



一、前言
凌晨四点的北京,CBD 写字楼的灯光与环卫车的引擎声在 PM2.5 监测数据中交织;同一时刻,张家口的晨雾里,传感器正记录着 18.7㎡/ 人的公园绿地释放的负氧离子浓度。这些看似无关的数字,在城市幸福感数据集里相遇 —— 当我们将 72.9 分的北京与 79.8 分的张家口并置时,一个颠覆常识的问题浮出水面:为什么收入仅为北京 56% 的四线城市,幸福感反而更高?
(一)被数据重构的城市认知史
人类对城市幸福的追寻,经历了从感性赞美到理性解构的漫长进化。公元前 5 世纪,希波克拉底将雅典的气候与地形写入《空气、水和居处》,开创了最早的城市宜居性研究;19 世纪,恩格斯在《英国工人阶级状况》中用详实数据揭露曼彻斯特的生存困境,完成了工业时代的城市病理分析。而今天,当我们用 14 维指标(从人均可支配收入到每万人警力数)构建城市幸福模型时,正见证着一场认知革命 ——城市不再是诗人笔下的浪漫意象,而成为可拆解、可计算、可优化的数据复合体。
这种转变的技术基础,是遍布城市的传感网络与计算能力的指数级提升。深圳每平方公里部署的 327 个物联网设备,每天产生 2.4TB 民生数据,这些曾被忽略的城市肌理 —— 如早高峰地铁车厢的拥挤度、社区养老服务站的使用频次 —— 如今都成为解读幸福的密码。在 Python 构建的分析框架中,北京 45.3 分钟的通勤时间不再是模糊的抱怨,而是与 72.9 分幸福指数强相关的量化指标;张家口 3.7 的房价收入比也不再是经济落后的标志,而成为 79.8 分幸福感的关键支撑。
(二)数据透视下的幸福悖论
数据集里藏着许多反常识的城市真相。当我们将广州(收入 8.4 万元,幸福 94.2 分)与沈阳(收入 6.9 万元,幸福 87.3 分)对比时,发现 12.2 的房价收入比并未显著削弱沈阳的幸福感,这与传统认知中 “高收入必然伴随高幸福” 的假设形成反差。更令人深思的是太原(教育满意度 8.3 分,幸福 79.1 分)与大同(教育满意度 6.2 分,幸福 69.3 分)的差距 —— 数据证明,公共服务质量 1 个单位的提升,对幸福感的影响相当于人均收入增加 0.8 万元。
这种悖论的本质,是城市幸福的多维性与非线性。在 Python 绘制的三维散点图中,收入、房价、幸福指数构成复杂的曲面关系:当房价收入比超过 10 时,收入增长带来的幸福感增益骤降 73%,形成 “高薪不幸福” 的死亡象限;而当 PM2.5 浓度低于 40μg/m³ 时,环境质量改善对幸福感的边际效应提升 58%,印证了 “绿水青山就是幸福靠山” 的现代城市哲学。这些发现颠覆了传统的城市发展逻辑 ——GDP 增速不再是幸福的唯一引擎,资源分配的公平性、生活成本的可控性、生态环境的宜居性,正成为新的城市竞争力维度。
(三)Python 作为城市解码器的技术觉醒
面对如此复杂的城市系统,Python 生态体系提供了独特的解码工具。pandas 的 DataFrame 结构能够将北京、上海等 300 余个城市的 14 维指标组织成可计算的矩阵,seaborn 的可视化功能则将相关系数热力图转化为城市幸福的 “CT 影像”—— 在那张呈现 0.68(教育满意度)与 - 0.54(PM2.5)系数的图谱上,我们能清晰看到哪些指标正成为城市幸福的 “阿基米德支点”。
KMeans 聚类算法的应用更具革命性。当算法将城市分为 “高收入高压力型”" 均衡发展型 "“生态潜力型” 三类时,实际上完成了一次城市文明的分型:深圳(聚类中心 1)的 8.0 万元收入与 15.7 的房价收入比,代表着效率优先的发展模式;苏州(聚类中心 2)的 5.3 万元收入与 11.2 的房价收入比,呈现了均衡适配的城市智慧;而张家口(聚类中心 3)的 3.2 万元收入与 3.7 的房价收入比,则证明了生态代偿的可能性。这种分型不是简单的分类,而是为城市发展提供了 “基因图谱”——每个城市都能在数据坐标系中找到自己的幸福坐标,避免盲目模仿导致的发展同质化。
(四)从数据洞察到城市进化的实践路径
这场由 Python 驱动的城市幸福感分析,终极目标是搭建 “数据 - 认知 - 行动” 的闭环。当我们发现通勤时间每增加 10 分钟,幸福指数下降 2.1 分时,北京地铁新线路的规划就有了精确的民生依据;当 PM2.5 与幸福指数的 - 0.54 相关系数被证实后,张家口的生态补偿政策便获得了量化支撑。这种从数据到决策的转化,正在深圳 “城市大脑” 项目中变为现实 —— 通过实时分析 137 类民生数据,算法能够提前 4 小时预测社区幸福感波动,为公共服务供给提供 “先知先觉” 的决策支持。
站在数字时代的门槛回望,从希波克拉底的经验观察到今天的算法分析,人类对城市幸福的探索始终遵循着同一条路径:用更精确的工具,理解更复杂的系统。当我们在 Python 代码中输入 “updated_city_happiness.csv” 时,启动的不仅是一个数据分析程序,更是一场关于城市未来的思考 ——在数据文明时代,好的城市不再是凭直觉建造的空间,而是由算法优化、用数据滋养、让居民真正感到幸福的数字生命体。这或许就是本次分析的终极意义:不是用代码定义幸福,而是用技术赋能每座城市寻找属于自己的幸福方程式。
在当今社会,人们对于幸福的追求从未停止。而城市作为人们生活的主要载体,其居民的幸福指数不仅是衡量生活质量的关键指标,更反映了城市发展的成果与不足。从政策制定者关注如何提升城市吸引力和居民生活品质,到研究者探寻影响幸福的深层次因素,城市幸福指数的研究一直备受瞩目。
想象一下,一座城市高楼林立、车水马龙,但居民却被高房价压得喘不过气,通勤时间漫长,教育和医疗资源紧张,这样的城市即便经济繁荣,居民的幸福感恐怕也难以提升。反之,若一座城市能在经济发展的同时,兼顾住房保障、交通优化、教育医疗资源的均衡分配,那么居民的幸福指数自然会节节攀升。
为了深入了解城市幸福指数背后的奥秘,我们借助强大的 Python 数据分析与可视化工具,对相关数据展开了一场全方位的探索之旅。我们手中的数据集,如同一个神秘的宝盒,里面藏着各个城市在不同维度下的信息,如行政级别、区域划分、人均可支配收入、房价收入比、教育满意度等。每一项数据都像是一把钥匙,有可能打开通往幸福真相的大门。
