



1. 年龄分箱(每10岁一组)
df[‘年龄分组’] = pd.cut(df[‘年龄’], bins=[0, 20, 30, 40, 50, 100],
labels=[‘0-20岁’, ‘21-30岁’, ‘31-40岁’, ‘41-50岁’, ‘50岁以上’])
2. 多因素分组统计(示例:医疗诊断和营养缺乏的关系)
med_nutrition = df.groupby(‘医疗状况’)[‘营养缺乏’].value_counts().unstack(fill_value=0)
print(“医疗状况与营养缺乏交叉表:”)
print(med_nutrition.head())
3. 遗传因素导致脱发的营养缺乏特征
genetic_hair_loss = df[(df[‘遗传因素’] == 1) & (df[‘脱发标记’] == 1)]
genetic_nutrition = genetic_hair_loss[‘营养缺乏’].value_counts(normalize=True) * 100
print(“\n遗传因素导致脱发的营养缺乏分布(百分比):”)
print(genetic_nutrition.head())
1. 按压力水平分组分析脱发特征
stress_groups = df.groupby(‘压力水平’)
计算各组脱发比例
hair_loss_ratio = stress_groups[‘脱发标记’].mean() * 100
print(“\n不同压力水平下的脱发比例:”)
print(hair_loss_ratio)
2. 高压力组与低压力组的特征差异
high_stress = df[df[‘高压力’] == 1]
low_stress = df[df[‘高压力’] == 0]
对比两组的遗传因素、吸烟习惯等
stress_comparison = pd.DataFrame({
‘高压力组遗传比例’: [high_stress[‘遗传因素’].mean()],
‘低压力组遗传比例’: [low_stress[‘遗传因素’].mean()],
‘高压力组吸烟比例’: [high_stress[‘吸烟习惯’].mean()],
‘低压力组吸烟比例’: [low_stress[‘吸烟习惯’].mean()]
})
print(“\n高压力组与低压力组关键特征对比:”)
print(stress_comparison)
### 脱发因素分析及预测技术文章大纲
#### 引言
- 脱发现象的普遍性及影响
- 技术手段在脱发研究和预测中的应用价值
- 文章结构概述
#### 脱发的主要影响因素分析
- **遗传因素**
- 家族性脱发(雄激素性脱发)的基因关联性
- 特定基因(如AR基因)表达分析
- **激素水平**
- 双氢睾酮(DHT)对毛囊的影响
- 甲状腺激素失衡与脱发的关系
- **营养与代谢**
- 铁缺乏、维生素D不足与脱发的相关性
