 RAG Foundry框架论文复现笔记
RAG Foundry框架论文复现笔记





一、论文简介
这篇论文介绍了一个名为RAG Foundry的开源框架,旨在增强大语言模型(LLMs)在检索增强生成(RAG)场景中的性能。以下是论文的核心内容梳理:
1. 研究背景与动机
LLM 的局限性:尽管大语言模型(如 Llama、Phi 系列)能力强大,但存在幻觉(生成错误信息)、事实准确性不足、无法获取训练 cutoff 后的新信息、难以处理长上下文等问题。
RAG 的优势:检索增强生成(RAG)通过整合外部知识检索机制,能缓解上述问题,提升生成内容的相关性、可解释性,并降低成本。
现有工具的不足:现有 RAG 工具(如 LlamaIndex、LangChain)侧重推理流程搭建,但在训练和评估功能上不完善;其他框架要么缺乏训练模块,要么灵活性不足。
2. RAG Foundry 框架核心设计
框架整合了数据创建、训练、推理和评估四个核心模块,形成端到端的 RAG 工作流,支持快速原型设计和多配置实验。
数据创建与处理:
支持从 Hugging Face 或本地加载数据,结合检索工具(如 Haystack)获取外部上下文,生成带检索信息的增强数据集。
包含数据清洗、采样、提示构建(Prompt 设计)等步骤,支持多数据集联动和步骤缓存,提升效率。
训练模块:
基于 TRL 库实现,支持 LoRA(低秩适应)等高效微调方法,可针对 RAG 场景优化模型(如 Llama-3、Phi-3)。
配置文件可指定模型参数、学习率、训练轮次等。
推理模块:
基于处理后的数据集生成预测结果,支持自定义生成参数(如最大新 token 数、采样策略)。
与评估模块分离,便于对同一推理结果进行多维度评估。
评估模块:
支持多种指标,包括精确匹配(EM)、F1、ROUGE、BERTScore,以及 RAG 特有的 Faithfulness(生成内容与上下文的一致性)和 Relevancy(生成内容与查询的相关性)。
可评估检索、排序、推理等多个环节的性能。
3. 实验与结果
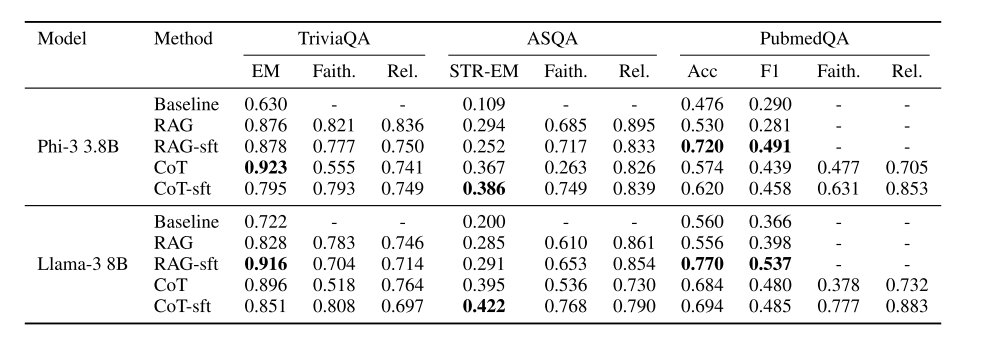
实验设置:
模型:Llama-3(8B)和 Phi-3(3.8B)。
数据集:TriviaQA、ASQA、PubmedQA(均为知识密集型问答任务)。
方法:对比基线模型(无检索)、RAG(仅检索增强)、RAG-sft(RAG 微调)、CoT-sft(结合思维链微调)等。
关键发现:
RAG 增强显著提升模型性能,尤其在事实准确性上。
微调(如 RAG-sft、CoT-sft)进一步优化结果,其中 CoT-sft 在 ASQA 等数据集上表现最佳。
Faithfulness 和 Relevancy 等指标与主任务指标(如 EM)不完全相关,说明需多维度评估 RAG 系统。
4. 贡献与意义
提供开源、模块化的端到端 RAG 框架,简化 RAG 系统的设计、训练和评估流程。
支持灵活配置和自定义组件,便于研究者快速实验不同 RAG 技术(如检索算法、提示策略)。
实验验证了框架的有效性,为 RAG 在知识密集型任务中的应用提供参考。
原文链接:https://arxiv.org/pdf/2408.02545
论文代码开源于:https://github.com/IntelLabs/RAGFoundry
二、环境搭建 (windows11)
1. 创建并激活虚拟环境
# 创建名为 ragfit 的环境,指定 Python 3.10
conda create -n ragfit python=3.10 -y
# 激活环境
conda activate ragfit
激活后命令行前缀会显示 (ragfit),表示当前处于该环境中。
2.克隆代码
git clone https://github.com/IntelLabs/RAG-FiT.git
cd RAG-FiT
或者直接从github链接下载压缩包后解压。
3.安装依赖包
1. 基本依赖安装
使用 pip 安装项目核心依赖:
pip install -e .
2. 可选依赖安装
若需要使用 haystack 相关功能:
pip install -e .[haystack]
若需要使用 deepeval 评估工具:
pip install -e .[deepeval]
三、基线模型复现
基线实验目标:使用 Phi-3-mini-128k-instruct 模型,在 ASQA 数据集上复现「零样本无检索增强」的短答案评估结果(STR-EM 指标)。
因为基线模型无检索增强,所以复现步骤仅包含:数据处理->推理->评估
1、数据处理:生成基线数据集
1.1 核心逻辑
通过processing.py调用configs/paper/processing-asqa-baseline.yaml,生成仅包含问题和短答案的基线数据(无检索上下文)。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 213
213

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









