








异常说明

客户系统更新版本需要增加字段,客户执行ALTER TABLE SQL后,字段加入到了对应的表中,但发现系统使用异常。
问题定位并解决
问题定位
接收到客户反馈后,首先查看Keepalived的服务状态以及配置,确定Keepalived服务正常,随后查看MySQL集群状态。
查看MySQL节点日志,有输出:
Lock wait timeout exceeded; try restarting transaction
登陆MySQL终端执行MySQL命令“show status like 'wsrep%';”查看节点状态:
A节点和C节点状态正常:

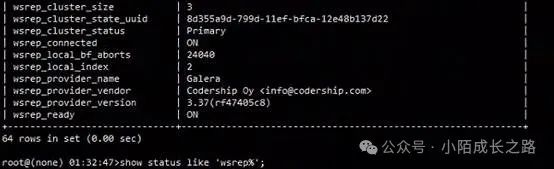
B节点执行MySQL相关命令无响应:
![]()
B节点执行命令,MySQL处于运行状态:
systemctl status mysqld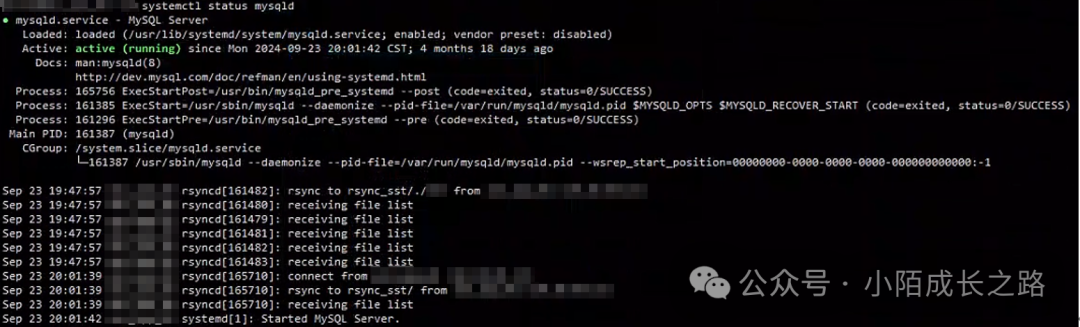
由于B节点的MySQL节点MySQL命令响应超时,故检查系统资源情况:
执行命令查看系统负载正常:
w
执行命令查看内存可用正常:
free -h
执行命令查看磁盘IO情况未见异常:
iostat -x -k 3 50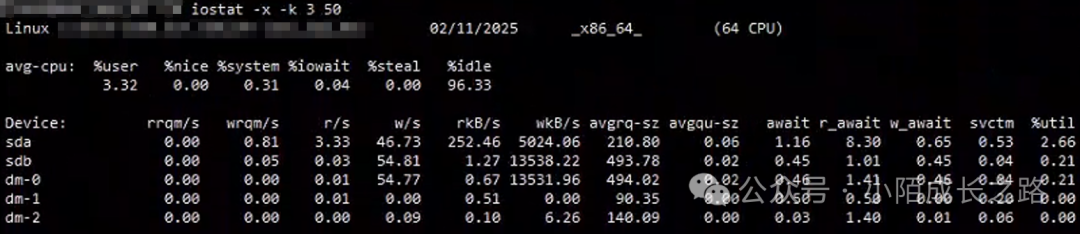
以上可以判定操作系统无异常。
MySQL Galera Cluster 默认使用Total Ordered Isolation (TOI)模式执行DDL(如ALTER TABLE),该模式会在所有节点同步执行DDL时锁定集群,此时插入操作阻塞直至DDL完成)据此初步判定MySQL集群异常是由B节点卡住导致DDL操作未完成,阻塞整个MySQL集群插入数据。
继续排查,查看正常MySQL节点A和B:
执行MySQL命令查看集群更新DDL方法;
show VARIABLES like '%method%';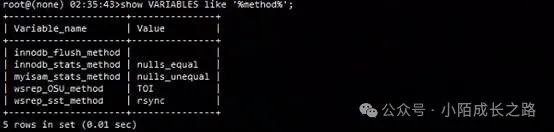
执行MySQL命令查看事务状态:
select trx_id,trx_state,trx_mysql_thread_id from INNODB_TRX where trx_state="LOCK WAIT";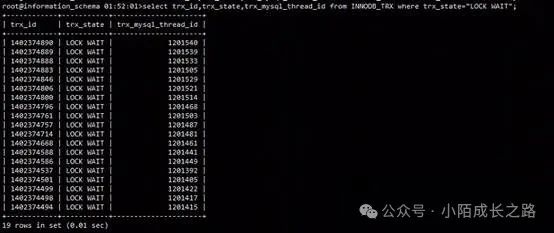
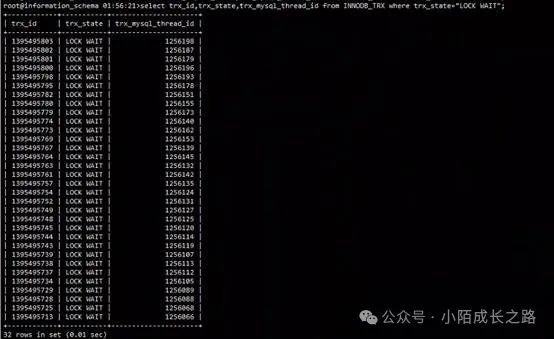
由此判断MySQL集群确实处于阻塞状态。
问题解决
