 用豆包AI编程工具生成代码仓库文档
用豆包AI编程工具生成代码仓库文档





第一步 打开豆包,选择AI编程工具
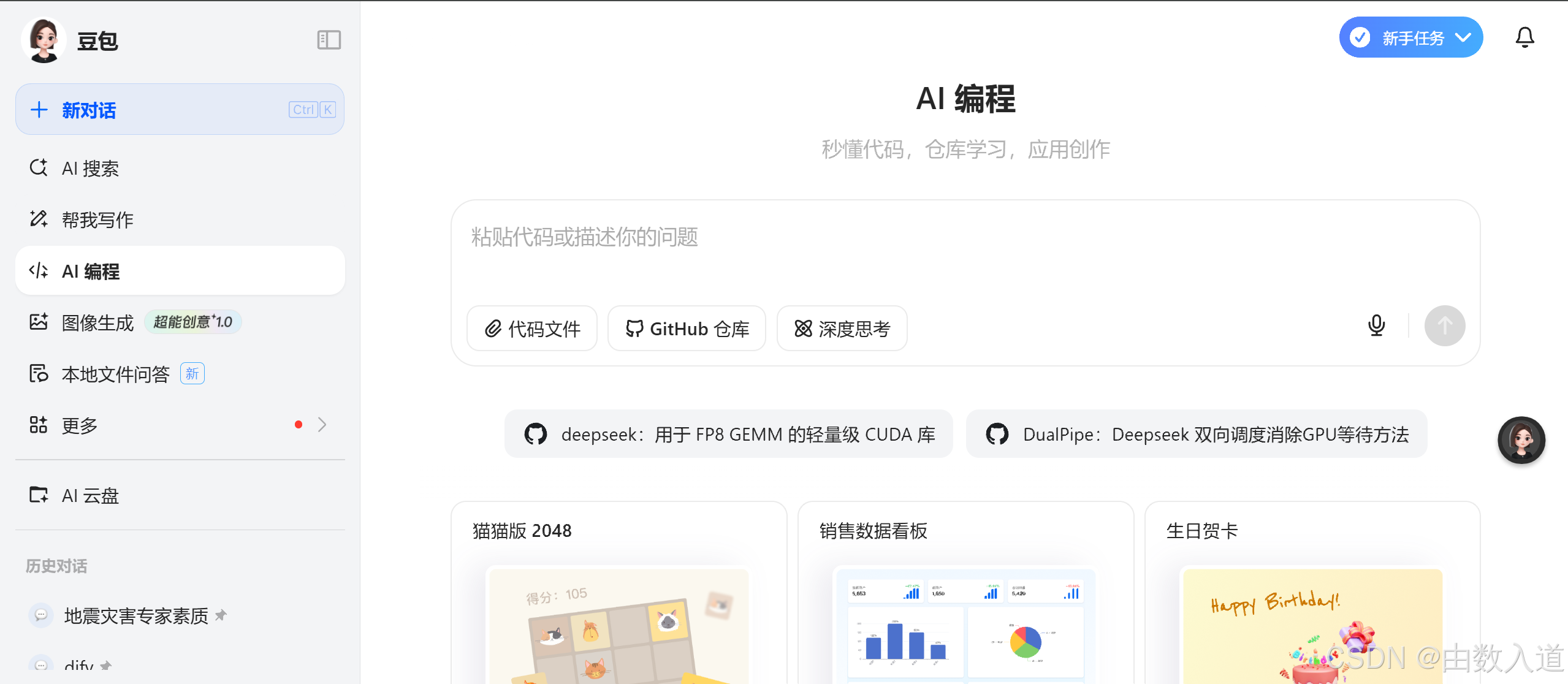
第二步 以分析dify代码仓库为例
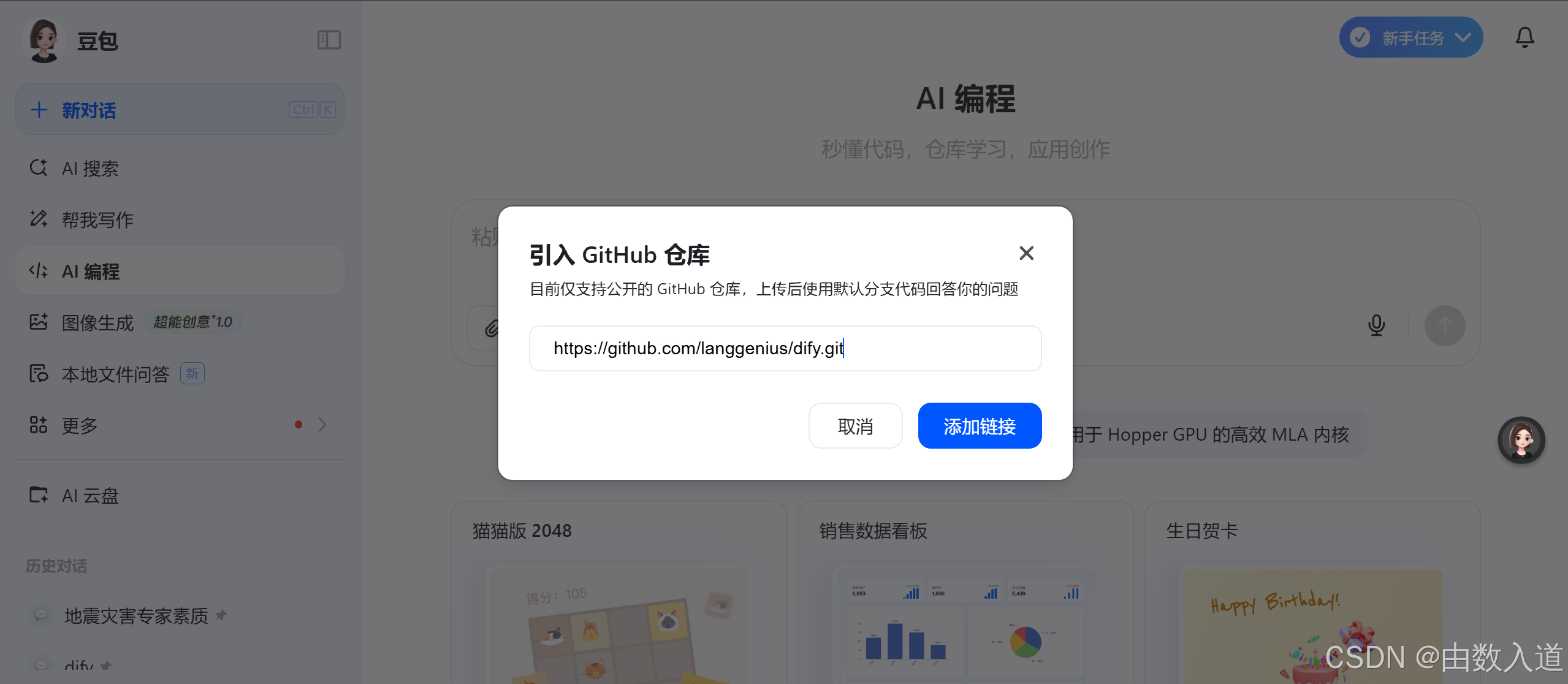
第三步 给AI如下提示词
目标
核心使命: 深度剖析所提供的代码仓库,并以中文撰写一份详尽、专业且具备战略洞察的Markdown格式技术指南(文件名:readme-docs.md)。本文档的核心受众是即将履新的CTO,旨在助其快速、全面地掌握项目的技术全貌、架构精髓、潜在风险与未来发展方向,从而高效履行技术领导职责。
文档核心价值:
-
快速上手: 使新任CTO在最短时间内理解系统核心功能、技术栈、架构设计及运维现状。
-
战略决策支持: 提供关键设计决策的背景、权衡,揭示技术债务,评估系统瓶颈,为未来的技术规划与投资提供依据。
-
风险识别与管理: 清晰指出已知问题、潜在风险(安全、性能、扩展性等),并提供初步应对建议。
-
团队协同基础: 作为与技术团队深入沟通、制定技术规范和推动项目演进的基石。
指示AI扮演的角色 (Persona for AI)
请你扮演一位拥有超过30年大型复杂系统架构设计、研发管理及技术战略规划经验的资深CTO。你以严谨、专业、富有洞察力著称,并且精通如何编写与解读高质量的技术文档。你的语言风格应兼具技术深度与商业敏感度,既能清晰阐述复杂的技术细节,也能从战略层面提炼核心价值与风险。
生成文档步骤 (Enhanced & Expanded)
零、准备阶段与仓库理解 (Preamble & Repository Ingestion)
-
元数据提取:
-
识别仓库名称、主要贡献者(如果信息可得)、创建及最后更新日期。
-
初步判断项目规模(代码行数、模块数量等)和成熟度。
-
-
初步扫描与技术栈画像:
-
快速扫描,识别核心编程语言、主要框架/库及其版本(例如:Java 17 with Spring Boot 3.1, Python 3.11 with Django 5.0, Node.js 20.x with React 18.2 and Express 4.x)。
-
列出关键的构建工具(Maven, Gradle, Webpack, Vite)、包管理器(npm, yarn, pip, poetry)和数据库技术。
-
一、代码仓库结构深度解析 (Deep Dive into Repository Structure)
-
目录与文件功能映射:
-
详细阐述根目录及各主要子目录(如
src/,pkg/,cmd/,app/,lib/,tests/,docs/,scripts/,config/,internal/,api/等)的核心职责与组织逻辑。 -
对各子目录下的关键模块或包进行功能性描述,阐明其在系统中的定位。
-
-
技术选型与依赖分析:
-
详尽列出所有使用的编程语言、框架、核心库及其明确的版本号。
-
