









HDFS频繁报如下错误:
2022-02-28 00:15:39,115 WARN datanode.DataNode (DataXceiverServer.java:run(168)) - hadoop-04:50010:DataXceiverServer:
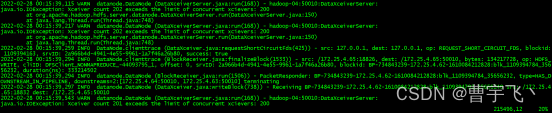
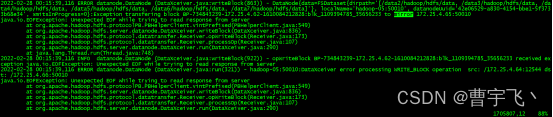
java.io.IOException: Xceiver count 202 exceeds the limit of concurrent xcievers: 200
at org.apache.hadoop.hdfs.server.datanode.DataXceiverServer.run(DataXceiverServer.java:150)
at java.lang.Thread.run(Thread.java:748)
2022-02-28 00:15:39,217 WARN datanode.DataNode (DataXceiverServer.java:run(168)) - hadoop-04:50010:DataXceiverServer:
java.io.IOException: Xceiver count 202 exceeds the limit of concurrent xcievers: 200
at org.apache.hadoop.hdfs.server.datanode.DataXceiverServer.run(DataXceiverServer.java:150)
at java.lang.Thread.run(Thread.java:748)
2022-02-28 00:15:39,259 INFO DataNode.clienttrace (DataXceiver.java:requestShortCircuitFds(425)) - src: 127.0.0.1, dest: 127.0.0.1, op: REQUEST_SHORT_CIRCUIT_FDS, blockid: 1109394163, srvID: 2a966b4d-4941-4e55-9961-1a7f46a26b80, success: true
2022-02-28 00:15:39,294 INFO DataNode.clienttrace (BlockReceiver.java:finalizeBlock(1533)) - src: /172.25.4.65:18826, dest: /172.25.4.65:50010, bytes: 134217728, op: HDFS_WRITE, cliID: DFSClient_NONMAPREDUCE_-44093795_1, offset: 0, srvID: 2a966b4d-4941-4e55-9961-1a7f46a26b80, blockid: BP-734843239-172.25.4.62-1610084212828:blk_1109394784_35656232, duration(ns): 333214502
2022-02-28 00:15:39,294 INFO datanode.DataNode (BlockReceiver.java:run(1506)) - PacketResponder: BP-734843239-172.25.4.62-1610084212828:blk_1109394784_35656232, type=HAS_DOWNSTREAM_IN_PIPELINE, downstreams=2:[172.25.4.64:50010, 172.25.4.63:50010] terminating
2022-02-28 00:15:39,297 INFO datanode.DataNode (DataXceiver.java:writeBlock(738)) - Receiving BP-734843239-172.25.4.62-1610084212828:blk_1109394792_35656240 src: /172.25.4.65:18832 dest: /172.25.4.65:50010

解决方法:
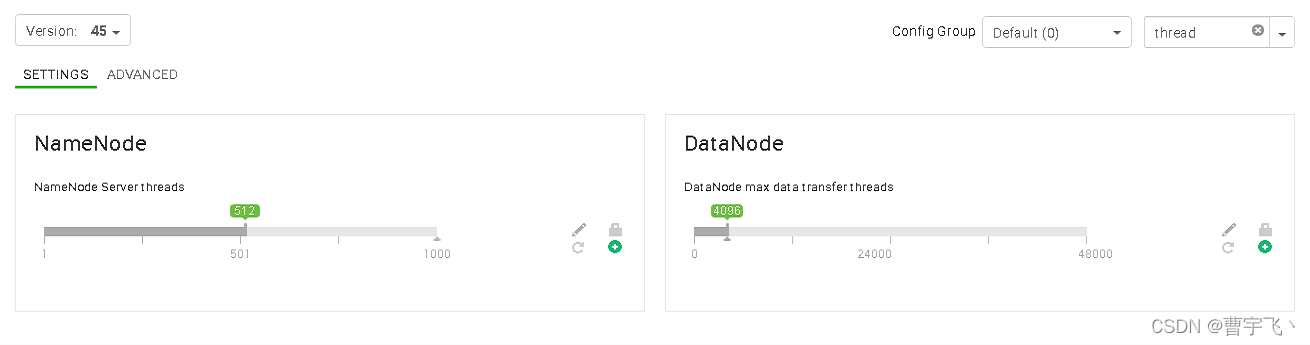
Hadoop HDFS DataNode 在任何时候都可以提供文件数量的上限。上限由 dfs.datanode.max.transfer.threads属性控制。修改hdfs-site.xml配置为至少4096(HDP集群默认200)。


















 1002
1002

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