由于B节点DDL长时间卡住导致集群阻塞,影响业务,且无法通过MySQL命令进行事务操作,为恢复集群可用,需要将B节点暂时踢出集群,遂将MySQL进程kill,此时集群恢复可用。
B节点MySQL被kill后集群阻塞状态消失,MySQL服务由另外两个正常节点提供。B节点MySQL进程由高可用机制自动拉起,进行数据同步,大约30分钟后B节点MySQL恢复正常(集群数据量500G),此时集群整体恢复正常:
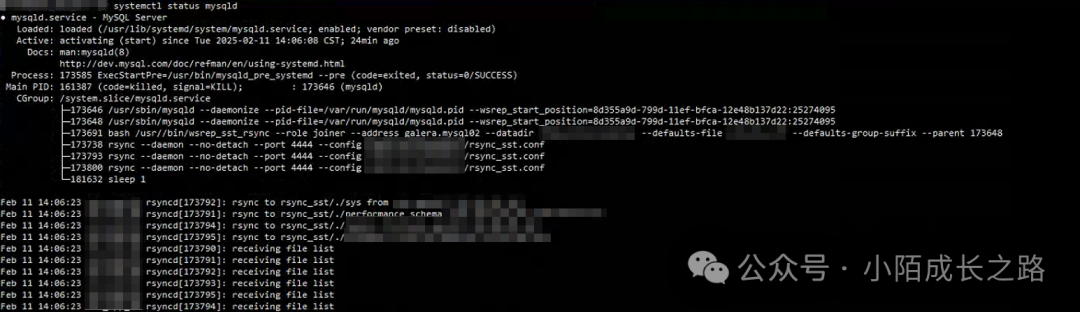
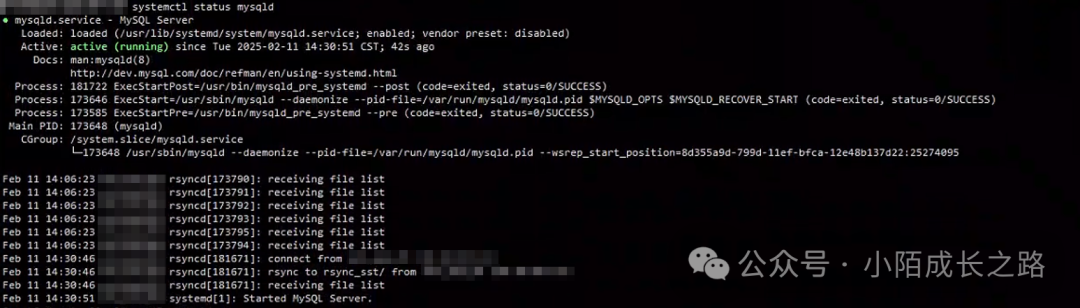
异常整改措施以及预防优化建议
整改措施
标准化DDL操作流程
执行DDL前,通过验证所有节点的wsrep_ready为ON、wsrep_cluster_size与节点数量一致。
SHOW STATUS LIKE 'wsrep%' 使用以下命令检查是否存在未提交事务或长事务:
SELECT * FROM information_schema.innodb_trx执行模式切换
SET wsrep_OSU_method='RSU'; --切换为滚动升级模式ALTER TABLE <表名> ...; --执行DDL操作SET wsrep_OSU_method='TOI'; --恢复默认模式
事后验证
检查DDL执行后集群同步状态(wsrep_local_state_comment应为Synced)。
验证业务功能是否正常,并通过测试确认写入无异常。
异常节点快速处理机制
若某节点因DDL卡死导致集群阻塞,立即通过KILL <thread_id>终止相关线程,如果MySQL终端已无法响应,重启该节点MySQL服务。
待节点恢复后,检查wsrep_sst_method配置,确保数据同步(SST/IST)正常完成。
操作日志与回滚预案
记录所有DDL操作的执行时间、节点状态及操作人员,留存操作日志。
为高风险DDL操作设计回滚脚本(如备份原表结构、快速重建表)。
预防优化方案
MySQL集群监控与告警增强
增加监控项
实时监控wsrep_flow_control_paused(流控制暂停比例)配置告警阈值,监控节点状态(wsrep_cluster_status)、同步延迟(wsrep_local_recv_queue_avg)。
MySQL配置优化
调整锁超时时间
优化线程池
优化innodb缓冲池


















 63
63

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