- 蛋白质摄入不足对毛发周期的影响
- **环境与生活方式**
- 压力、睡眠质量与脱发的关联
- 化学染发剂、紫外线等外部因素的损害
- **疾病与药物**
- 自身免疫疾病(如斑秃)的机制
- 化疗药物、抗抑郁药等对毛发的影响
#### 数据驱动的脱发预测方法
- **数据采集与预处理**
- 临床数据(激素水平、家族史)
- 生活方式问卷(饮食、压力水平)
- 图像数据(头皮检测、毛发密度分析)
- **特征工程**
- 关键特征的提取与筛选(如DHT浓度、毛囊微型化程度)
- 时间序列数据的处理(脱发进展趋势)
- **预测模型构建**
- 机器学习方法(随机森林、支持向量机)
- 深度学习应用(卷积神经网络处理头皮图像)
- 模型评估指标(准确率、召回率、ROC曲线)
#### 实际应用与案例分析
- **个性化脱发风险评估系统**
- 结合多模态数据生成风险评分
- 动态监测与预警机制
- **临床干预效果预测**
- 药物治疗(如米诺地尔、非那雄胺)响应预测
- 植发手术后的毛发存活率建模
挑战与未来方向
数据隐私与伦理问题
多学科协作(医学、生物信息学、AI)的深化
可穿戴设备与实时监测技术的潜力
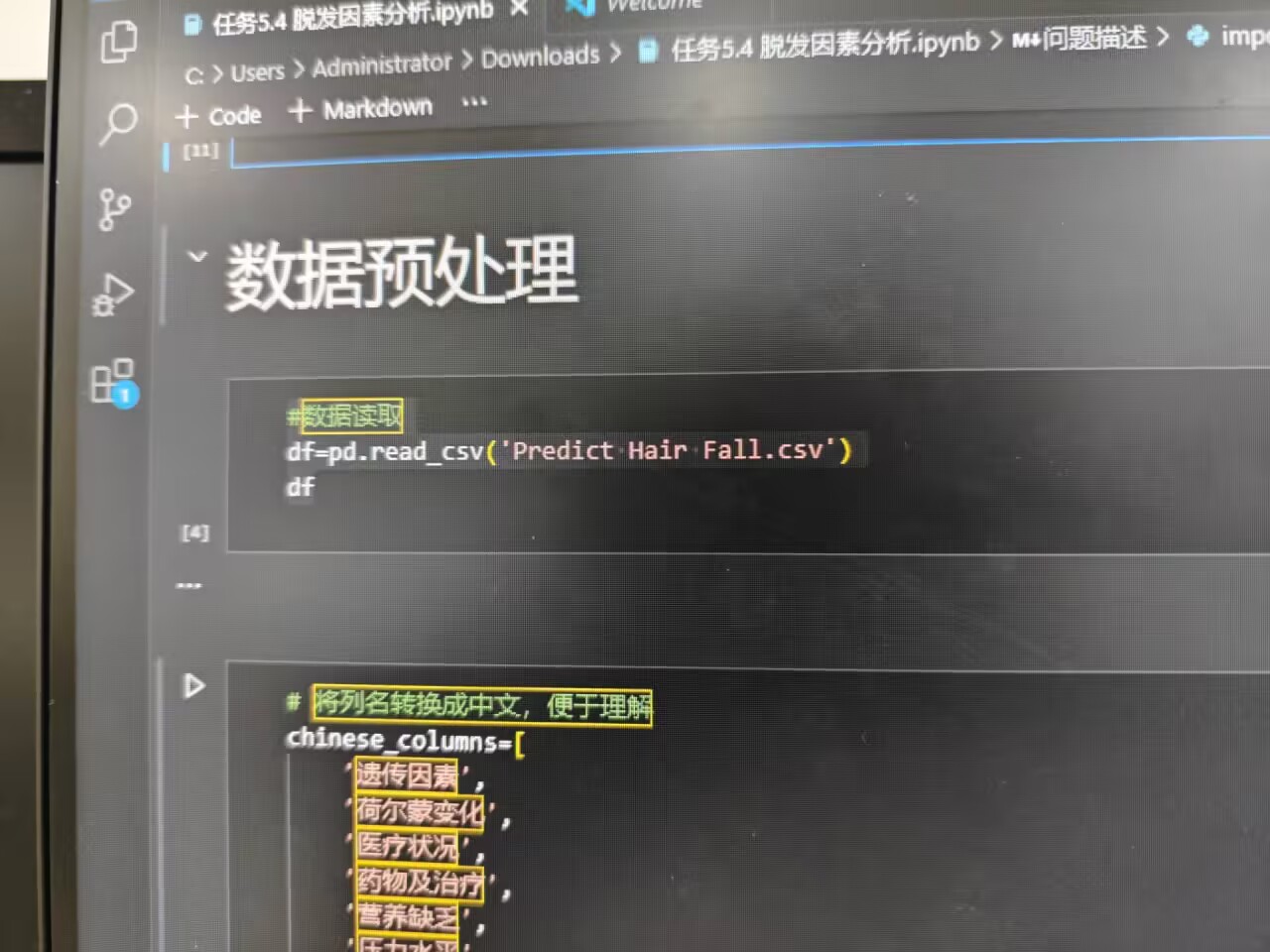
首先,使用 pandas 读取数据集 Predict Hair Fall.csv :
python
import pandas as pd
df = pd.read_csv('Predict Hair Fall.csv')
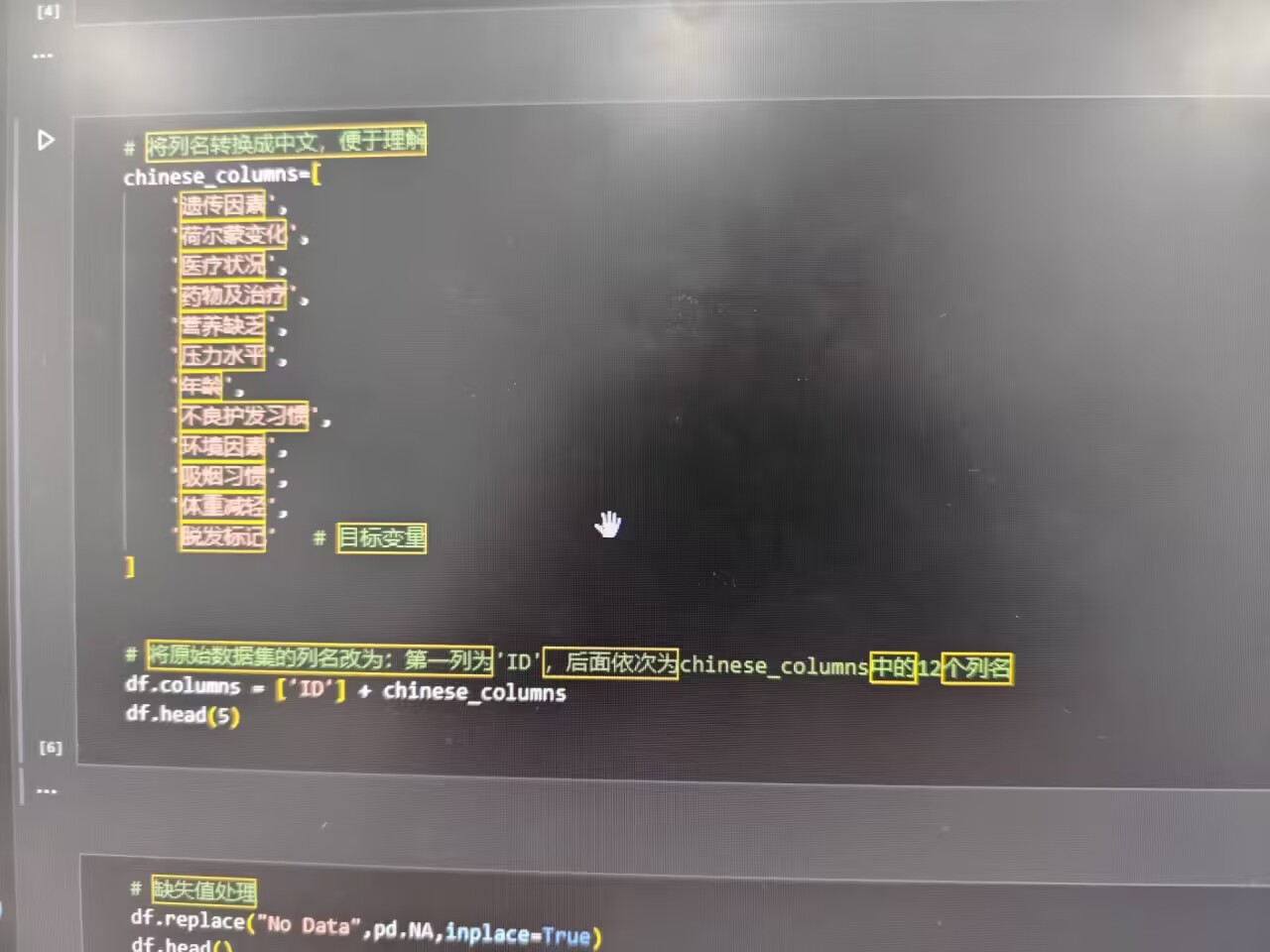
为方便理解,将英文列名转换为中文,构建中文列名列表 chinese_columns ,包含 遗传因素 、 荷尔蒙变化 等特征,再重置数据集列名 :
python
chinese_columns = [
'遗传因素', '荷尔蒙变化', '医疗状况', '药物及治疗',
'营养缺乏', '压力水平', '年龄', '不良护发习惯',
'环境因素', '吸烟习惯', '体重减轻', '脱发标记'
]
df.columns = ['ID'] + chinese_columns
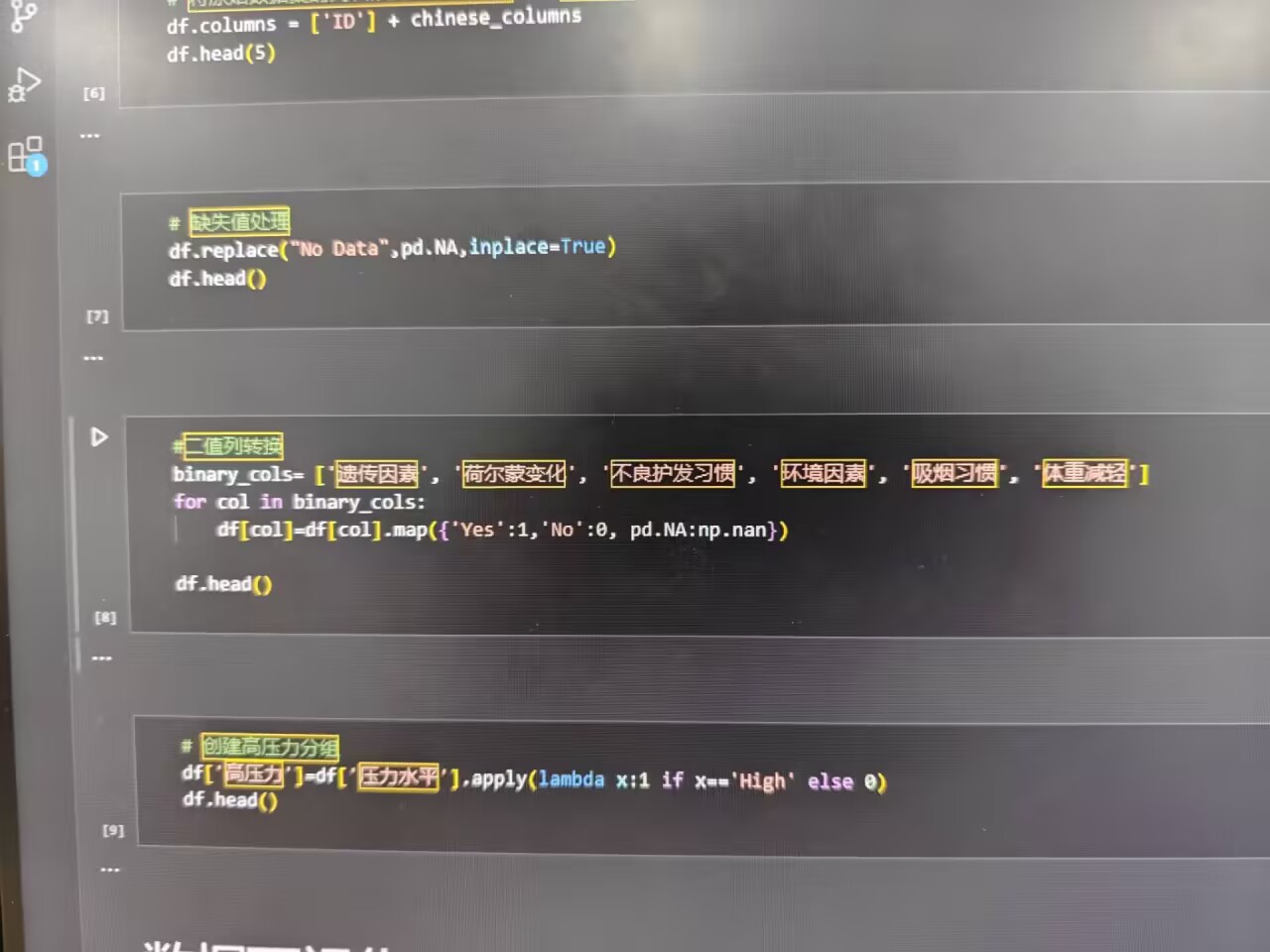
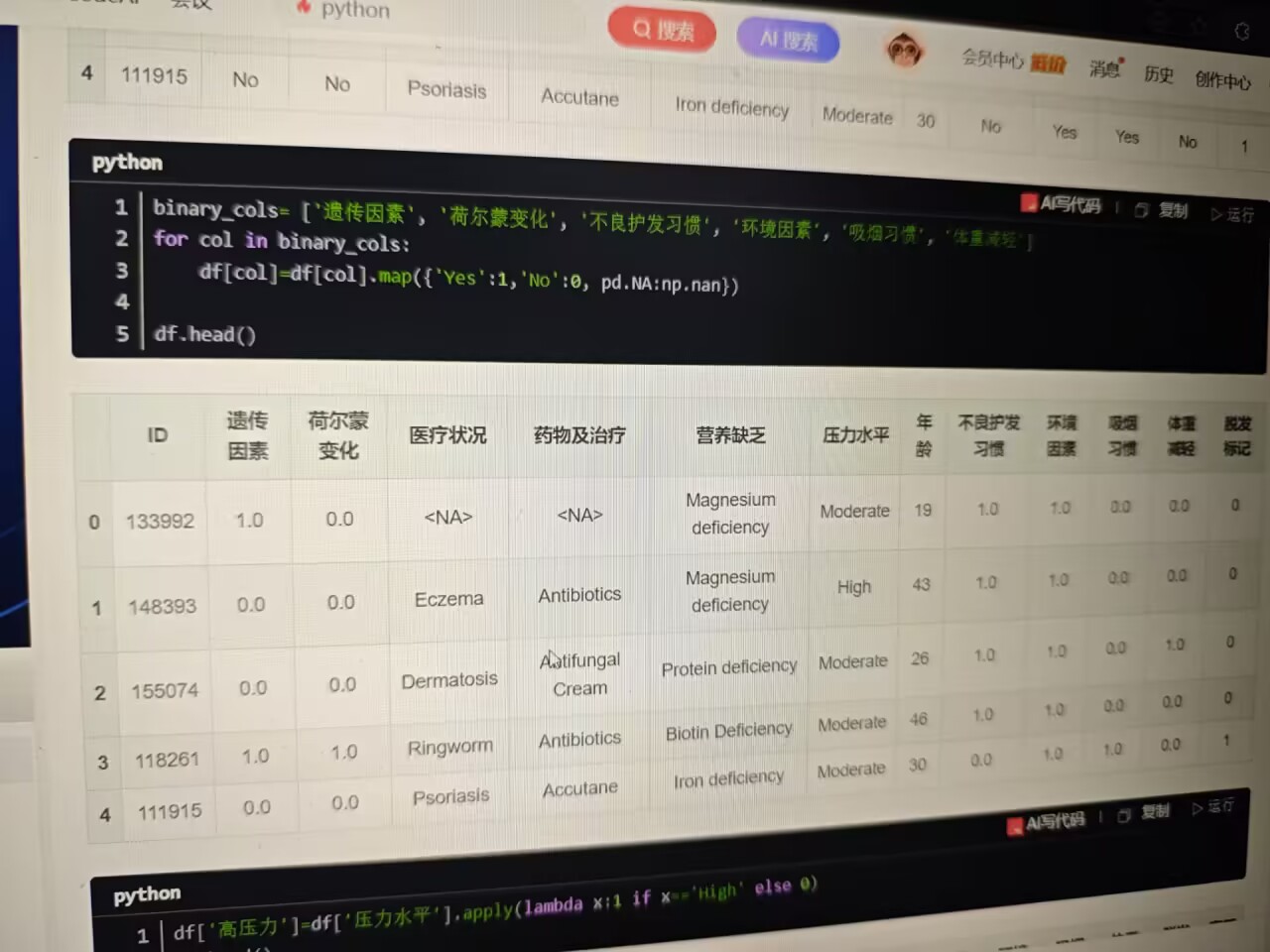
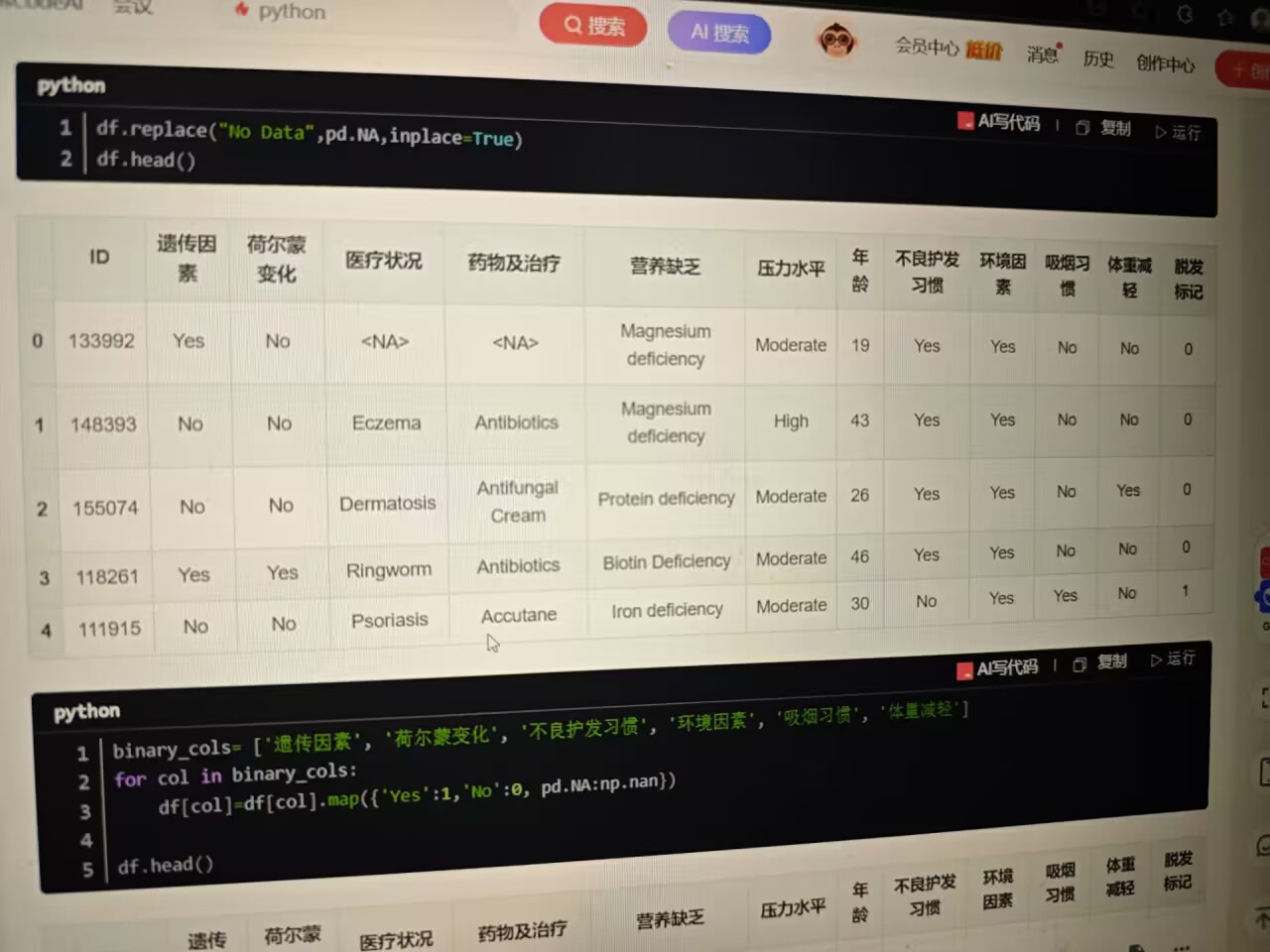
(二)缺失值与二值化处理
数据中存在标识为 No Data 的缺失值,统一转换为 pandas 标准缺失值 pd.NA :
python
df.replace("No Data", pd.NA, inplace=True)
针对 遗传因素 、 荷尔蒙变化 等二值特征(取值为 Yes 或 No ),通过 map 函数转换为数值 1 ( Yes )和 0 ( No ),缺失值转为 np.nan ,便于后续分析 :