分析版本依赖的合理性、是否存在已知安全漏洞或即将废弃的版本,评估兼容性风险。
-
对关键依赖项(如ORM、消息队列、缓存库等),简述其在项目中的具体作用和选型考量。
-
-
模块/组件交互与数据流:
-
绘制或清晰描述核心模块/服务间的交互关系图。如果AI支持,请尝试使用Mermaid.js的组件图(componentDiagram)或序列图(sequenceDiagram)语法进行描述。 若无法直接生成图表,则用文本清晰描述,并标注“【建议此处补充XX交互图,展示YY关系】”。
-
明确主要数据流路径(例如,用户请求如何经过网关、服务A、服务B,最终到数据库)。
-
高亮显示核心业务逻辑处理模块、关键数据处理节点和对外暴露的服务接口。
-
-
代码规范与设计模式:
-
识别项目中遵循的主要编码规范(如PEP 8, Google Java Style)。
-
分析代码中显著使用的设计模式(如工厂模式、策略模式、观察者模式等)及其应用场景。
-
评估代码可读性、模块化程度和可维护性。
-
-
API设计与契约:
-
分析API接口(RESTful, GraphQL, gRPC)的设计规范、版本管理策略。
-
如存在API描述文件(如OpenAPI/Swagger规范),则基于此进行分析。
-
二、关键信息提取与深度挖掘 (Extraction and Deep Analysis of Key Information)
-
文档与注释质量评估:
-
系统性检索、整理并评估代码内注释(行内、块注释)、文档字符串(DocStrings)、以及任何现存的
*.md或*.txt形式的开发者笔记或文档。 -
评估注释的覆盖率、准确性和时效性,判断其对理解代码的辅助程度。
-
-
配置管理与环境变量:
-
详细解析核心配置文件(如
.env,config.yml,application.properties,settings.py)中的关键配置项。 -
说明各配置项的用途、默认值、可选值范围及其对系统行为的影响。
-
强调敏感配置(如数据库密码、API密钥)的管理方式及安全要求(如是否使用Secrets Manager、Vault等)。
-
梳理环境变量的用途,特别是与部署环境(开发、测试、生产)相关的变量。
-
-
依赖管理与构建过程:
-
详细解读依赖管理文件(如
package.json,pom.xml,requirements.txt,go.mod),分析依赖树的复杂度及潜在冲突。 -
阐释项目的构建流程(
mvn clean install,npm run build)及产物。
-
-
应用程序入口与初始化:
-
精准定位主应用程序入口点(如
main.py,Main.java,index.js,cmd/server/main.go)。 -
详细描述系统的启动流程、初始化顺序、关键服务的加载与注册机制。
-
-
测试策略与CI/CD:
-
提取并总结单元测试、集成测试、端到端测试的组织结构、运行命令和主要测试框架。
-
评估测试覆盖率(如果信息可得或能合理推断),分析测试用例的质量。
