




概要
本文将对懂车帝的所有品牌车辆车型数据进行爬取,包括:车型,价格,车辆配置等信息。
一、使用模块
import re
from typing import Dict, Optional
import requests
from bs4 import BeautifulSoup
from pymongo import MongoClient
二、反爬技术
1.js压缩和混淆
对代码进行压缩(去除空格,换行符)和混淆(无意义变量)降低可读性,格式化使得无法定位到数据的真实位置。
2.动态网页
动态网站通过JavaScript异步加载数据,需要查找数据接口,并且请求参数通常被加密参数保护。
三、分析过程
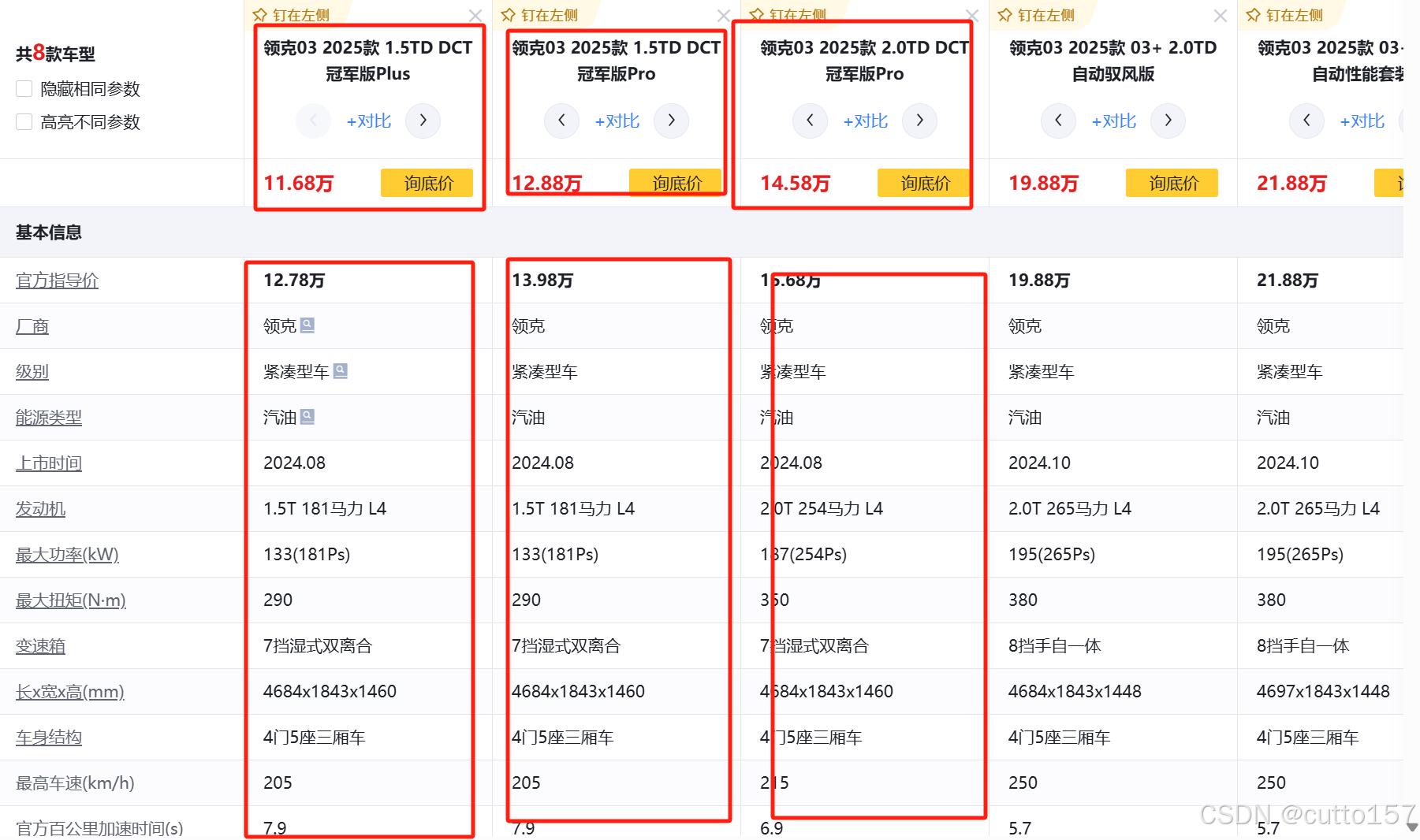
1.在选车页面,点击车型的参数,发现所有车型的数据,空白处右键,打开检查面板,选择网络选项卡,重新刷新网页,选取车名作为关键字进行搜索,发现数据嵌套在html,为静态网页。

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1088
1088



 到【灌水乐园】发言
到【灌水乐园】发言