python
import numpy as np
binary_cols = ['遗传因素', '荷尔蒙变化', '不良护发习惯', '环境因素', '吸烟习惯', '体重减轻']
for col in binary_cols:
df[col] = df[col].map({'Yes': 1, 'No': 0, pd.NA: np.nan})
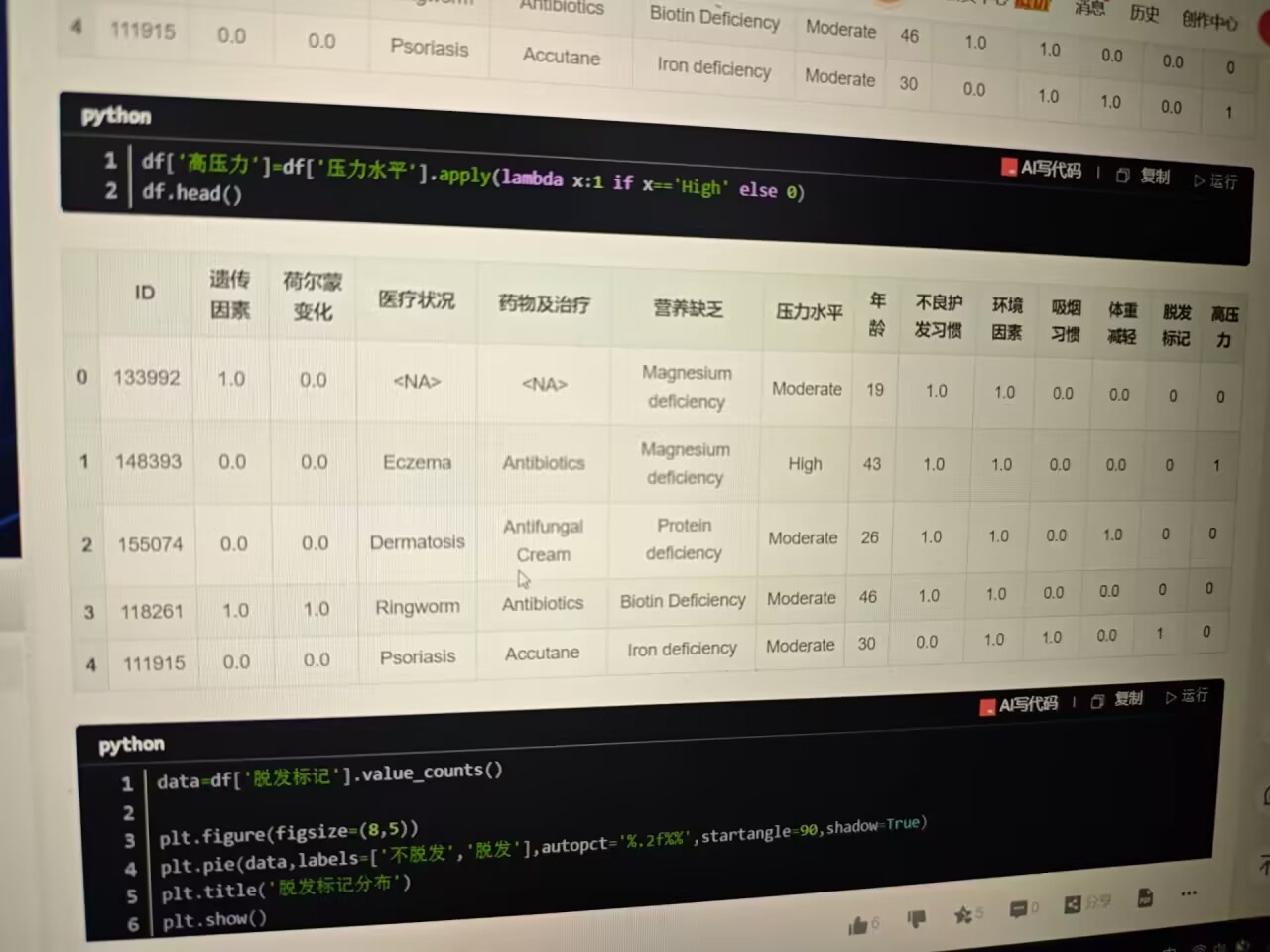
另外,从 压力水平 衍生出 高压力 二值特征,若压力水平为 High 则标记为 1 ,否则为 0 :
python
df['高压力'] = df['压力水平'].apply(lambda x: 1 if x == 'High' else 0)
三、数据可视化分析
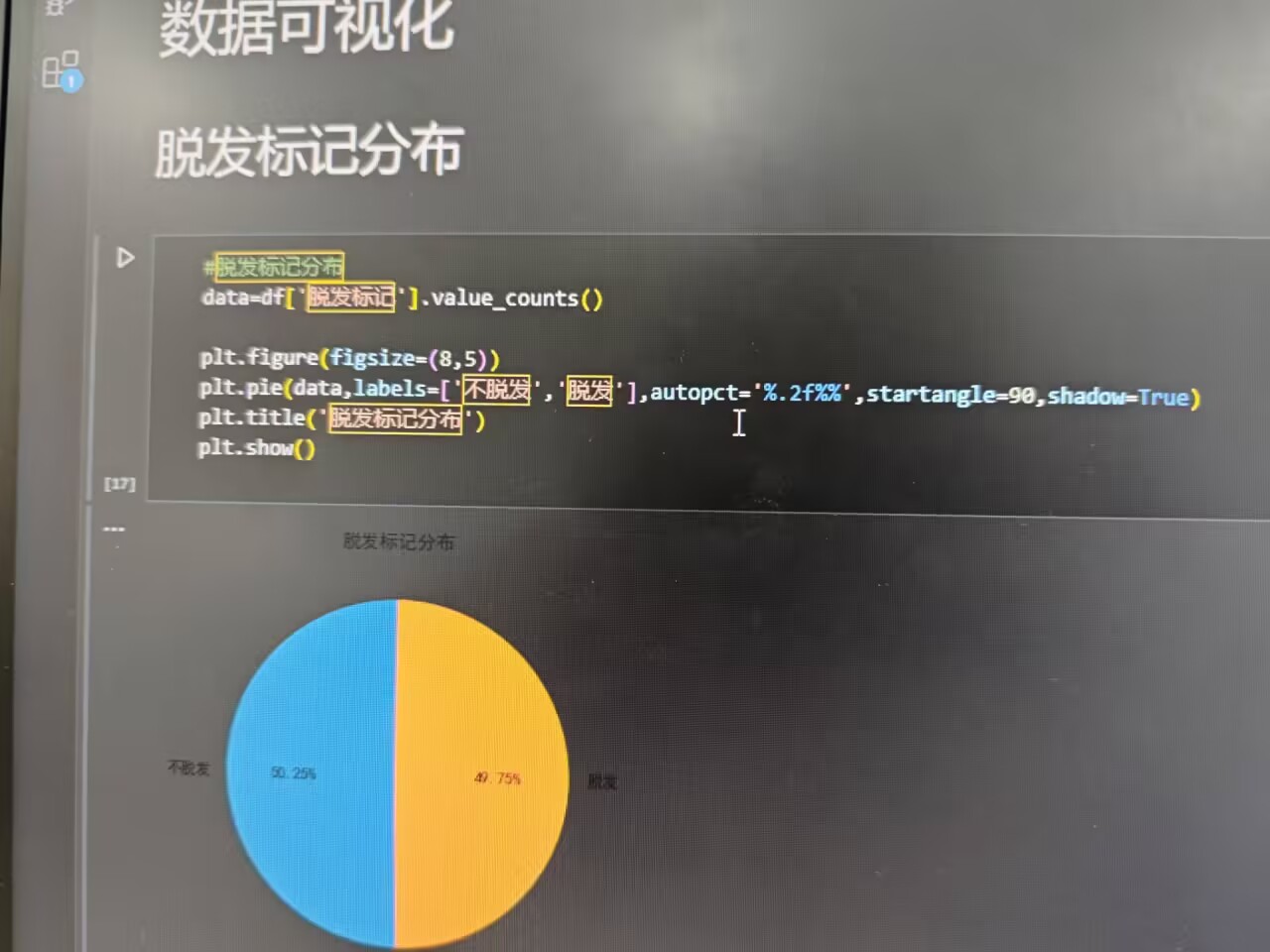
(一)脱发标记分布
先统计 脱发标记 中 脱发 和 不脱发 的人数占比,用饼图直观呈现:
python
import matplotlib.pyplot as plt
data = df['脱发标记'].value_counts()
plt.figure(figsize=(8, 5))
plt.pie(data, labels=['不脱发', '脱发'], autopct='%1.2f%%', startangle=90, shadow=True)
plt.title('脱发标记分布')
plt.show()
从饼图可快速了解样本中脱发人群的基础占比情况。
(二)二值特征与脱发关系
选取 遗传因素 、 荷尔蒙变化 等二值特征,分析它们与脱发的关联。通过 subplots 创建 3×2 布局的子图,循环遍历特征,按 脱发标记 分组统计特征取值频次,绘制分组柱状图:
python
features = ['遗传因素', '荷尔蒙变化', '不良护发习惯', '环境因素', '吸烟习惯', '体重减轻']
fig, axes = plt.subplots(3, 2, figsize=(15, 15))
axes = axes.flatten()
df['脱发标记'] = df['脱发标记'].astype('category')
categories = df['脱发标记'].cat.categories
num_categories = len(categories)
x = np.arange(num_categories)
width = 0.35
for i, feature in enumerate(features):
if i < len(axes):
ax = axes[i]
count = df.groupby('脱发标记')[feature].value_counts().unstack(fill_value=0)