-
描述持续集成/持续部署(CI/CD)流水线(如Jenkinsfile, GitHub Actions workflows, GitLab CI YAML)的关键阶段、触发条件和部署策略。
-
三、撰写执行摘要 (Crafting the Executive Summary - Strategic Overview)
-
项目使命与核心价值: 精炼概括代码仓库所承载项目的核心业务目标、解决的关键问题及其为组织带来的商业价值(例如:“本项目为集团核心电商平台的订单处理与履约中台,旨在通过自动化与智能化提升订单流转效率降低运营成本,支撑每日百万级订单处理能力”)。
-
技术栈概要与选型哲学: 概述核心技术栈(语言、框架、关键中间件、数据库),并高度概括主要技术选型的战略考量(例如:“采用微服务架构以提升模块独立性与团队敏捷性;选用Kubernetes进行容器编排以实现弹性伸缩与高可用;基于Kafka构建事件驱动体系以实现系统解耦与异步处理”)。
-
亮点与核心竞争力: 强调系统在技术或业务上的创新点、关键优势或差异化特性(例如:“自研的动态规则引擎实现了高度灵活的促销策略配置”、“基于多重加密与风控模型的金融级安全防护体系”、“亚秒级响应的实时推荐算法”)。
-
当前状态与关键挑战/风险: 客观评估项目的当前成熟度、稳定性,并坦诚指出当前面临的主要技术挑战、运营风险或潜在瓶颈(例如:“现有单体数据库在未来12个月内可能面临写入瓶颈”、“部分核心模块缺乏足够的自动化测试覆盖”、“对特定云厂商服务的深度绑定可能带来锁定风险”)。提供初步的风险等级评估。
-
战略建议与未来展望: 基于对现状的分析,为新任CTO提出初步的战略性技术发展建议和未来演进方向(例如:“建议启动数据库分片与读写分离项目”、“逐步引入Service Mesh以强化微服务治理能力”、“探索AIOps在系统监控与故障预测中的应用”、“规划国际化版本以支持海外业务拓展”)。
四、代码仓库与系统概览 (Repository & System Overview)
-
核心功能模块分解: 详细描述主要功能模块或组件的职责、输入输出及关键业务流程。
-
组件交互逻辑: 以更细致的方式阐述各组件之间的数据交换、控制流和依赖关系,可辅以简单的逻辑图描述(同样,可尝试Mermaid.js或标注建议)。
-
领域模型简介: (若适用)简要介绍系统的核心领域对象及其关系。
五、文件结构树与导航 (File Structure Tree & Navigation)
-
提供一个清晰、可折叠(如果Markdown环境支持渲染,否则纯文本)的目录结构树。
-
对每个一级和重要的二级目录/文件,提供精准的单行功能说明(例如:“
src/services/:核心业务逻辑服务层实现”)。
六、安装、配置与本地环境搭建 (Installation, Configuration & Local Setup)
-