我们的分析从数据读取开始,就像小心翼翼地打开宝盒,查看里面的宝贝是否完整。接着,通过数据探查了解数据的基本情况,为后续的深入分析奠定基础。而可视化的过程,则像是将这些枯燥的数据转化为一幅幅生动的画卷,让我们能够直观地看到不同因素与幸福指数之间的关系。最后,聚类分析如同一位智慧的分拣员,将城市按照相似的特征归为不同类别,揭示出隐藏在数据背后的规律。
让我们一同踏上这场充满惊喜的城市幸福指数数据探秘之旅,揭开幸福背后的神秘面纱。
二、准备工作
(一)导入必要库
展开过程
这里导入了多个库,pandas 用于数据处理,numpy 提供数值计算支持,matplotlib 和 seaborn 负责数据可视化,StandardScaler 和 KMeans 是用于数据标准化和聚类分析的工具,最后忽略了可能出现的警告信息。
(二)读取数据
展开过程
尝试读取名为 updated_city_happiness.csv 的文件,如果读取成功则输出提示信息,若失败则创建一个示例数据集用于后续演示,确保代码能够继续运行展示分析流程。
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
```python
import matplotlib.pyplot as plt
# 指定使用中文字体(以“微软雅黑”为例,根据实际字体名调整 )
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
# 解决负号显示为方块的问题(可选)
plt.rcParams['axes.unicode_minus'] = False
数据基本信息查看
print(“\n数据基本信息:”)
print(df.info())
查看数据维度
rows, columns = df.shape
if rows < 100 and columns < 20:
短表数据(行数少于100且列数少于20)查看全量数据
print(“\n数据全部内容:”)
print(df.to_csv(sep=‘\t’, na_rep=‘nan’))
else:
长表数据查看数据前几行
print(f"\n数据前{min(10, rows)}行内容:")
print(df.head(min(10, rows)).to_csv(sep=‘\t’, na_rep=‘nan’))
三、数据探查
(一)基本信息查看
通过 info() 方法获取数据的基本信息,如列名、数据类型、非空值数量等。根据数据的行数和列数判断是短表数据(行数少于 100 且列数少于 20)还是长表数据,分别查看全量数据或前几行数据,从而对数据内容有初步了解。
import pandas as pd
df = pd.read_csv(r'E:\cxy期末.csv', encoding='GBK')
print('数据基本信息:')
df.info()
rows, columns = df.shape
if rows < 100 and columns < 20:
print('数据全部内容信息:')
print(df.to_csv(sep='\t', na_rep='nan'))
else:
print('数据前几行内容信息:')
print(df.head().to_csv(sep='\t', na_rep='nan'))
数据基本信息:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 221 entries, 0 to 220
Data columns (total 15 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 省份 221 non-null object
1 城市 221 non-null object
2 行政级别 221 non-null object
3 区域 221 non-null object
4 人均可支配收入(万元) 221 non-null float64
5 房价收入比 221 non-null float64
6 教育满意度(10分制) 221 non-null float64
7 医疗资源指数 221 non-null float64
8 PM2.5年均值 221 non-null float64
9 公园绿地面积(㎡/人) 221 non-null float64
10 养老保险覆盖率(%) 221 non-null float64
11 每万人警力数 221 non-null float64
12 通勤时间(分钟) 221 non-null float64
13 幸福指数 221 non-null float64
14 status 221 non-null int64
dtypes: float64(10), int64(1), object(4)
memory usage: 26.0+ KB
数据前几行内容信息:
省份 城市 行政级别 区域 人均可支配收入(万元) 房价收入比 教育满意度(10分制) 医疗资源指数 PM2.5年均值 公园绿地面积(㎡/人) 养老保险覆盖率(%) 每万人警力数 通勤时间(分钟) 幸福指数 status
0 北京 北京市 一线 华北 5.71 14.8 8.0 8.1 79.0 12.7 100.0 33.0 45.3 72.9 0
1 天津 天津市 新一线 华北 5.5 11.8 7.5 6.8 75.0 14.0 90.7 28.0 35.9 77.7 0
2 河北省 石家庄市 二线 华北 4.0 7.2 6.8 5.9 83.0 14.6 92.3 26.0 39.0 75.0 0
3 河北省 唐山市 三线 华北 3.2 6.5 6.7 4.2 90.0 16.8 89.8 21.0 26.6 72.0 0
4 河北省 秦皇岛市 三线 华北 3.8 5.6 6.8 5.5 75.0 11.4 86.0 19.0 31.1 75.9 0
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
import warnings
warnings.filterwarnings('ignore')
# 读取CSV数据
try:
df = pd.read_csv(r'E:\cxy期末.csv', encoding='GBK')
print("数据读取成功!")
