



 本文介绍了在大数据时代如何通过Python入门爬虫,包括Python环境搭建、requests和BeautifulSoup库的使用,以及如何解析HTML结构抓取信息。随后提到在实际项目中可能遇到的反爬虫问题,并推荐了BrightData平台作为强大的数据处理和爬虫工具。
本文介绍了在大数据时代如何通过Python入门爬虫,包括Python环境搭建、requests和BeautifulSoup库的使用,以及如何解析HTML结构抓取信息。随后提到在实际项目中可能遇到的反爬虫问题,并推荐了BrightData平台作为强大的数据处理和爬虫工具。
在大数据时代,数据的处理已成为很关键的问题。如何在茫茫数字的海洋中找到自己所需的数据呢?不妨试试爬虫吧!
本文,我们从最基本的 python 爬虫入门。谈谈小白如何入门!
前期条件
既然我们需要 python 来爬虫,这需要在我们的本地搭建 python 环境。python 环境搭建很简单。如下:
😘windows11
在win11中,我们只需在cmd命令中输入python在应用商店中,直接点击获取即可。
 🐯Windows 其他系统
🐯Windows 其他系统
对于其他系统,我们只需要到官网下载安装包,进行安装即可。



 安装完成,在 cmd 命令中输入
安装完成,在 cmd 命令中输入python能显示相应的 python 版本就行了。
🐻❄️Linux
在 Linux 中,我们只需执行下面命令
# 更新源
apt-get update
# 安装
apt-get install python3.8
# 查看
python -V
常用依赖模块
python 是不能直接爬虫的。我们需要借助各种依赖环境。现对常用的依赖环境简单的说明:
requests
requests 是一个常用的 HTTP 请求库,可以方便地向网站发送 HTTP 请求,并获取响应结果。它的安装也很简单,执行下面命令进行安装
pip install requests
使用示例:
# 导入 requests 包
import requests
# 发送请求
x = requests.get('https://blog.bbskali.cn')
# 返回网页内容
print(x.text)
beautifulsoup4
和前者一样,利用beautifulsoup4库也能很好的解析 html 中的内容。
# 安装
pip install beautifulsoup4
小试牛刀
这里,我们以Quotes to Scrape这个简单的网站为例。
 我们可以看到,当前页面主要有
我们可以看到,当前页面主要有标题 作者 标签等信息。现在我们对当前的页面进行分析。
 在当前页面中,我们可以看到 css 的结构如下;
在当前页面中,我们可以看到 css 的结构如下;
<div class="quote" itemscope="" itemtype="http://schema.org/CreativeWork">
<span class="text" itemprop="text">“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”</span>
<span>by <small class="author" itemprop="author">Albert Einstein</small>
<a href="/author/Albert-Einstein">(about)</a>
</span>
<div class="tags">
Tags:
<meta class="keywords" itemprop="keywords" content="change,deep-thoughts,thinking,world">
<a class="tag" href="/tag/change/page/1/">change</a>
</div>
</div>
我们只需关键字段的 css 就行了。您可以从图上看到, quote
HTML HTML 元素由 quote/引用类标识。这包含:
-
<span>HTML 元素中的引用文本 -
<small>HTML 元素中的引用作者 -
<div>元素中的标签列表,每个标签都包含<a>HTML 元素中
现在我们来学习如何使用 Python 的 Beautiful Soup 实现这一目标。
soup = BeautifulSoup(page.text, 'html.parser')
接下来,利用find_all() 方法将返回由 quote 类标识的所有<div> HTML 元素的列表。
quote_elements = soup.find_all('div', class_='quote')
最后完整代码如下:
#导入第三方库
import requests
from bs4 import BeautifulSoup
import csv
def scrape_page(soup, quotes):
# 查找当前页面中所有class="quote"的div
quote_elements = soup.find_all('div', class_='quote')
# 通过for循环 遍历quote_elements下的标题 作者 标签等信息。
for quote_element in quote_elements:
# 遍历标题
text = quote_element.find('span', class_='text').text
# 遍历作者
author = quote_element.find('small', class_='author').text
# 遍历标签
tag_elements = quote_element.find('div', class_='tags').find_all('a', class_='tag')
#由于标签不止一个,所以将其放到数组中。
tags = []
for tag_element in tag_elements:
tags.append(tag_element.text)
quotes.append(
{
'text': text,
'author': author,
'tags': ', '.join(tags)
}
)
# 设置目标域名
base_url = 'https://quotes.toscrape.com'
# 设置浏览器信息,让系统认为我们的请求是浏览器的正常请求。
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}
#使用requests来下载网页,并将数据赋值给page
page = requests.get(base_url, headers=headers)
#将上级page的数据递交给 BeautifulSoup函数。
soup = BeautifulSoup(page.text, 'html.parser')
# 初始化一个包含了所有抓取的数据列表的变量
quotes = []
scrape_page(soup, quotes)
# 抓取下一页内容
next_li_element = soup.find('li', class_='next')
while next_li_element is not None:
next_page_relative_url = next_li_element.find('a', href=True)['href']
page = requests.get(base_url + next_page_relative_url, headers=headers)
soup = BeautifulSoup(page.text, 'html.parser')
scrape_page(soup, quotes)
next_li_element = soup.find('li', class_='next')
#将结果保存为csv文件
csv_file = open('quotes.csv', 'w', encoding='utf-8', newline='')
writer = csv.writer(csv_file)
writer.writerow(['Text', 'Author', 'Tags'])
for quote in quotes:
writer.writerow(quote.values())
csv_file.close()
效果展示
将上面的文件保存为py文件。然后执行
python xx.py


