






Kafka的Consumer相关知识回顾总结
1.消费者组流程(超级详细)
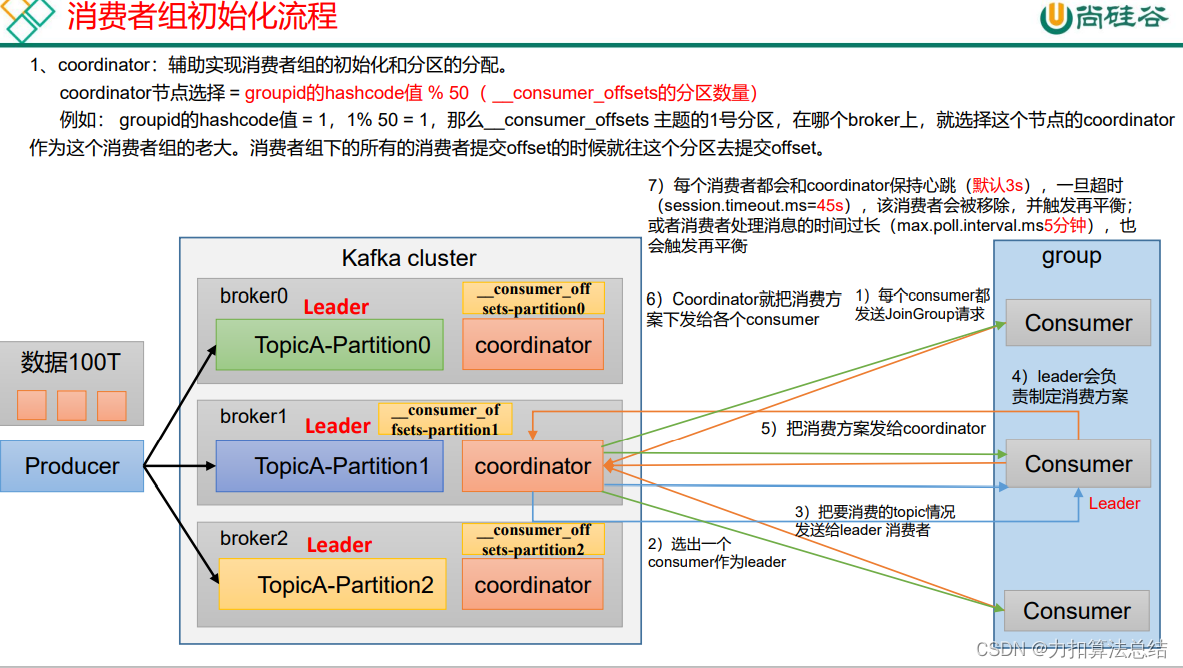
这里注意一下coordinator(节点的选择 gropuid%50):辅助实现消费者组的初始化和分区的分配。第一步是poll操作,第四步有range,roundrobin,粘性常用的三个,第7步有两个再平衡(1.消费者与coordinator通讯>45s 。消费者与分区处理消息>5分钟)
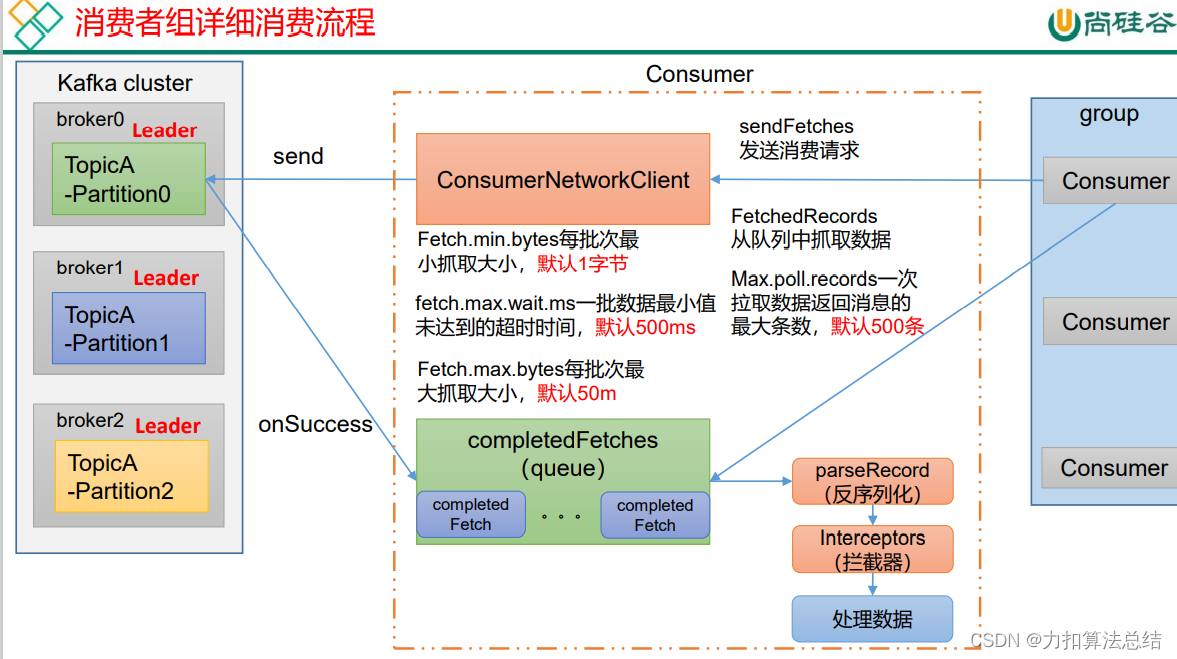
这里注意一下消费者拉取数据的1.最小批次1字节,最大50m。2.一批数据超时时间500ms。3.拉取数据的最大500条数。通过send拉取之后,通过onSuccess返回到消息队列,经过反序列化->拦截器->处理数据到达消费者。
2.按照主题消费
0)配置信息
1.连接
2.反序列化
3.组id
1)创建消费者
2)订阅Topic
3)发送数据
3.按照分区消费
4.消费组案例
5.分区分配策略(再平衡)
例如:7个分区,3个消费者
1.range
分区数%消费者=2…1
每个消费者依次处理两个分区,剩下的一个交给第一个消费者。每次都交给第一个消费者,如果topic多的话,容易产生数据倾斜
0 1 2
3 4
5 6
再平衡:(45s内)如果第一个消费者挂了,则把0 1 2 都给第二个消费者(45s后重启,剩下两个消费者,重新按照range分配)
2.roundrobin(轮询,分配的均匀)
0 3 6
1 4
2 5
再平衡:(45s内)如果第一个消费者挂了,则把0 3 6轮询给第二第三个消费者(45s后重启,剩下两个消费者,重新按照roundrobin分配)
3.粘性(类似于range,但是这个分区是随机的)
再平衡:(45s内)如果第一个消费者挂了,则把0 3 6尽量均匀的分给第二第三个消费者(45s后重启,剩下两个消费者,重新按照粘性分配)
6.offset
1.默认存储在系统主题(_consumer_offsets)
2.默认自动提交 5s
3.手动提交(1.同步。2.异步)
4.指定offset消费 seek()
5.按照时间消费 (时间转化为offset)
6.漏消费 重复消费
7.事务(数据一致,没有数据重复,没有漏掉数据)
生产者->集群->消费者->事务框架
8.数据积压(消费者如何提高吞吐量?)
1.增加topic的分区数,同时提升消费者的个数
2.提高每批次拉取的数量(默认500条),提高抓取大小(默认50m)
尚硅谷讲的真的很棒,相关资料资源链接
链接:https://pan.baidu.com/s/15nsdIwLJ3vd_h9VAug3kbQ
提取码:wcdx

















 1177
1177

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