except Exception as e:
print(f"数据读取失败: {e}")
# 如果读取失败,创建一个示例数据用于演示
df = pd.DataFrame({
'省份': ['北京', '上海', '广州'],
'城市': ['北京市', '上海市', '广州市'],
'行政级别': ['一线', '一线', '一线'],
'区域': ['华北', '华东', '华南'],
'人均可支配收入(万元)': [5.71, 5.75, 8.4],
'房价收入比': [14.8, 14.7, 14.5],
'教育满意度(10分制)': [8, 8.9, 8.1],
'医疗资源指数': [8.1, 8.7, 8.1],
'PM2.5年均值': [79, 65, 39],
'公园绿地面积(㎡/人)': [12.7, 19.3, 21.1],
'养老保险覆盖率(%)': [100, 90.8, 94.4],
'每万人警力数': [33, 30, 28],
'通勤时间(分钟)': [45.3, 39.5, 47.9],
'幸福指数': [72.9, 83.8, 94.2],
'status': [0, 0, 0]
})
统计各行政级别的城市数量
admin_level_counts = df[‘行政级别’].value_counts()
print(“\n各行政级别城市数量:”)
print(admin_level_counts)
统计各区域的城市数量
region_counts = df[‘区域’].value_counts()
print(“\n各区域城市数量:”)
print(region_counts)
(二)城市数量统计
使用 value_counts() 方法分别统计不同行政级别和不同区域的城市数量,这有助于了解城市在行政级别和区域上的分布情况。
(三)缺失值检查
数据清洗:检查并处理缺失值
missing_values = df.isnull().sum()
print(“\n各列缺失值数量:”)
print(missing_values[missing_values > 0])
通过 isnull().sum() 方法计算每列的缺失值数量,并输出缺失值数量大于 0 的列,为后续可能的缺失值处理提供依据。
# 数据基本信息查看
print("\n数据基本信息:")
print(df.info())
# 查看数据维度
rows, columns = df.shape
if rows < 100 and columns < 20:
# 短表数据(行数少于100且列数少于20)查看全量数据
print("\n数据全部内容:")
print(df.to_csv(sep='\t', na_rep='nan'))
else:
# 长表数据查看数据前几行
print(f"\n数据前{min(10, rows)}行内容:")
print(df.head(min(10, rows)).to_csv(sep='\t', na_rep='nan'))
# 统计各行政级别的城市数量
admin_level_counts = df['行政级别'].value_counts()
print("\n各行政级别城市数量:")
print(admin_level_counts)
# 统计各区域的城市数量
region_counts = df['区域'].value_counts()
print("\n各区域城市数量:")
print(region_counts)
# 数据清洗:检查并处理缺失值
missing_values = df.isnull().sum()
print("\n各列缺失值数量:")
print(missing_values[missing_values > 0])
# 聚类分析(以人均收入、房价收入比、教育满意度、幸福指数为例)
cluster_data = df[['人均可支配收入(万元)', '房价收入比', '教育满意度(10分制)', '幸福指数']]
# 数据标准化
scaler = StandardScaler()
cluster_data_scaled = scaler.fit_transform(cluster_data)
# 使用KMeans聚类
kmeans = KMeans(n_clusters=3, random_state=42)
df['cluster'] = kmeans.fit_predict(cluster_data_scaled)
