







 本文介绍了一种从加州交通数据开放平台爬取数据的方法。通过分析网页加载过程,使用Python模拟登录并请求特定格式的数据,成功获取到了所需的交通数据。
本文介绍了一种从加州交通数据开放平台爬取数据的方法。通过分析网页加载过程,使用Python模拟登录并请求特定格式的数据,成功获取到了所需的交通数据。
这几天开始写毕业设计,打算做一个交通大数据处理方面的系统。因此选取了一个国外的交通数据开放网站(国内不开放?):
http://pems.dot.ca.gov (佩服这个加州的数据平台,做的太棒棒了(๑•̀ㅂ•́)و✧!!!)
在里面找到Data Clearinghouse 点击进入如下页面
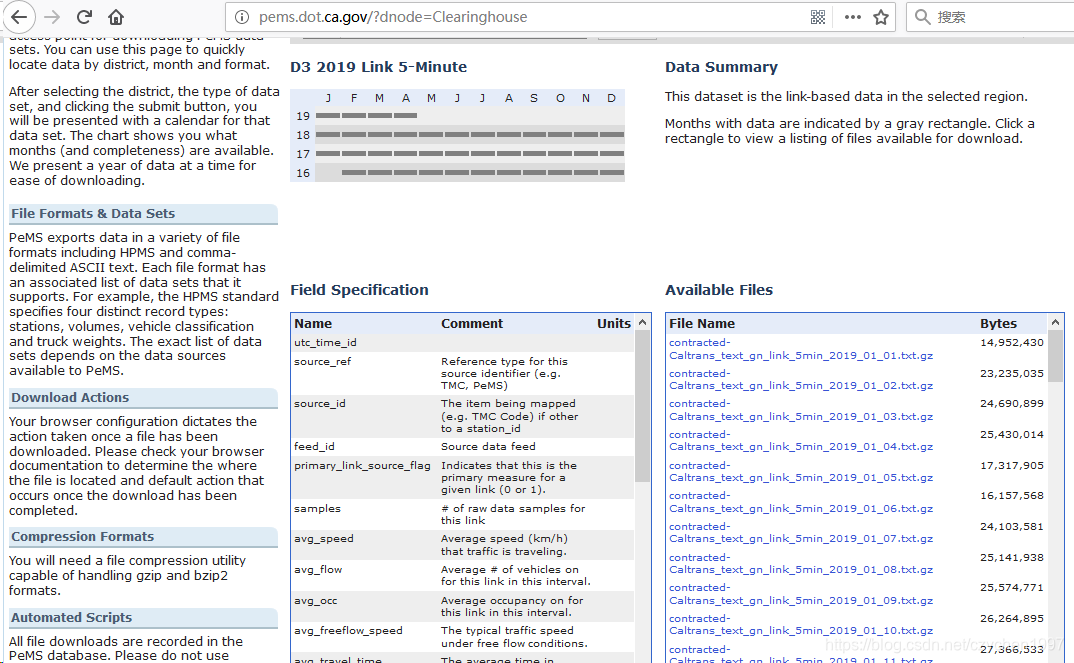
目标数据就在右下角,本来写了一个脚本去爬取文件下载地址的url。结果不管怎么样都是空的???(这里要翻墙+模拟登陆否则爬虫访问不到该页面, 账号自己申请行了)
用开发者工具看网页代码,table里面有文件下载地址的url。但是用页面源代码看却没有。通过网上搜索一番,有目前两种可能:ajax异步加载以及动态js加载。之后我用开发者工具看了页面的加载过程,找到了如下内容(以火狐为例)
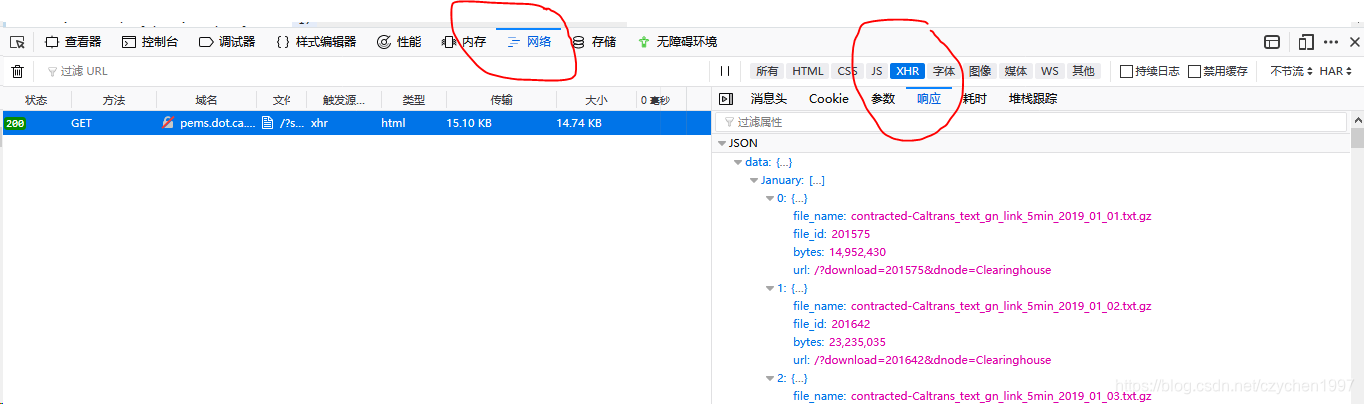
这下这个问题就基本解决啦 o(* ̄▽ ̄*)ブ!
但是要注意链接上要这样请求:http://pems.dot.ca.gov/?srq=clearinghouse&district_id=3&geotag=null&yy=2019&type=gn_link_5min&returnformat=text
注意要加上 returnformat=text 然后用python中的json模块loads一下就拿到格式化的内容啦。
附上我丑陋的代码 ≧ ﹏ ≦
import requests
import json
session = requests.session()
proxies = {
'http': '127.0.0.1:1080',
'https': '127.0.0.1:1080'
}
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
data = {"redirect":"", "username":"账号",
"password":"密码","login":"Login"}
html = session.post("http://pems.dot.ca.gov/?dnode=Clearinghouse", proxies = proxies, data = data)
#print(session.cookies)
html = session.get("http://pems.dot.ca.gov/?srq=clearinghouse&district_id=3&geotag=null&yy=2019&type=gn_link_5min&returnformat=text",proxies = proxies,headers = headers )
data = json.loads(html.text)
urls = data['data']['January']
for u in urls:
print('http://pems.dot.ca.gov' + u['url'])
注意该网站上说了这个:All file downloads are recorded in the PeMS database. Please do not use automated scripts to retrieve data through this service. If using a batch downloading tool, please configure it to visit links serially. PeMS will block concurrent download requests.

















 1624
1624

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









