




核心工作:提出使用时域音频分离网络,即编码器-解码器框架直接在时域对信号建模,并在非负编码器输出上执行声源分离。
STFT缺点:
1. 提出傅里叶分解并不一定是最优的语音分离信号变换
2. STFT将信号转换为复数域,但不能很好的处理相位谱
3. 频谱有效分率需要高频率高分辨率,否则会产生时延
TasNet:
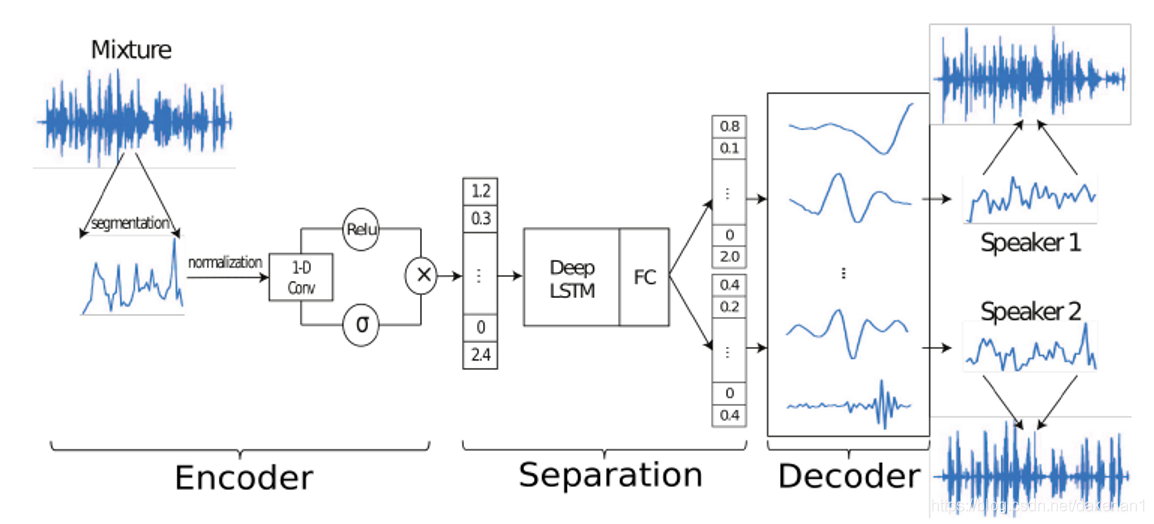
1. N个非负加权基础信号表示混合语音波形;
2. 基础信号的权重来自于编码器输出,基础信号即解码器的滤波器;
3. 估计权重(非负)可以表示为每个声源对混合权重贡献的掩模,类似于STFT中的T-F掩模
4. 解码器学习后重建声源波形
实验结论:
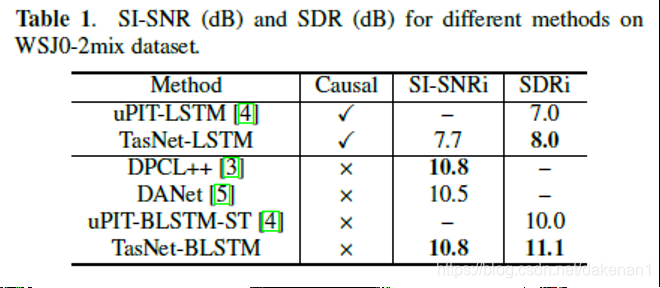
1. 与单向LSTM构成因果系统,优于使用T-F的系统;与BLSTM构成非因果系统,同样效果更好;
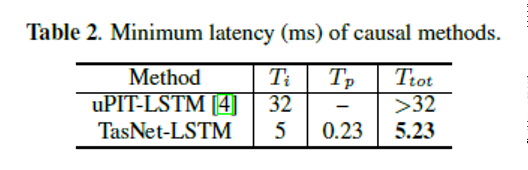
2. 我们系统中每个段的平均处理速度小于 0.23 ms,导致系统总延迟为 5.23 ms。 相比之下,基于 STFT 的系统至少需要 32 毫秒的时间间隔才能启动处理,此外还需要处理时间STFT、分离和反向STFT的计算;