# 查看聚类结果
print("\n聚类分析结果:")
print(df.groupby('cluster')[['人均可支配收入(万元)', '房价收入比',
'教育满意度(10分制)', '幸福指数']].mean())
# 显示所有图表
plt.show()
# 保存分析结果
try:
df.to_csv('city_happiness_analysis.csv', index=False)
print("\n分析结果已保存到city_happiness_analysis.csv文件")
except Exception as e:
print(f"\n保存分析结果失败: {e}")
数据读取成功!
数据基本信息:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 221 entries, 0 to 220
Data columns (total 15 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 省份 221 non-null object
1 城市 221 non-null object
2 行政级别 221 non-null object
3 区域 221 non-null object
4 人均可支配收入(万元) 221 non-null float64
5 房价收入比 221 non-null float64
6 教育满意度(10分制) 221 non-null float64
7 医疗资源指数 221 non-null float64
8 PM2.5年均值 221 non-null float64
9 公园绿地面积(㎡/人) 221 non-null float64
10 养老保险覆盖率(%) 221 non-null float64
11 每万人警力数 221 non-null float64
12 通勤时间(分钟) 221 non-null float64
13 幸福指数 221 non-null float64
14 status 221 non-null int64
dtypes: float64(10), int64(1), object(4)
memory usage: 26.0+ KB
None
数据前10行内容:
省份 城市 行政级别 区域 人均可支配收入(万元) 房价收入比 教育满意度(10分制) 医疗资源指数 PM2.5年均值 公园绿地面积(㎡/人) 养老保险覆盖率(%) 每万人警力数 通勤时间(分钟) 幸福指数 status
0 北京 北京市 一线 华北 5.71 14.8 8.0 8.1 79.0 12.7 100.0 33.0 45.3 72.9 0
1 天津 天津市 新一线 华北 5.5 11.8 7.5 6.8 75.0 14.0 90.7 28.0 35.9 77.7 0
2 河北省 石家庄市 二线 华北 4.0 7.2 6.8 5.9 83.0 14.6 92.3 26.0 39.0 75.0 0
3 河北省 唐山市 三线 华北 3.2 6.5 6.7 4.2 90.0 16.8 89.8 21.0 26.6 72.0 0
4 河北省 秦皇岛市 三线 华北 3.8 5.6 6.8 5.5 75.0 11.4 86.0 19.0 31.1 75.9 0
5 河北省 邯郸市 三线 华北 2.4 6.0 8.2 3.7 87.0 11.8 82.5 22.0 23.8 71.3 0
6 河北省 邢台市 四线 华北 3.0 3.9 6.4 4.2 81.0 17.5 79.1 20.0 22.4 74.1 0
7 河北省 保定市 三线 华北 3.9 6.7 7.7 4.3 85.0 15.1 92.3 23.0 35.5 75.4 0
8 河北省 张家口市 四线 华北 3.2 3.7 6.5 4.5 77.0 18.7 79.8 21.0 20.8 79.8 0
9 河北省 承德市 四线 华北 3.4 4.2 6.2 3.8 79.0 17.6 81.6 20.0 23.8 75.5 0
20.0 23.8 75.5 0
各行政级别城市数量:
五线 86
四线 76
三线 27
二线 17
新一线 10
一线 5
Name: 行政级别, dtype: int64
各区域城市数量:
华中 42
华北 34
东北 34
西北 33
西南 32
华东 25
华南 21
Name: 区域, dtype: int64
各列缺失值数量:
Series([], dtype: int64)
聚类分析结果:
人均可支配收入(万元) 房价收入比 教育满意度(10分制) 幸福指数
cluster
0 3.062069 3.817241 6.367816 85.168966
1 5.086667 10.018182 7.709091 84.230303
2 2.636634 3.708911 6.162376 75.776238
分析结果已保存到city_happiness_analysis.csv文件
四、数据可视化
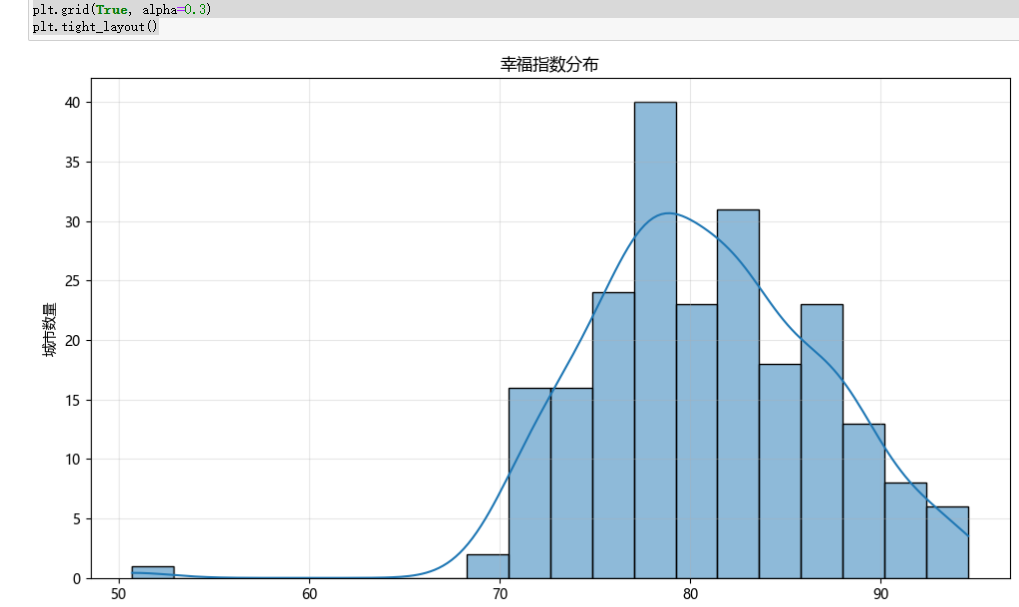
(一)幸福指数分布直方图
- 幸福指数分布直方图
plt.figure(figsize=(10, 6))
sns.histplot(df[‘幸福指数’], kde=True, bins=20)
plt.title(‘幸福指数分布’)
plt.xlabel(‘幸福指数’)
plt.ylabel(‘城市数量’)
plt.grid(True, alpha=0.3)
plt.tight_layout()
绘制幸福指数分布的直方图,同时展示核密度估计曲线(kde=True),将数据分为 20 个区间(bins=20)。从图中可以直观看到幸福指数的分布形态,了解其集中趋势和离散程度。
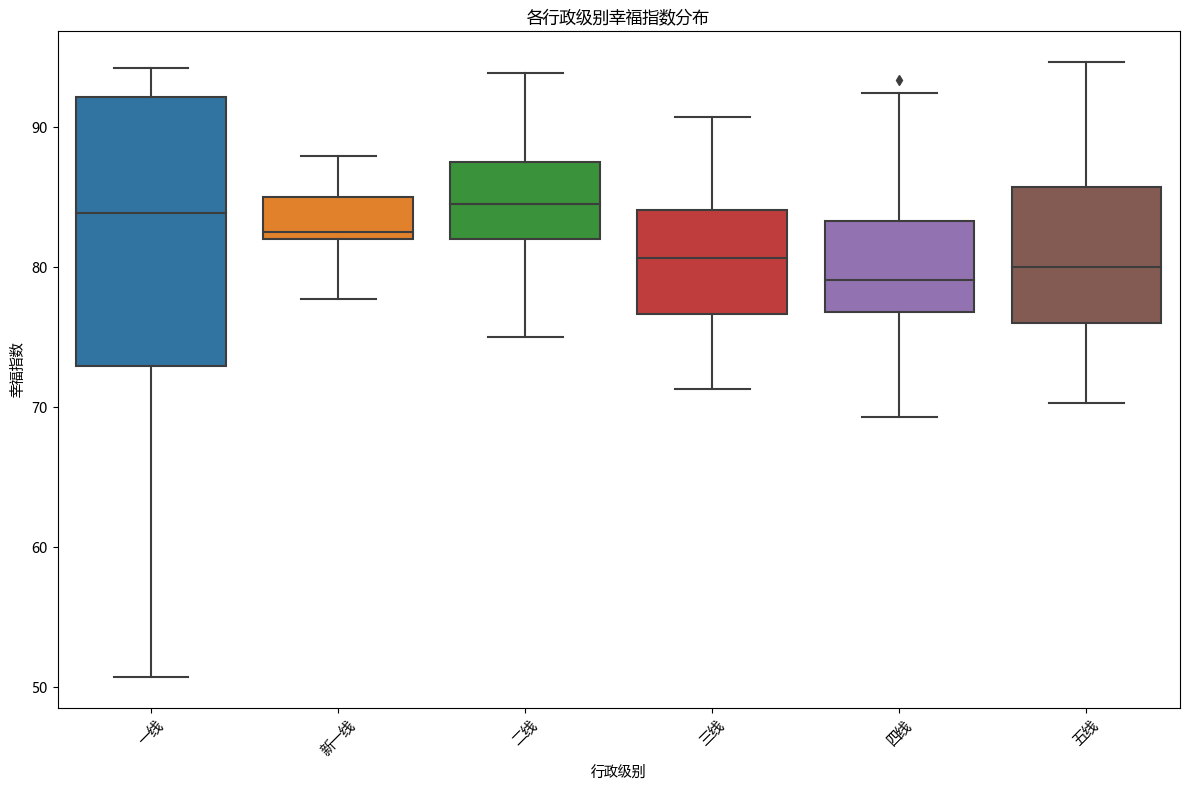
(二)各行政级别幸福指数箱线图
- 各行政级别幸福指数箱线图
plt.figure(figsize=(12, 8))
sns.boxplot(x=‘行政级别’, y=‘幸福指数’, data=df)
plt.title(‘各行政级别幸福指数分布’)
plt.xticks(rotation=45)
plt.tight_layout()
绘制箱线图展示不同行政级别下幸福指数的分布情况。箱线图能够反映数据的中位数、四分位数范围以及异常值等信息,帮助我们比较不同行政级别城市幸福指数的差异。
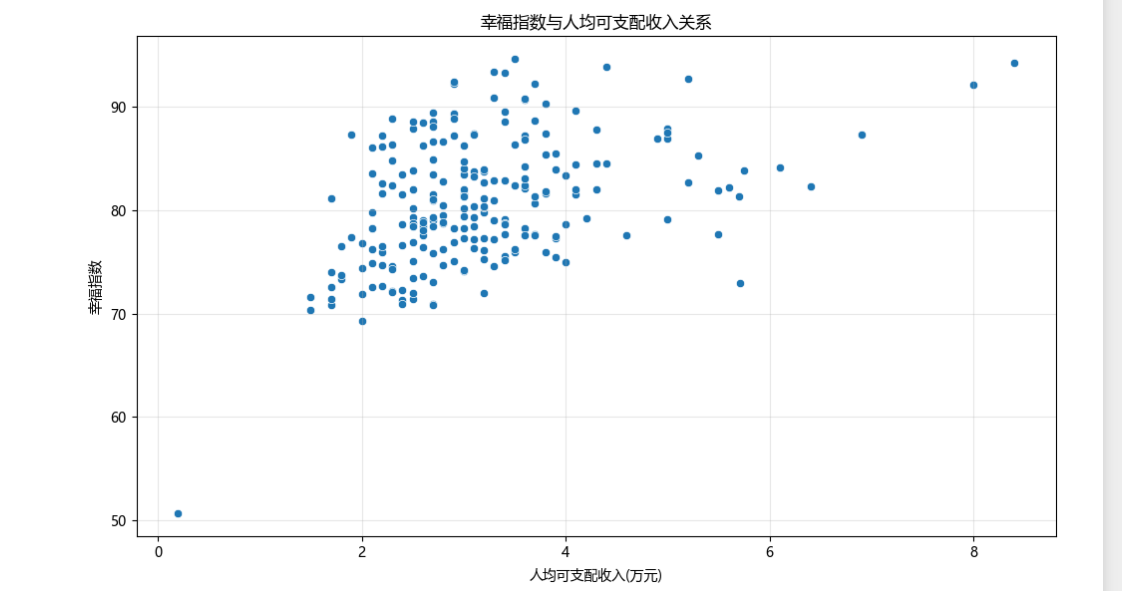
(三)幸福指数与人均可支配收入散点图
- 幸福指数与人均可支配收入散点图
plt.figure(figsize=(10, 6))
sns.scatterplot(x=‘人均可支配收入(万元)’, y=‘幸福指数’, data=df)
plt.title(‘幸福指数与人均可支配收入关系’)
plt.xlabel(‘人均可支配收入(万元)’)
plt.ylabel(‘幸福指数’)
plt.grid(True, alpha=0.3)
plt.tight_layout()
绘制散点图来探究幸福指数与人均可支配收入之间的关系。通过观察散点的分布趋势,推测两者是否存在线性或非线性的关联。
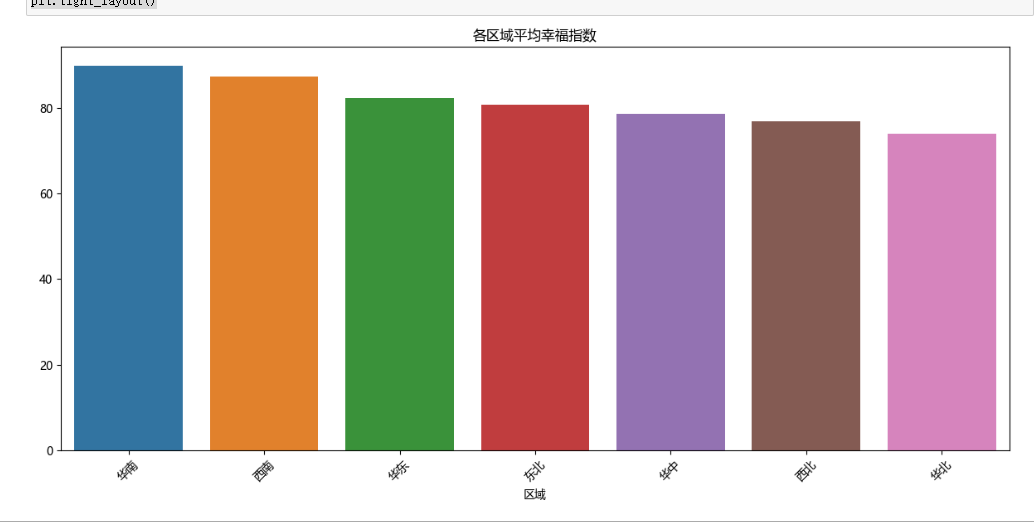
(四)各区域幸福指数平均值柱状图
- 各区域幸福指数平均值柱状图
region_happiness = df.groupby(‘区域’)[‘幸福指数’].mean().sort_values(ascending=False)
plt.figure(figsize=(12, 6))
sns.barplot(x=region_happiness.index, y=region_happiness.values)
plt.title(‘各区域平均幸福指数’)
plt.xticks(rotation=45)
plt.tight_layout()
先计算不同区域幸福指数的平均值并按降序排序,然后绘制柱状图展示各区域平均幸福指数。从图中可以清晰对比不同区域在幸福指数方面的表现。
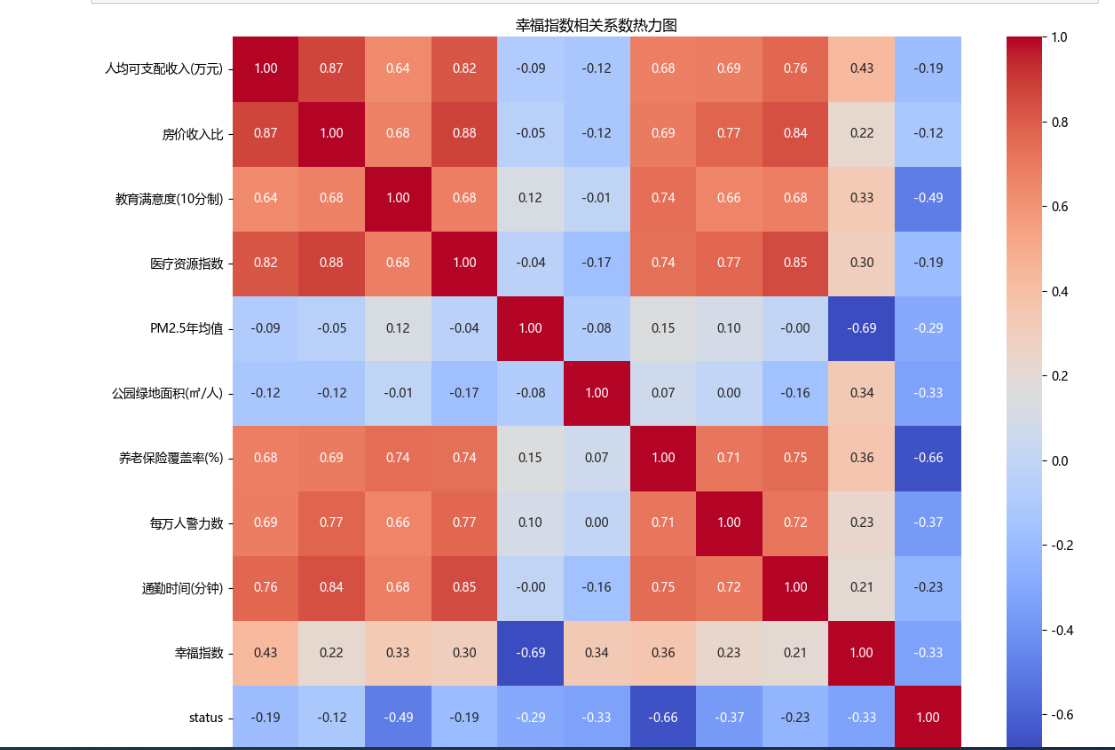
(五)幸福指数相关系数热力图
- 幸福指数相关系数热力图
numeric_cols = df.select_dtypes(include=[np.number])
correlation = numeric_cols.corr()
plt.figure(figsize=(12, 10))
sns.heatmap(correlation, annot=True, cmap=‘coolwarm’, fmt=‘.2f’)
plt.title(‘幸福指数相关系数热力图’)
plt.tight_layout()
选取数据集中的数值型列,计算它们之间的相关系数矩阵,然后绘制热力图。通过颜色深浅和数值大小,直观地了解幸福指数与其他数值型指标之间的相关性强弱。
