服务都无法响应)。
(二)常见限流算法
1. 计数器算法(简单粗暴)
逻辑:固定时间窗口内(如 1 分钟),统计请求数。超过阈值则拒绝新请求。
示例:
- 配置:1 分钟内最多 1 万请求。
- 实现(伪代码):
counter = 0
window_start = time.now()
def handle_request():
global counter, window_start
current_time = time.now()
# 时间窗口重置
if current_time - window_start > 60:
counter = 0
window_start = current_time
if counter < 10000:
counter += 1
return "处理请求"
else:
return "限流拒绝"
缺点:临界问题。比如第 59 秒发 1 万请求,第 61 秒又发 1 万请求,实际 2 秒内处理 2 万请求,超过阈值。
2. 令牌桶算法(平滑流量)
逻辑:系统以固定速率(如每秒 100 个)生成令牌,放入 “令牌桶”。请求必须拿到令牌才能处理,无令牌则限流。
优势:
- 允许突发流量(桶内有积累的令牌时,可瞬间处理);
- 平滑流量,避免计数器的临界问题。
示例(用 tokenbucket 库):
from tokenbucket import TokenBucket
# 每秒生成 100 个令牌,桶容量 1000
bucket = TokenBucket(rate=100, capacity=1000)
def handle_request():
if bucket.consume(1): # 尝试取 1 个令牌
return "处理请求"
else:
return "限流拒绝"
3. 漏桶算法(匀速处理)
逻辑:请求先进入 “漏桶”,漏桶以固定速率(如每秒 100 个)处理请求。桶满则新请求被拒绝。
对比令牌桶:
- 漏桶更严格,强制匀速处理,适合要求 “绝对均匀” 的场景(如数据库连接池);
- 令牌桶允许一定突发,更灵活。
(三)落地方式与工具
1. 代码级限流(侵入式)
在服务代码中集成限流逻辑(如用上述算法)。适合小型项目,但耦合性高。
2. 网关层限流(推荐)
用 API 网关(如 Nginx、Spring Cloud Gateway、Kong)统一限流。
示例(Nginx 配置):
# 限制每秒 100 个请求,突发 200 个
limit_req_zone $binary_remote_addr zone=mylimit:10m rate=100r/s;
server {
location /api {
limit_req zone=mylimit burst=200;
# 超过突发量则排队,再超过则拒绝
limit_req_status 429;
proxy_pass http://backend;
}
}
优势:非侵入式,统一管控所有入口流量。
(四)应用场景
- 秒杀 / 大促:限制瞬时流量,保障系统不被冲垮。
- 接口保护:防止恶意爬虫、高频调用拖垮 API。
- 资源瓶颈:如数据库连接池有限,通过限流控制并发查询数。
二、降级:牺牲非核心功能,保核心可用
核心逻辑:当系统压力过大或部分服务故障时,关闭非核心功能,释放资源保障核心业务。就像手机电量不足时,关闭后台应用,保电话、短信功能。
(一)为什么需要降级?
看场景:
- 电商系统大促,订单、支付是核心功能,但商品推荐、评价等非核心功能占用大量资源。此时降级非核心功能,保障核心流程。
(二)降级策略
1. 自动降级(基于监控指标)
通过监控系统的 CPU、内存、错误率、响应时间 等指标,自动触发降级。
示例:
- 配置:当某个服务的错误率 > 50%,自动降级该服务的非核心接口(如商品推荐接口)。
- 实现(Spring Cloud 示例):
// 配置降级规则
@SentinelResource(value = "productRecommend",
fallback = "fallbackRecommend")
public List<Product> getRecommendProducts() {
// 正常调用推荐服务
return recommendService.getProducts();
}
// 降级后的 fallback 方法
public List<Product> fallbackRecommend() {
// 返回默认推荐(如热门商品),或空
return Arrays.asList(hotProduct1, hotProduct2);
}
2. 手动降级(应急响应)
在系统故障时,人工触发降级(如运维在 dashboard 点击按钮)。
场景:
- 数据库故障时,手动关闭所有非核心查询接口,只保留订单写入功能。
(三)降级颗粒度
- 服务级:关闭整个服务(如关闭推荐服务,返回默认数据)。
- 接口级:只关闭某个接口(如商品评价接口,返回 “当前繁忙,稍后重试”)。
- 功能级:关闭复杂功能(如关闭商品详情页的 3D 预览,返回静态图片)。
(四)应用场景
- 资源紧张:大促、故障时,释放资源保核心。
- 依赖故障:当依赖的第三方服务(如支付网关)故障,降级为备用方案(如线下支付记录)。
- 用户体验权衡:牺牲非核心功能,保障核心流程的流畅性。
三、熔断:故障快速隔离,防止雪崩
核心逻辑:当某个服务持续故障(如超时、错误率高),暂时切断调用,快速返回默认结果,避免故障扩散。就像电路短路时,保险丝熔断,保护其他电器。
(一)为什么需要熔断?