rects1 = ax.bar(x - width/2, count[0], width)
rects2 = ax.bar(x + width/2, count[1], width)
ax.set_title(f'{feature}与脱发')
ax.set_xticks(x)
ax.set_xticklabels(categories)
ax.legend(['不脱发', '脱发'])
plt.tight_layout()
plt.show()
每组柱状图对比不同脱发情况(脱发 / 不脱发 )下,对应特征的分布差异,助力挖掘关键影响因素。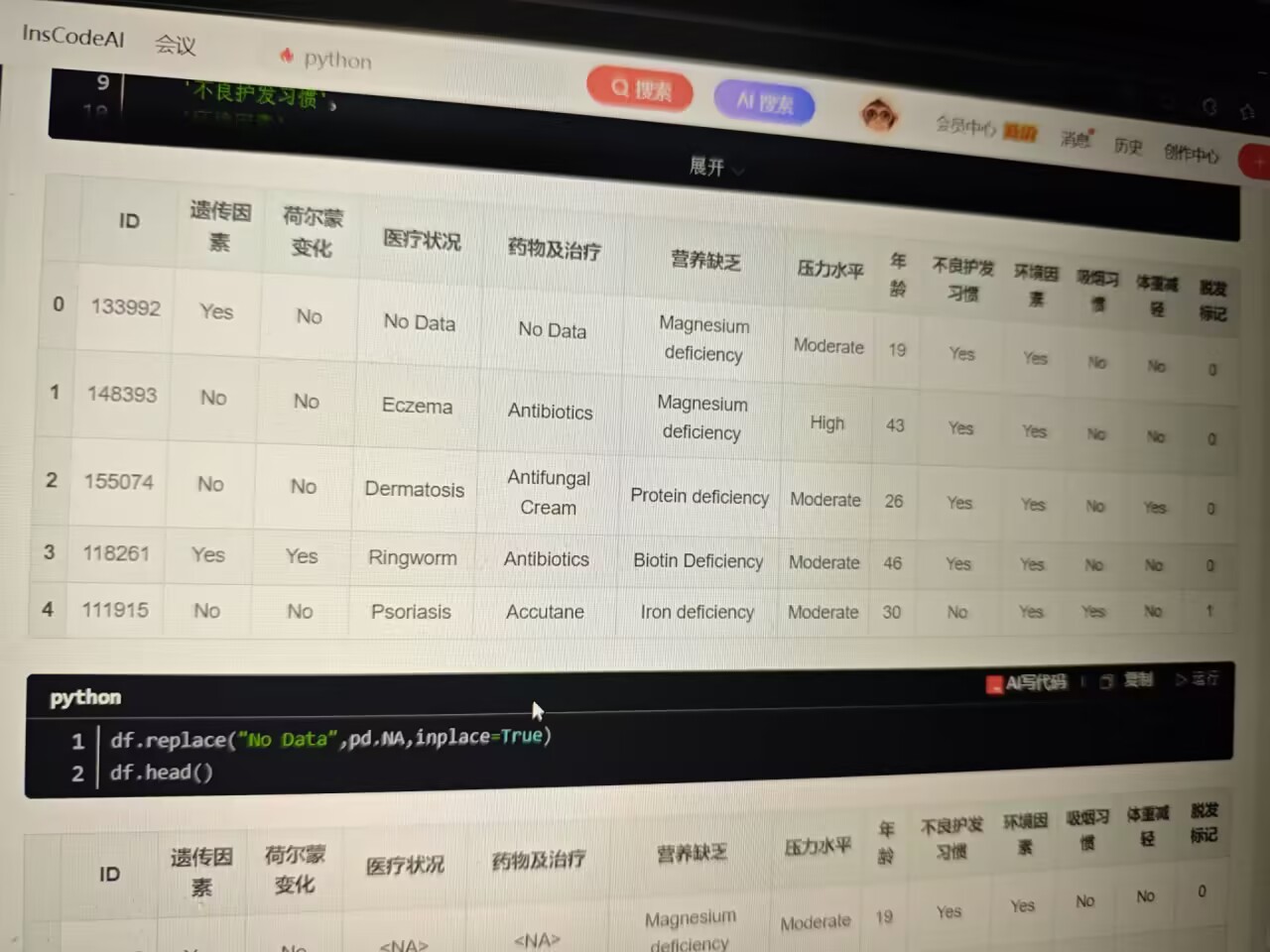
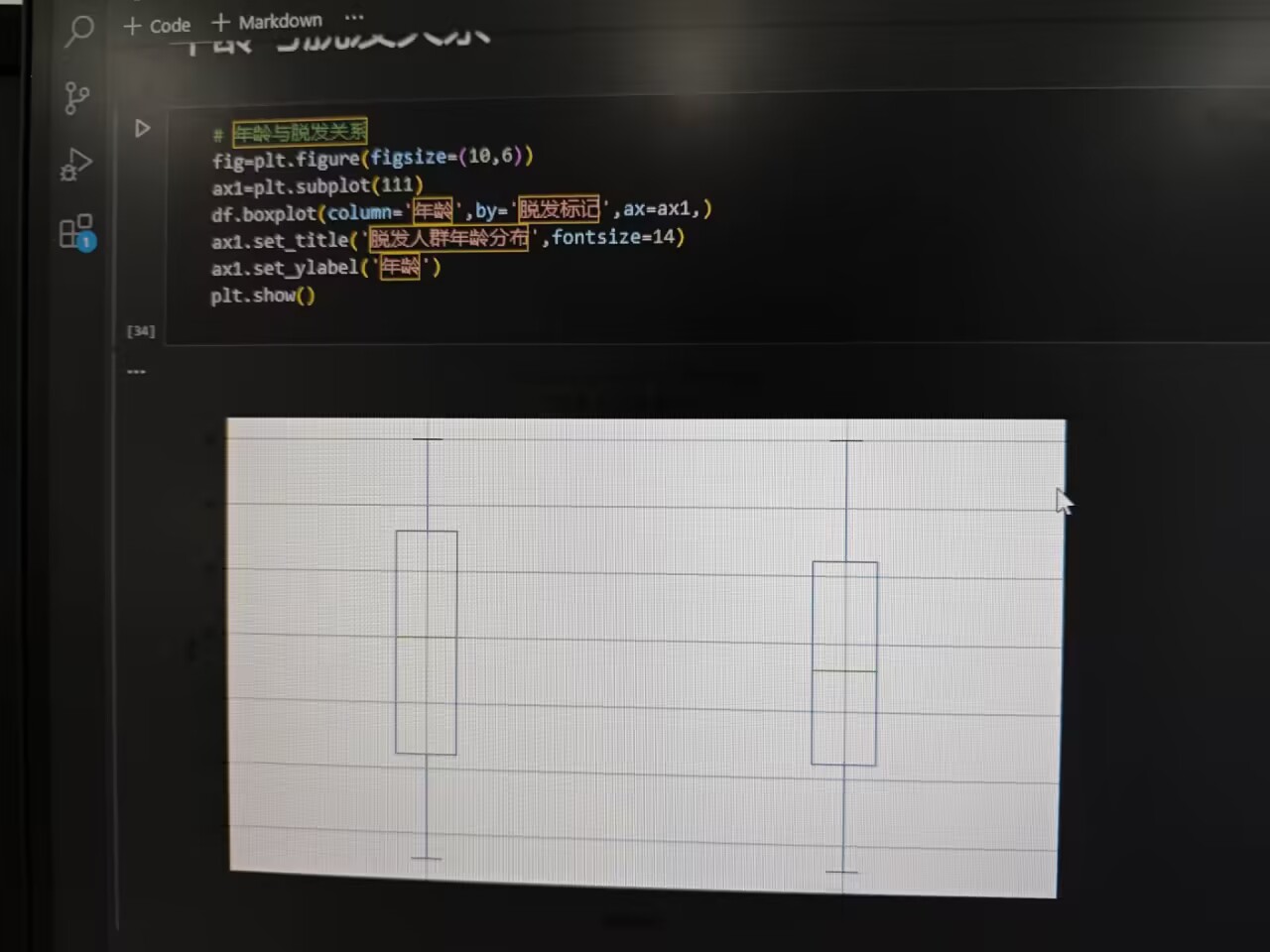
(三)年龄与脱发关系
利用箱线图展示脱发和不脱发人群的年龄分布差异,观察年龄对脱发的潜在影响:
python
plt.figure(figsize=(10, 6))
ax1 = plt.subplot(111)
df.boxplot(column='年龄', by='脱发标记', ax=ax1)
ax1.set_title('脱发人群年龄分布', fontsize=14)
ax1.set_ylabel('年龄')
plt.show()
箱线图呈现出年龄的中位数、离散程度等信息,辅助分析年龄与脱发的关联。
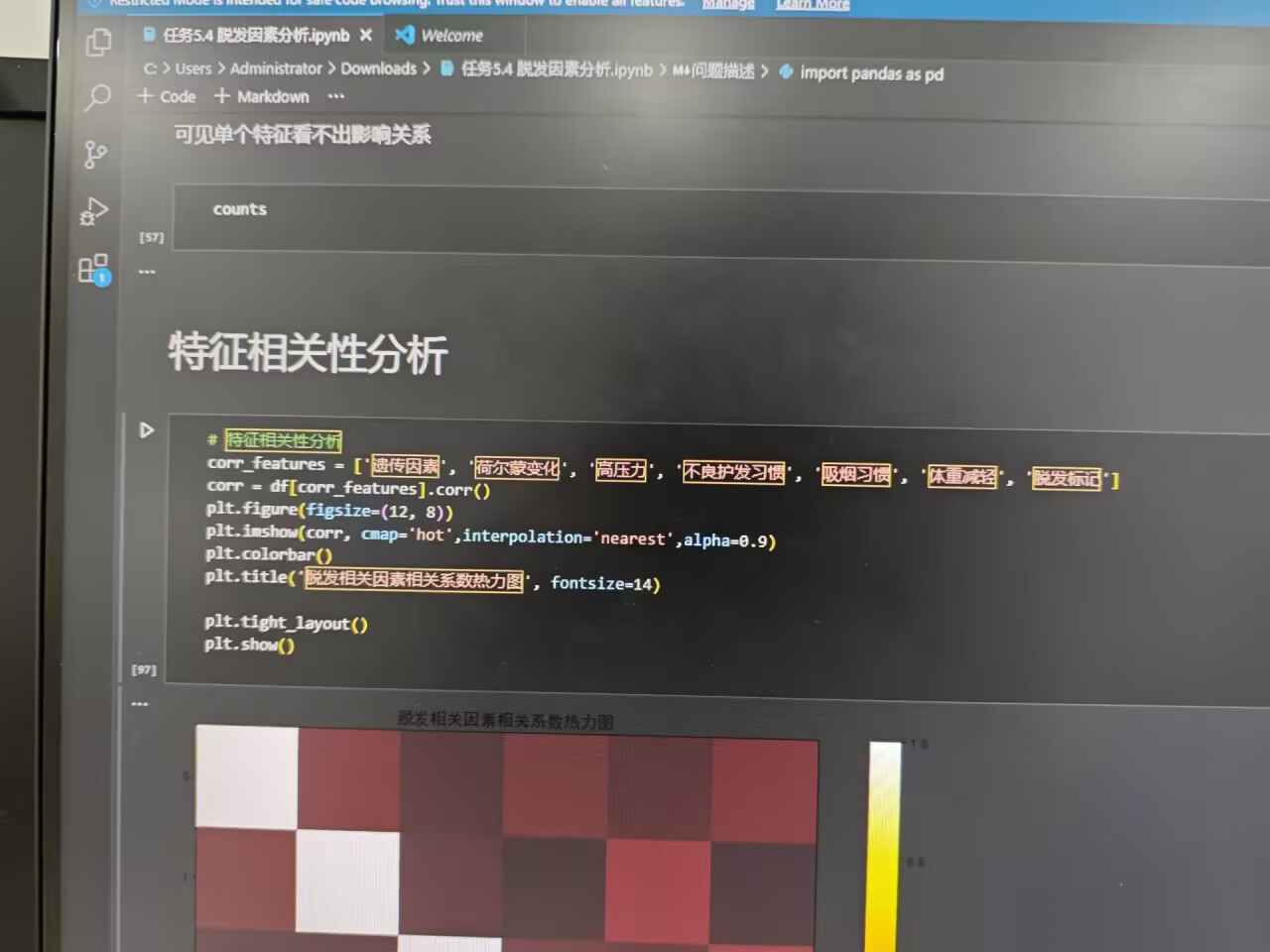
(四)特征相关性分析
选取 遗传因素 、 高压力 等特征,计算相关系数,用热力图可视化特征间关联,重点关注与 脱发标记 的相关性:
python
corr_features = ['遗传因素', '荷尔蒙变化', '高压力', '不良护发习惯', '吸烟习惯', '体重减轻', '脱发标记']
corr = df[corr_features].corr()
plt.figure(figsize=(12, 8))
plt.imshow(corr, cmap='hot', interpolation='nearest', alpha=0.9)
plt.colorbar()
plt.title('脱发相关因素相关系数热力图', fontsize=14)
plt.show()
热力图以颜色深浅直观呈现特征间相关程度,便于发现对脱发影响显著的因素。
(五)医疗状况与脱发分析
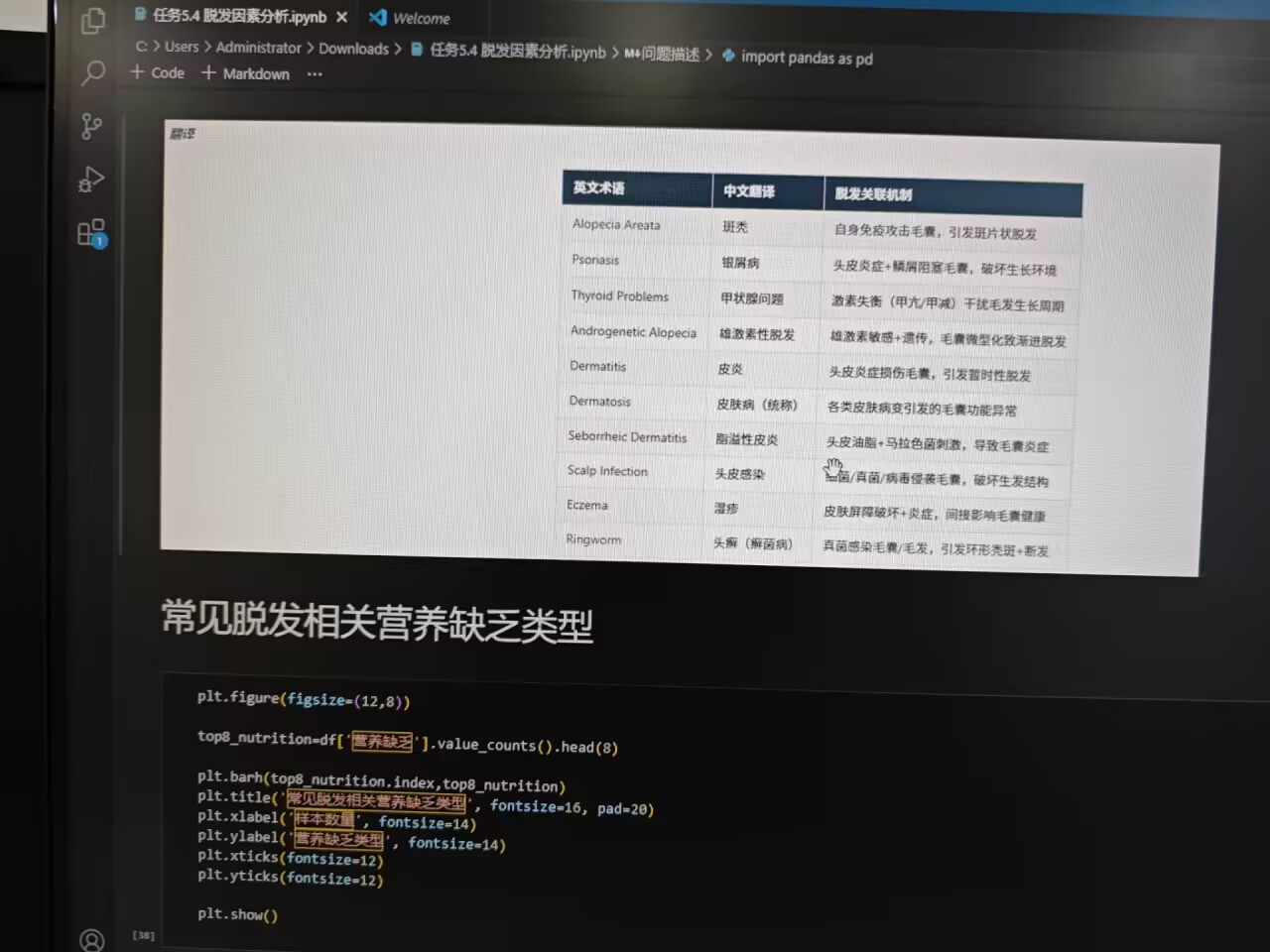
统计 医疗状况 字段的 Top10 类别,绘制横向柱状图,探索脱发人群常见医疗状况:
python
plt.figure(figsize=(12, 8))
top_conditions = df['医疗状况'].value_counts().head(10)
plt.barh(top_conditions.index, top_conditions)
