




转载自:https://www.cnblogs.com/shine-lee/p/12293097.html
ndarray的设计哲学
在于数据存储与其解释方式的分离,或者说copy和view的分离,让尽可能多的操作发生在解释方式上(view上),而尽量少地操作实际存储数据的内存区域。
如下所示,像reshape操作返回的新对象b,a和b的shape不同,但是两者共享同一个数据block,c=b.T,c是b的转置,但两者仍共享同一个数据block,数据并没有发生变化,发生变化的只是数据的解释方式。
副本是一个数据的完整的拷贝,如果我们对副本进行修改,它不会影响到原始数据,物理内存不在同一位置。副本一般发生在:
Python 序列的切片操作,调用deepCopy()函数。
调用 ndarray 的 copy() 函数产生一个副本。
视图是数据的一个别称或引用,通过该别称或引用亦便可访问、操作原有数据,但原有数据不会产生拷贝。如果我们对视图进行修改,它会影响到原始数据,物理内存在同一位置。
视图一般发生在:
1、numpy 的切片操作返回原数据的视图。
2、调用 ndarray 的 view() 函数产生一个视图。
ndarray内存布局
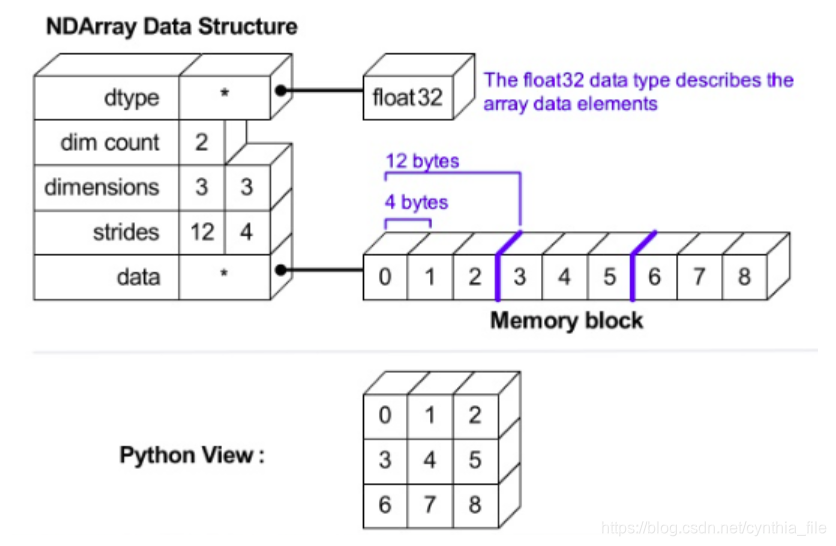
可大致划分成2部分——对应设计哲学中的数据部分和解释方式:
raw array data:为一个连续的memory block,存储着原始数据,类似C或Fortran中的数组,连续存储
metadata:是对上面内存块的解释方式
metadata都包含哪些信息呢?
dtype:数据类型,指示了每个数据占用多少个字节,这几个字节怎么解释,比如int32、float32等;
ndim:有多少维;
shape:每维上的数量;
strides:维间距,即到达当前维下一个相邻数据需要前进的字节数,因考虑内存对齐,不一定为每个数据占用字节数的整数倍;
上面4个信息构成了ndarray的indexing schema,即如何索引到指定位置的数据,以及这个数据该怎么解释。
除此之外的信息还有:字节序(大端小端)、读写权限、C-order(行优先存储) or Fortran-order(列优先存储)等,如下所示,
>>> a.flags
C_CONTIGUOUS : True
F_CONTIGUOUS : False
OWNDATA : True
WRITEABLE : True
ALIGNED : True
WRITEBACKIFCOPY : False
UPDATEIFCOPY : False
ndarray的底层是C和Fortran实现,上面的属性可以在其源码中找到对应,具体可见PyArrayObject和PyArray_Descr等结构体。
为什么ndarray可以这样设计?
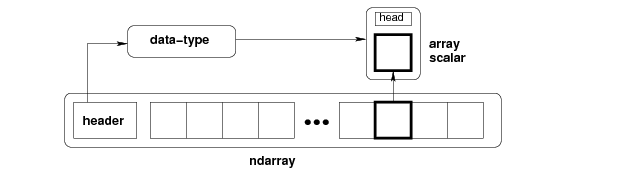
因为ndarray是为矩阵运算服务的,ndarray中的所有数据都是同一种类型,比如int32、float64等,每个数据占用的字节数相同、解释方式也相同,所以可以稠密地排列在一起,在取出时根据dtype现copy一份数据组装成scalar对象输出。这样极大地节省了空间,scalar对象中除了数据之外的域没必要重复存储,同时因为连续内存的原因,可以按秩访问,速度也要快得多。

















 1154
1154

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