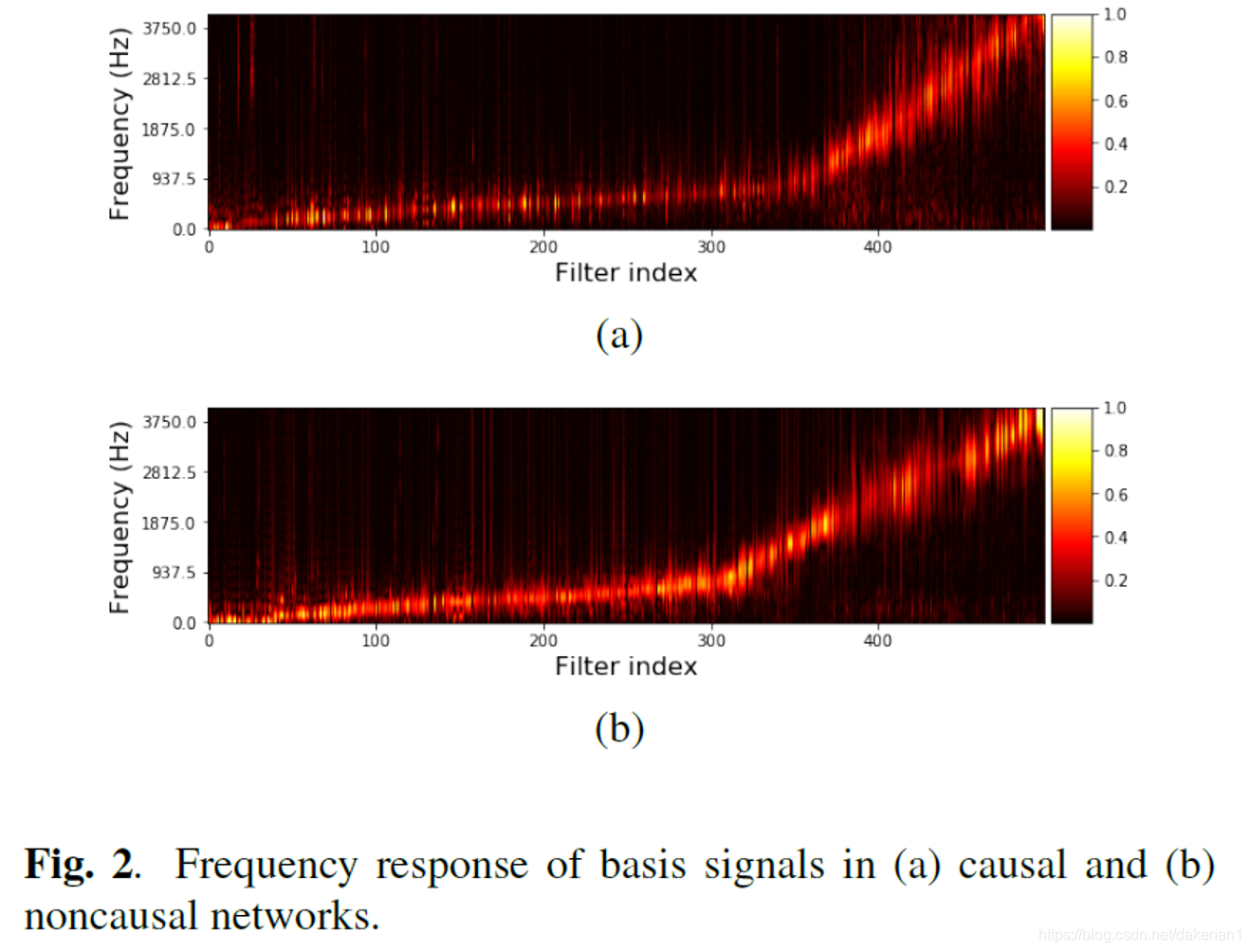
4. 观察到从低频率到高频的连续转换,表明系统已经学会对波形进行光谱分解;相比之下,与梅尔倒谱、STFT相比,TasNet 中的基础信号在较
单通道实时语音分离的TasNet结构总结
最新推荐文章于 2025-10-14 09:55:26 发布
 本文总结了TasNet在语音分离中的应用,它采用时域音频分离网络,通过非负编码器输出执行声源分离。与STFT相比,TasNet解决了相位处理问题,并能在低延迟下实现高效分离。实验表明,TasNet在因果和非因果系统中均优于基于T-F的系统,并具有更好的频率分辨率。
本文总结了TasNet在语音分离中的应用,它采用时域音频分离网络,通过非负编码器输出执行声源分离。与STFT相比,TasNet解决了相位处理问题,并能在低延迟下实现高效分离。实验表明,TasNet在因果和非因果系统中均优于基于T-F的系统,并具有更好的频率分辨率。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1197
1197

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