plt.title('十大常见脱发相关医疗状况', fontsize=14)
plt.xlabel('样本数量', fontsize=12)
plt.ylabel('医疗状况', fontsize=12)
plt.tight_layout()
plt.show()
该图清晰展示与脱发关联紧密的医疗状况分布,为从医学角度分析脱发提供参考。
四、总结与展望
通过本次数据分析与可视化,我们从多个维度(二值特征、年龄、医疗状况等 )探究了脱发的影响因素。遗传、不良生活习惯、特定医疗状况等都和脱发存在潜在关联。后续可进一步结合机器学习模型(如随机森林、支持向量机 ),深入挖掘特征重要性,构建脱发预测模型,为脱发预防和干预提供更精准的依据,助力大家守护头发健康 。
一、引言
在全球疾病谱中,心脏病始终占据着高发病、高致死率的“沉重席位”。随着医疗信息化推进,海量临床数据积累为疾病研究提供新契机。本文基于真实医疗数据集,以Python为工具,完整呈现心脏病数据分析与分类模型构建全流程——从数据清洗、特征洞察,到多模型训练评估,为医疗领域数据驱动诊断提供可落地的实践参考,助力挖掘数据背后的疾病诊疗价值。
二、数据准备:开启医疗数据探索之旅
(一)环境与库配置
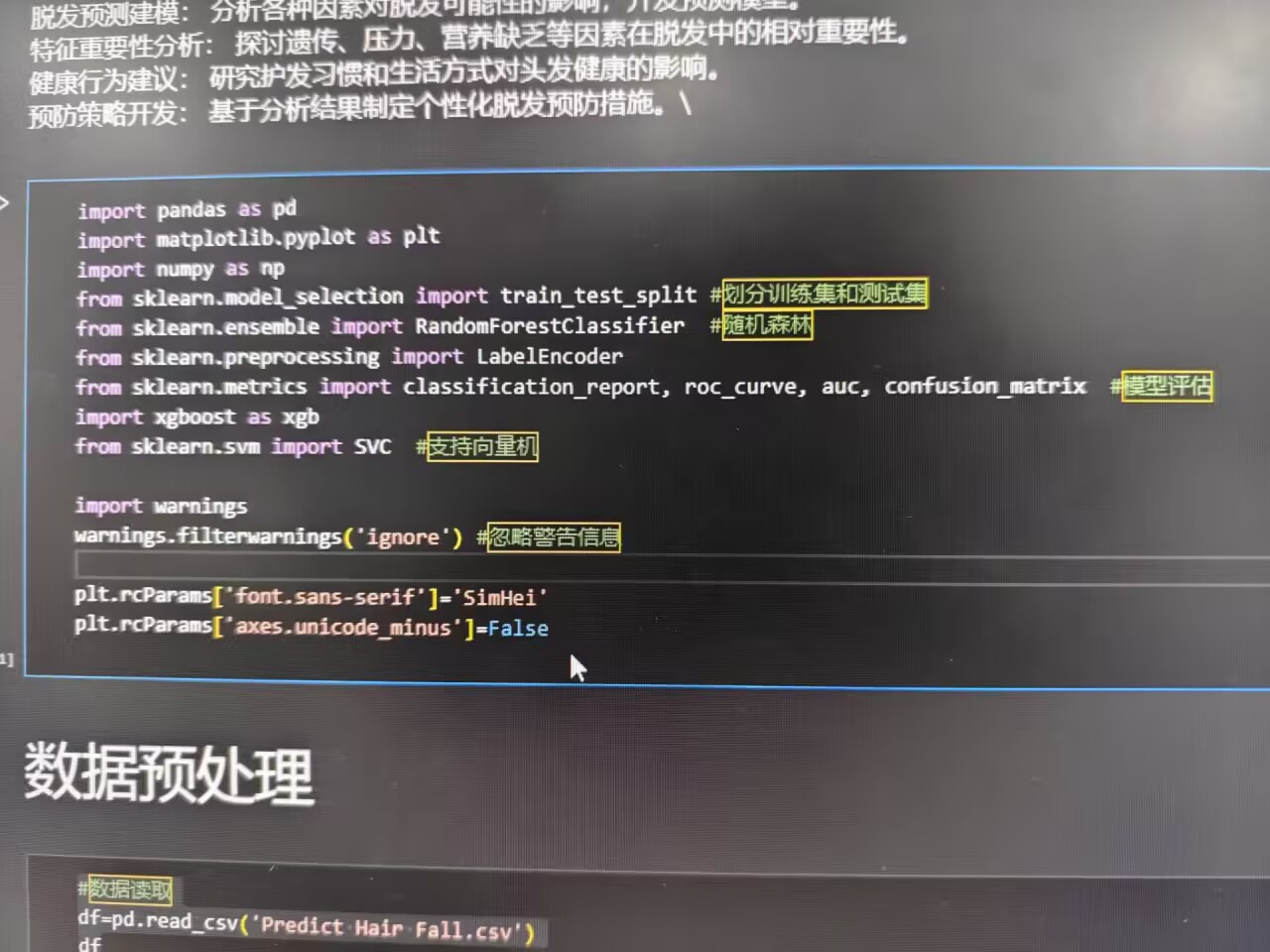
导入数据分析核心库,涵盖数据处理( pandas / numpy )、可视化( matplotlib )、机器学习( scikit-learn / xgboost )工具,同时解决中文显示、警告屏蔽等基础问题,搭建稳定分析环境:
python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, confusion_matrix, roc_curve, auc
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from xgboost import XGBClassifier
import warnings
warnings.filterwarnings('ignore')
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
(二)数据读取与初览
读取医疗数据集 Medicaldataset.csv ,通过 head() 快速预览数据结构,识别关键字段(如 Age 年龄、 Result 诊断结果等 ),明确特征维度与目标变量( positive / negative 标识患病状态 ):
python
data = pd.read_csv('Medicaldataset.csv')
print("数据集前5行:")
print(data.head())
三、数据预处理:为分析与建模筑牢根基
(一)数据质量核验
利用 info() 查看数据完整性与类型分布,确认无缺失值、数据类型适配( int64 / float64 / object ),保障分析流程顺畅:
python
print("数据基本信息:")
data.info()
(二)重复与异常值处理
- 重复值清理:通过 duplicated().sum() 排查重复记录, drop_duplicates() 确保数据唯一性:
python
print(f"重复值数量:{data.duplicated().sum()}")
data = data.drop_duplicates()
- 异常值检测与修正:绘制箱线图识别心率、血压等特征的极端异常值,结合医疗常识删除不合理记录(如心率>1000 ),修正舒张压>收缩压的逻辑错误,让数据贴合实际诊疗场景:
python
# 箱线图可视化异常(以心率为例)
plt.figure(figsize=(8, 6))
plt.boxplot(data['Heart rate'])
plt.title('心率箱线图(异常值检测)')
plt.ylabel('心率值')
plt.show()
# 异常值过滤
data = data[data['Heart rate'] <= 1000]
data = data[data['Systolic blood pressure'] >= 50]
data = data[data['Diastolic blood pressure'] <= 140]
# 修正舒张压与收缩压逻辑错误
wrong_bp = data[data['Diastolic blood pressure'] > data['Systolic blood pressure']]
data.loc[wrong_bp.index, ['Systolic blood pressure', 'Diastolic blood pressure']] = data.loc[wrong_bp.index, ['Diastolic blood pressure', 'Systolic blood pressure']].values
四、数据分析与可视化:挖掘疾病潜在规律
(一)描述性统计:勾勒数据轮廓
通过 describe().T 获取各特征的均值、标准差、最值等统计量,把握患者年龄、心率、血压等指标的整体分布特征,为后续分析提供基础参考:
python
print("数据描述性统计:")
print(data.describe().T)
(二)单特征分布:洞察个体特征规律
以年龄、性别为例,绘制核密度图+直方图、饼图,多维呈现数据分布。年龄核密度图揭示分布形态,直方图量化区间人数;性别饼图直观展现男女占比,助力理解患者群体基线特征:
python
# 年龄分布可视化
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
data['Age'].plot(kind='kde', color='r', label='核密度')