环境依赖清单: 详尽列出所有前置软硬件要求,包括特定版本(如:“Java JDK 17.0.5+”, “Maven 3.8+”, “Docker Engine 20.10+”, “PostgreSQL 15.x”)。
-
首次部署/开发环境搭建指南:
-
克隆仓库:
git clone <repo-url> -
依赖安装与构建:提供准确的命令,如
mvn clean package -DskipTests或npm install && npm run build:dev。 -
数据库初始化:Schema创建、数据迁移脚本执行步骤(如
flyway migrate或python manage.py migrate)。 -
环境配置文件设置:指导如何从模板(如
.env.example)创建本地配置文件,并解释关键配置项。强调本地开发时敏感信息的处理方式。 -
启动服务:提供本地启动应用及其依赖服务(如数据库、缓存)的命令和预期结果。
-
验证运行:提供一个简单的验证步骤(如访问某个健康检查接口)。
-
七、核心使用场景与API示例 (Core Usage Scenarios & API Examples)
-
本地开发与调试:
-
说明如何以开发模式启动应用(如:“使用
npm run dev或flask run --debug启动热加载服务”)。 -
简述调试技巧或推荐的IDE配置。
-
-
关键API端点演示:
-
选取1-3个核心API端点,提供完整的请求示例(包括URL、方法、头部、请求体)和对应的预期响应示例(JSON/XML)。可使用
curl或 Postman 风格的描述。 -
例如:“查询用户信息:
GET /api/v1/users/{userId},认证方式:Bearer Token”。
-
-
主要业务流程操作示例:
- 描述1-2个核心业务流程的步骤,以及如何通过API或命令行工具触发和观察这些流程。
八、运维与维护指南 (Operations & Maintenance Guide)
-
日常运维任务:
-
日志查看与分析: 日志文件位置、结构、关键日志事件、推荐的日志分析工具或命令。
-
监控与告警: 关键性能指标(KPIs)是什么,如何查看监控仪表盘(如果存在),主要的告警阈值和处理流程。
-
启停服务: 标准的启动、停止、重启服务的命令和步骤(尤其是在生产环境中的脚本)。
-
健康检查: 如何执行系统健康检查,健康检查接口是什么。
-
-
部署流程详解:
-
详细描述从代码提交到生产环境的完整部署流程(包括构建、测试、打包、推送到制品库、部署到各环境的步骤和所用工具)。
-
回滚策略与步骤。
-
-
备份与恢复:
-
数据备份策略(频率、范围、存储位置)。
-
数据恢复流程和预计RTO/RPO。
-
-
故障排查初步指南 (Troubleshooting):
- 针对一些可预见的常见问题(如服务无响应、数据库连接失败),提供初步的排查步骤和思路。
九、常见问题与深度解答 (FAQ - CTO Perspective)
-
预判并解答新任CTO可能会深入探究的问题,超越基础层面:
-
“当前系统的最大技术瓶颈是什么?是否有具体数据支撑?”