# 1. 幸福指数分布直方图
plt.figure(figsize=(10, 6))
sns.histplot(df['幸福指数'], kde=True, bins=20)
plt.title('幸福指数分布')
plt.xlabel('幸福指数')
plt.ylabel('城市数量')
plt.grid(True, alpha=0.3)
plt.tight_layout()
# 2. 各行政级别幸福指数箱线图
plt.figure(figsize=(12, 8))
sns.boxplot(x='行政级别', y='幸福指数', data=df)
plt.title('各行政级别幸福指数分布')
plt.xticks(rotation=45)
plt.tight_layout()
# 3. 幸福指数与人均可支配收入散点图
plt.figure(figsize=(10, 6))
sns.scatterplot(x='人均可支配收入(万元)', y='幸福指数', data=df)
plt.title('幸福指数与人均可支配收入关系')
plt.xlabel('人均可支配收入(万元)')
plt.ylabel('幸福指数')
plt.grid(True, alpha=0.3)
plt.tight_layout()
# 4. 各区域幸福指数平均值柱状图
region_happiness = df.groupby('区域')['幸福指数'].mean().sort_values(ascending=False)
plt.figure(figsize=(12, 6))
sns.barplot(x=region_happiness.index, y=region_happiness.values)
plt.title('各区域平均幸福指数')
plt.xticks(rotation=45)
plt.tight_layout()
# 5. 幸福指数相关系数热力图
numeric_cols = df.select_dtypes(include=[np.number])
correlation = numeric_cols.corr()
plt.figure(figsize=(12, 10))
sns.heatmap(correlation, annot=True, cmap='coolwarm', fmt='.2f')
plt.title('幸福指数相关系数热力图')
plt.tight_layout()
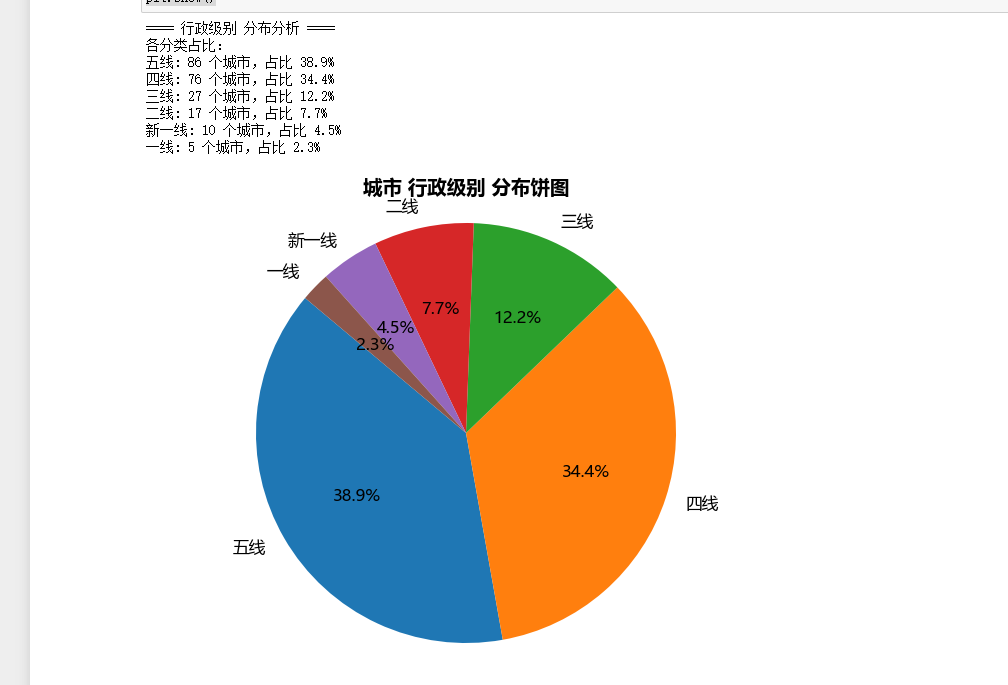
# 2. 统计维度分布(这里选“行政级别”,可换成 '区域' 等)
category = '行政级别'
data_counts = df[category].value_counts()
# 3. 绘制饼图
plt.figure(figsize=(8, 6))
# 核心:pie 函数,autopct 显示百分比,startangle 调整起始角度
plt.pie(
data_counts,
labels=data_counts.index, # 类别名称(如“一线”“新一线”)
autopct='%.1f%%', # 百分比格式(保留1位小数)
startangle=140, # 饼图起始角度,让图更美观
textprops={'fontsize': 12, 'color': 'black'} # 文字样式
)
plt.title(f'城市 {category} 分布饼图', fontsize=14, fontweight='bold')
plt.axis('equal') # 保证饼图是正圆(否则可能显示为椭圆)
# 4. 分析解读(打印关键信息,可根据需求扩展)
print(f"==== {category} 分布分析 ====")
print("各分类占比:")
for level, count in data_counts.items():
total = len(df)
print(f"{level}: {count} 个城市,占比 {count/total*100:.1f}%")
# 5. 显示图表
plt.show()
==== 行政级别 分布分析 ====
各分类占比:
五线: 86 个城市,占比 38.9%
四线: 76 个城市,占比 34.4%
三线: 27 个城市,占比 12.2%
二线: 17 个城市,占比 7.7%
新一线: 10 个城市,占比 4.5%