能力提升
在上述中,我们讲解了利用 python 实现简单的爬虫。但是在实际中很多站点都会有反爬虫机制。主要体现在以下几个方面。
-
限制 IP 的访问次数
-
复杂页面爬虫,对代码要求比较高。
-
对大型爬虫项目,数据的后期处理比较麻烦
在此,表哥为大家推荐一款数据处理和爬虫很牛叉的平台Bright Data 我们到官网首先注册,
官网地址:https://get.brightdata.com/f4dkh 注册后效果如下:
 登录后,可以看到主要有两部分代理爬虫基础设施 和 数据集 和 Web Scraper IDE
登录后,可以看到主要有两部分代理爬虫基础设施 和 数据集 和 Web Scraper IDE
代理&爬虫基础设施
 通过真实的代理 IP 来爬虫,从而避免 IP 地址的限制。
通过真实的代理 IP 来爬虫,从而避免 IP 地址的限制。
 数据集 和 Web Scraper IDE
数据集 和 Web Scraper IDE
这里官方提供了已经爬好的一些知名站点的数据,我们可以直接使用。
 Web Scraper IDE
Web Scraper IDE
在这里,官方还提供了 web 端的 ide 工具,并提供了相关的示例代码,可以直接使用!
 定制数据
定制数据
当然,如果上面的这些不符合你的要求,可以定制数据。这里,我们已博客园的数据为例,如我想爬取博客园的文章标题、作者、发布时间、点赞数等信息。


然后提交后,等待抓取完成。

编辑每个字段 最后保存
最后保存
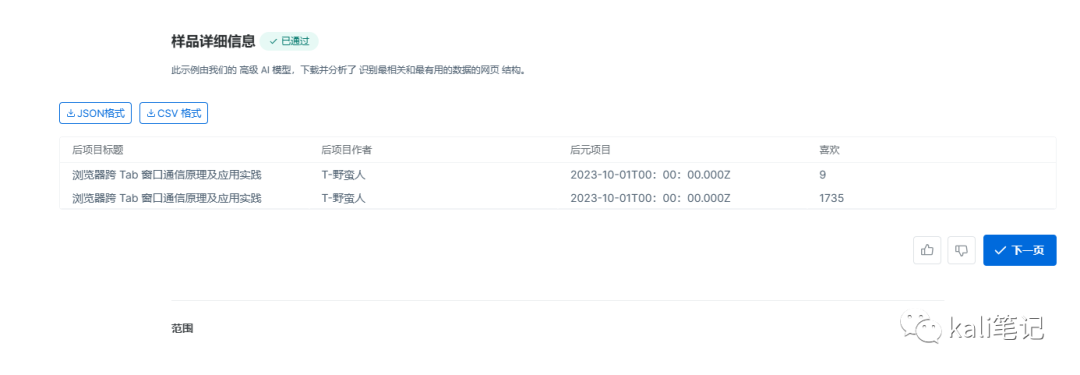 设置爬取的条数,这里我设置爬了
设置爬取的条数,这里我设置爬了5000条
 提交后,等待爬取结果就行了。简单不~
提交后,等待爬取结果就行了。简单不~
注册地址:https://get.brightdata.com/wxdtkgpzhtj8
感兴趣的小伙伴,赠送全套Python学习资料,包含面试题、简历资料等具体看下方。

一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、Python必备开发工具
工具都帮大家整理好了,安装就可直接上手!
三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、Python视频合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

六、面试宝典


简历模板
 若有侵权,请联系删除
若有侵权,请联系删除

















 2188
2188

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