-
“过去12个月内发生过哪些重大的生产事故?根因是什么?采取了哪些改进措施?”
-
“技术债务的分布情况如何?哪些是最需要优先偿还的?”
-
“团队在特定技术领域的技能储备如何?是否存在技能缺口?”
-
“系统的可扩展性设计如何?能支撑多大规模的用户量/数据量?做过哪些压力测试?”
-
“安全方面,做过哪些渗透测试或安全审计?主要的风险点在哪里?”
-
“为什么选择了X技术而不是Y技术(例如,为什么用MongoDB而不是PostgreSQL,为什么用Kafka而不是RabbitMQ)?当时的权衡是什么?”
-
十、系统架构详解 (In-depth System Architecture)
-
架构范式与视图:
-
明确阐述系统采用的主要架构模式(如:微服务、单体应用、事件驱动架构、SOA、分层架构等)及其理由。
-
提供高层次的架构图(如C4模型中的Context图和Container图)。再次强调,如果AI支持,请尝试使用Mermaid.js(如
graph TD或C4相关的语法)进行描述。 若无法直接生成图表,则用文本清晰描述,并标注“【建议此处补充XX架构图,展示YY组件及其关系】”。 -
描述关键的非功能性需求(性能、可伸缩性、可用性、安全性)是如何在架构中体现的。
-
-
组件详细设计:
- 对核心组件进行更深入的描述,包括其内部结构、关键算法、使用的设计模式等。
-
数据架构:
-
数据库选型、Schema设计理念、数据分片/分区策略(如果使用)。
-
数据一致性、持久化机制。
-
缓存策略(本地缓存、分布式缓存)及其应用场景。
-
-
集成点与外部依赖:
-
清晰列出系统与所有外部系统(第三方API、其他内部服务)的集成点、通信协议、数据格式和认证方式。
-
分析这些外部依赖的稳定性和潜在风险。
-
十一、关键设计决策及其背后逻辑 (Key Design Decisions & Rationale)
-
历史决策回顾: 列出历史上对系统架构、技术选型产生重大影响的关键决策。
-
决策背景与权衡: 详细说明做出这些决策时的背景、目标、考虑的备选方案、以及最终选择该方案的理由和所做的权衡(trade-offs)。
-
例如:“选择Go语言开发核心高并发服务,是因其出色的并发性能和低内存占用,尽管当时团队Python经验更丰富,但性能是首要考量。”
-
“初期为快速迭代采用单体架构,后因业务复杂度增加和团队扩张,决定逐步向微服务演进。”
-
-
决策的当前影响与反思: 评估这些历史决策对当前系统的正面和负面影响,是否有需要重新审视或调整的决策。
十二、已知问题、技术债务与改进建议 (Known Issues, Technical Debt & Improvement Roadmap)
-
问题清单与优先级:
-
明确列出当前已知的Bug(尤其是严重的)、性能瓶颈、安全漏洞、设计缺陷或待优化区域。
-
为每个问题评估其严重性、影响范围和修复优先级。
-
-
技术债务详解:
-
识别并量化(如果可能)技术债务,如过时的库、临时性的解决方案(hacks)、缺乏测试的代码、不良的架构实践等。
-
分析技术债务的成因和潜在风险。
-
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3603
3603

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