data['Age'].plot(kind='hist', bins=10, alpha=0.3, label='直方图')
plt.title('患者年龄分布')
plt.xlabel('年龄')
plt.ylabel('密度/数量')
plt.legend()
# 性别分布可视化(饼图)
plt.subplot(1, 2, 2)
gender_counts = data['Gender'].value_counts()
plt.pie(gender_counts, labels=['男', '女'], autopct='%1.1f%%', startangle=90)
plt.title('患者性别分布')
plt.axis('equal')
plt.show()
(三)特征与诊断关联:探寻疾病影响因素
通过箱线图、分组统计分析年龄、心率、 CK-MB (肌酸激酶同工酶 )等特征与诊断结果( positive 患病/ negative 未患病 )的关联。箱线图对比患病与未患病群体的特征分布差异,分组统计量化特征对诊断结果的影响,挖掘潜在疾病标识:
python
# 年龄与诊断结果关联(箱线图)
positive_age = data[data['Result'] == 'positive']['Age']
negative_age = data[data['Result'] == 'negative']['Age']
plt.figure(figsize=(8, 6))
plt.boxplot([positive_age, negative_age], labels=['患病', '未患病'])
plt.title('年龄与心脏病诊断结果关联')
plt.ylabel('年龄')
plt.show()
# CK-MB与诊断结果关联(分组均值)
ckmb_mean = data.groupby('Result')['CK-MB'].mean()
print("CK-MB均值(按诊断结果分组):")
print(ckmb_mean)
根据上面我们可得脱发的数据
当我们用Python完成这场脱发数据的深度挖掘之旅,代码运行的最后一行 plt.show() 落下,那些蓝色柱状图、热力色块里藏着的,不只是冰冷的统计结果,而是无数程序员“头顶大事”的真实映照。
一、代码之外的“防脱启示”
看着 RandomForestClassifier 输出的特征重要性,遗传、压力、不良习惯的高权重,像极了代码里总报错的核心模块——这些因素就是脱发问题的“顽固Bug” 。我们能通过 LabelEncoder 给分类变量编码,却没法给生活压力“一键转译”;能 dropna 剔除数据缺失,却不能用同样的方式“删掉”熬夜改需求、紧急修故障的职场日常。
但技术人的浪漫,本就在于“遇Bugdebug,遇难题解题”。就像用 corr() 算出压力与脱发的强关联后,我们大可以给生活写一段“防脱补丁代码”:
python
# 防脱生活补丁伪代码
import time
def life_patch():
while True:
stress = check_stress() # 监测压力
if stress > 80: # 压力阈值自定义
take_break() # 强制休息
do_exercise() # 运动减压
time.sleep(3600) # 每小时监测一次
把“定时休息、规律运动”写成生活的循环逻辑,让毛囊也能像稳定运行的服务器,少点“崩溃宕机”。
二、数据驱动的“头顶希望”
这份分析里, Predict Hair Fall.csv 的每一行数据,都是对抗脱发的“情报”。当我们用 matplotlib 画出年龄与脱发的箱线图,看到中青年群体的离散值,就该明白——防脱要趁早,别等发际线像代码版本迭代,一步步“退化”才追悔 。
后续若结合 pyecharts 做动态可视化,让脱发因素随时间、地域流动展示,或是用 Streamlit 打包成交互页面,输入生活习惯就能预测脱发风险,技术还能给“头顶保卫战”更多助力。就像我们用代码优化算法模型,也能用同样的思路,优化自己的生活模型:
python
# 生活优化模型(伪代码)
from sklearn.linear_model import LinearRegression
# 特征:睡眠时长、运动频率、压力值...
X_life = [[sleep_hours, exercise_freq, stress_level]]
# 目标:毛囊健康度(可量化)
y_life = [follicle_health]
model = LinearRegression().fit(X_life, y_life)
# 预测:输入新习惯,看毛囊健康趋势
new_habits = [[7, 3, 50]] # 7小时睡眠、每周3次运动、压力50
pred_health = model.predict(new_habits)
print(f"新习惯下毛囊健康度预测:{pred_health[0]}")
三、与脱发和解,更与自己和解
最后,即便代码跑完发现脱发风险高悬,也别慌。就像调试代码时总会遇到 KeyError ,生活里的“脱发Error”,也是成长的一部分。我们用技术挖掘脱发真相,不是为了焦虑,而是为了更懂自己——懂那些为项目熬的夜、为需求掉的发,都该有更值得的回报;懂守护发际线,和守护代码质量一样重要。
下次再对着键盘缝隙里的头发叹气时,不妨打开这份分析,用代码人的方式说:“脱发Bug,我找到你的触发条件了,接下来该我修复生活啦!”
(完整代码及可视化扩展已上传 GitHub仓库 ,欢迎技术同好一起迭代“防脱算法”,让我们的代码和头发,都能支棱起来✨)

















 286
286

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