看场景:
- 订单服务依赖库存服务。库存服务因数据库慢查询响应超时,导致订单服务的线程池被占满,最终整个订单系统无法响应。此时熔断库存服务,订单服务可快速返回 “库存查询中,请稍后重试”,避免雪崩。
(二)熔断状态机(以 Sentinel 为例)
熔断通常有三个状态:
1. 关闭(Closed)
- 正常状态,允许调用目标服务。
- 持续统计调用的错误率、超时率。
2. 打开(Open)
- 当错误率超过阈值(如 50%),进入打开状态。
- 所有调用直接返回默认结果(不执行真实调用)。
3. 半打开(Half - Open)
- 打开状态持续一段时间(如 5 秒)后,进入半打开状态。
- 允许少量请求调用目标服务,验证是否恢复。
- 若请求成功,关闭熔断;若失败,重新打开。
(三)实现示例(Sentinel 熔断)
// 配置熔断规则:错误率 > 50%,熔断 10 秒
@SentinelResource(value = "stockService",
fallback = "fallbackStock",
circuitBreaker = @CircuitBreaker(
errorRatio = 0.5,
minRequestAmount = 100,
sleepWindow = 10))
public Stock checkStock(Product product) {
return stockService.getStock(product);
}
// 熔断后的 fallback 方法
public Stock fallbackStock(Product product, Throwable ex) {
// 返回默认库存(或空),快速失败
return new Stock(0, "熔断中");
}
(四)熔断 vs 降级
| 对比项 | 熔断 | 降级 |
|---|---|---|
| 触发条件 | 依赖服务持续故障(超时、错误) | 系统资源紧张、高负载 |