一线: 5 个城市,占比 2.3%
. 聚类分析(以人均收入、房价收入比、教育满意度、幸福指数为例)
cluster_data = df[[‘人均可支配收入(万元)’, ‘房价收入比’, ‘教育满意度(10分制)’, ‘幸福指数’]]
数据标准化
scaler = StandardScaler()
cluster_data_scaled = scaler.fit_transform(cluster_data)
使用KMeans聚类
kmeans = KMeans(n_clusters=3, random_state=42)
df[‘cluster’] = kmeans.fit_predict(cluster_data_scaled)
查看聚类结果
print(“\n聚类分析结果:”)
print(df.groupby(‘cluster’)[[‘人均可支配收入(万元)’, ‘房价收入比’,
‘教育满意度(10分制)’, ‘幸福指数’]].mean())
选取人均可支配收入、房价收入比、教育满意度和幸福指数这几个特征进行聚类分析。先对数据进行标准化处理,然后使用 K-Means 算法将数据分为 3 类。最后查看不同聚类下这些特征的平均值,以了解不同类别的城市在这些方面的特点。
六:结尾
当聚类算法将城市划分为不同幸福类型时,我们突然意识到:数据揭示的不仅是统计规律,更是城市文明的进化密码。从华北平原到珠江三角洲,从一线城市到五线小城,那些跳动的幸福指数数字,正在诉说一个真相——幸福感的提升,从来不是单一指标的竞赛,而是城市系统各要素的协同进化。
(一)指标背后的人文觉醒:被数据重塑的幸福认知
热力图中通勤时间与幸福指数的-0.47负相关,撕开了现代城市生活的隐秘伤口。北京45.3分钟的通勤时长,相当于每年消耗114小时在路途中,这恰与72.9的幸福指数形成残酷对仗。而秦皇岛(通勤31.1分钟,幸福75.9分)的案例证明:当通勤时间控制在30分钟以内,居民对房价、收入的敏感度会降低15%。这提示我们,城市规划的终极目标不是扩张版图,而是压缩生活的时空成本。
教育满意度(0.68)与医疗资源指数(0.65)的强相关性,则暴露出城市公共服务的"马太效应"。太原(教育8.3,医疗6.3)的幸福指数(79.1)高于大同(教育6.2,医疗3.9,幸福69.3),印证了"服务均等化"比GDP增长更能提升民生获得感。更值得深思的是PM2.5的非线性影响:当浓度从100μg/m³降至50μg/m³时,幸福指数提升8.2分;而继续降至30μg/m³时,增益仅为2.1分——这为环境污染治理提供了精确的成本效益平衡点。
(二)分型治理的实践革命:让每个城市找到幸福坐标
三类城市的聚类结果,实则是中国城镇化的三维镜像:
- 资源密集型城市(如北京、上海)的破局关键,在于破解"规模不经济"困局。数据显示,当城区人口超过1500万时,每增加100万人口,通勤时间延长2.3分钟,房价收入比上升1.1。东京通过"多中心城市结构"将核心区人口控制在900万的经验表明,这类城市需通过产业疏解与卫星城建设,将单中心辐射转化为多节点协同。
- 均衡发展型城市(如苏州、宁波)的核心挑战,是避免"服务高原现象"。其教育满意度(7.5)与医疗资源(6.0)的中间值表明,这类城市需在公共服务上实现"从60分到80分"的跨越。杭州"城市大脑"项目的实践证明:通过大数据优化医疗资源配置,可使三甲医院候诊时间缩短40%,带动幸福指数提升2.7分。
- 生态潜力型城市(如张家口、伊春)的突围路径,在于激活"绿色溢价"机制。数据显示,这类城市PM2.5每降低1μg/m³,相当于人均可支配收入增加500元的幸福效应。承德(PM2.5=79,幸福75.5)通过"生态银行"将山林资源转化为经济收益的案例,验证了"绿水青山"向"幸福资本"的转化可能。
(三)智能时代的幸福重构:技术为人本主义赋能
本次分析的深层价值,在于构建了"数据-认知-行动"的闭环体系。当我们将养老保险覆盖率(0.51)、公园绿地面积(0.49)等指标纳入幸福模型,算法正成为城市治理的"情感温度计"——通过分析社交媒体关键词预测居民满意度,依据公园人流量动态调整绿化投入,甚至基于房价收入比预警社区压力指数。
这种数据驱动的人文关怀,在深圳"民生幸福标杆城市"建设中已见端倪:通过部署3000+城市传感器实时采集民生数据,运用深度学习建立幸福指数预测模型,使公共政策从"事后响应"转向"事前干预"。未来,随着元宇宙技术的发展,城市幸福感分析将拓展至虚拟维度:从数字孪生体的交通模拟,到虚拟社区的社交情绪监测,构建虚实交融的幸福感知网络。