| 目标 | 隔离故障,防止雪崩 | 牺牲非核心,保核心 |
| 动作 | 切断调用,快速返回 | 关闭功能,返回降级结果 |
| 典型工具 | Sentinel、Hystrix | Sentinel、Spring Cloud |
(五)应用场景
- 服务依赖故障:如依赖的库存、支付服务故障,熔断后快速返回,避免拖垮调用方。
- 资源过载保护:当线程池、连接池耗尽时,熔断非关键调用。
四、限流 + 降级 + 熔断:协同作战
(一)三者关系
- 限流:控制入口流量,防止洪峰。
- 降级:压力下牺牲非核心,保核心。
- 熔断:故障时隔离问题服务,快速失败。
三者协同,形成完整的高可用防护体系:
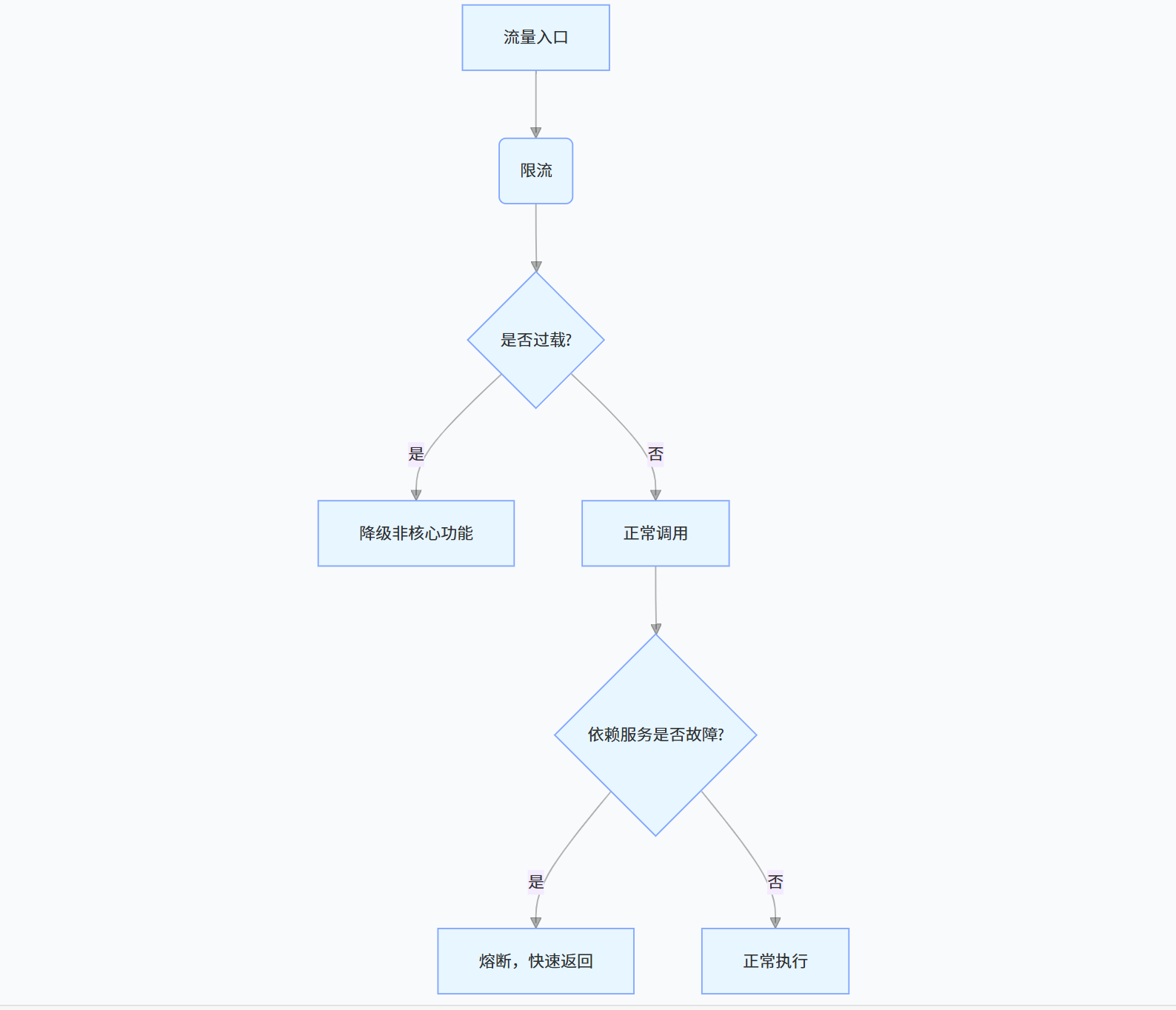
(二)实践案例:电商大促防护
在电商大促中,三者的协同流程:
- 限流:通过网关限制每秒 10 万请求,超过则拒绝。
- 降级:当系统 CPU > 80%,自动降级商品推荐、评价等非核心接口。
- 熔断:若库存服务响应超时(错误率 > 60%),熔断库存查询,订单服务返回 “库存查询中”,避免雪崩。
五、总结:高可用三板斧的价值
- 限流:守护系统 “入口”,防止流量洪峰压垮资源。
- 降级:权衡 “功能取舍”,保障核心业务的连续性。
- 熔断:隔离 “故障传播”,快速失败避免雪崩。
三者并非孤立,而是协同工作,构建微服务的高可用防护网。在实际项目中,结合 Sentinel、Hystrix、Spring Cloud 等工具,可快速落地这些策略,让系统在高负载、故障下仍能稳定运行。
(拓展思考:如何通过监控系统联动三板斧?比如限流触发后,自动调整降级策略;熔断后,通知运维自动扩容。这需要更深入的体系化建设~)

















 1609
1609

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