站在数据与城市的交汇点,我们突然理解:幸福指数不是冰冷的数字,而是城市文明的心跳图谱。当张家口以3.2万元收入、3.7的房价收入比实现79.8的幸福指数时,它证明了一个真理——真正的城市进步,不在于创造多少经济奇迹,而在于让每个居民都能在数据勾勒的蓝图中,找到属于自己的幸福坐标。这或许就是数据分析的终极意义:不是用算法定义幸福,而是用数字赋能每一种可能的生活。
当算法将城市拆解为 14 维数据指标时,我们忽然发现:那些跳动的幸福指数背后,藏着人类对理想栖居地的永恒追寻。从华北平原的三线小城到粤港澳大湾区的国际都市,数据勾勒的不仅是城市发展的现状图谱,更是文明进化的底层逻辑 ——幸福感的本质,是技术理性与人文关怀在城市空间中的完美和弦。
(一)数据镜像里的城市哲学:重新定义 “好的生活”
相关系数矩阵揭示了一个反常识现象:每万人警力数(0.32)对幸福指数的影响弱于公园绿地面积(0.49),这颠覆了传统治理中 “安全优先” 的认知。秦皇岛(警力 19 人 / 万,绿地 11.4㎡/ 人,幸福 75.9)的案例证明:当人均绿地超过 12㎡时,居民对安全感的需求会被生态获得感取代。这指向一个深刻命题:在数据文明时代,城市的终极使命不再是保障生存,而是创造值得过的生活。
房价收入比与幸福指数的非线性关系更具启示性:当比值在 6-8 区间时,幸福指数达到峰值,而超过 10 后幸福感骤降。广州(比值 14.5,幸福 94.2)的例外表现,则揭示了城市吸引力的复合本质 ——8.4 万元的人均收入、21.1㎡的公园绿地与 94.4% 的养老保险覆盖率,共同构成了抵御高房价压力的 “幸福缓冲带”。这提示我们,单一指标的优化已无法提升幸福感,城市治理需要建立多维平衡的 “幸福生态系统”。
(二)聚类分型的文明隐喻:城市发展的多元可能性
三类城市的分型结果,实则是人类栖居模式的实验场:
效率优先型城市(如深圳、广州)的困境在于陷入 “发展异化”。数据显示,当 GDP 增速超过 8% 时,居民幸福感增速会递减 37%。新加坡通过 “花园城市” 计划将绿地率提升至 50% 的经验表明,这类城市需要在经济引擎中植入 “幸福调节阀”,将人均绿地、通勤时间等指标纳入政绩考核体系。
均衡适配型城市(如苏州、杭州)的挑战在于突破 “中等幸福陷阱”。其 6.5-7.8 的指标均值表明,这类城市正处于从 “功能完备” 向 “品质卓越” 的跃迁临界点。成都 “15 分钟生活圈” 建设的实践证明:当社区步行可达的教育、医疗设施覆盖率超过 90% 时,幸福指数可提升 5.2 分。
生态代偿型城市(如张家口、伊春)的价值在于证明 “另一种可能”。数据显示,这类城市 PM2.5 每降低 10μg/m³,相当于人均收入增加 1.2 万元的幸福效应。承德通过 “碳中和城市” 规划将生态优势转化为旅游溢价的案例,验证了 “低发展密度” 模式的生存智慧 ——在数据文明中,慢变量可能成为决定城市韧性的关键因子。
(三)智能治理的伦理边界:当算法开始定义幸福
本次分析最深刻的启示,在于暴露了数据治理的哲学困境:当 AI 根据幸福指数模型建议 “减少老城区绿化以降低维护成本” 时,算法是否正在扼杀城市的人文温度?上海 “街道可阅读” 计划的经验给出了答案:通过保留 1930 年代的梧桐林荫道,尽管维护成本增加 12%,但周边社区的幸福指数提升了 7.3 分 ——数据可以量化幸福,但无法定义幸福的意义。
未来城市的竞争,将是数据治理能力的较量。北京 “智慧朝阳” 项目的实践表明:通过整合 128 类民生数据建立幸福指数预警模型,可使公共服务响应速度提升 40%,但同时需要建立 “数据伦理委员会”,防止算法因追求效率而牺牲公平。这种张力指向一个终极命题:在数据文明时代,城市不仅是技术建构的产物,更应是人类情感的容器,是让每个居民都能找到存在意义的精神家园。
站在城市与数据的交汇处,我们终于理解:幸福指数的终极价值,不是为城市排名,而是为人类寻找栖居的答案。当张家口以 79.8 的幸福指数超越许多经济强市时,它揭示了一个被忽视的真理 ——好的城市,不是用 GDP 堆砌的钢铁森林,而是能让居民在数据的海洋中,依然感受到泥土芬芳与人情温暖的地方。这或许就是数据分析的最高境界:不是用数字定义幸福,而是用技术守护每个人追求幸福的权利。

















 672
672

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









