






序言
这里使用的是master分支,因为官网上并没有release分支,所以先用master分支吧,可能会有问题cuiyaonan2000@163.com
参考资料:
- https://github.com/alibaba/DataX
- https://github.com/alibaba/DataX/blob/master/introduction.md --插件说明文档
- https://github.com/alibaba/DataX/blob/master/dataxPluginDev.md
源码打包
- 首先下载 GitHub - alibaba/DataX: DataX是阿里云DataWorks数据集成的开源版本。代码
- 首先如果是JDK17则会报错,后来选择JDK1.8
- Datax的运行依赖于python所以需要安装python2或者python3,centos7自带的有python2.7.5
- 然后打包生成可执行的文件 mvn -U clean package assembly:assembly -Dmaven.test.skip=true
- 成功后在根目录下的target中有相关的打包结果,如果包含所有Reader和Writer则打包会慢一点,但是还是有必要的
执行命令
在datax的bin目录下
- python datax.py -r {YOUR_READER} -w {YOUR_WRITER} 该命令是显示对应的json模板,也可以直接从source或者reader的文档中查看
-
python datax.py json文件 该命令就是执行对应的json文件
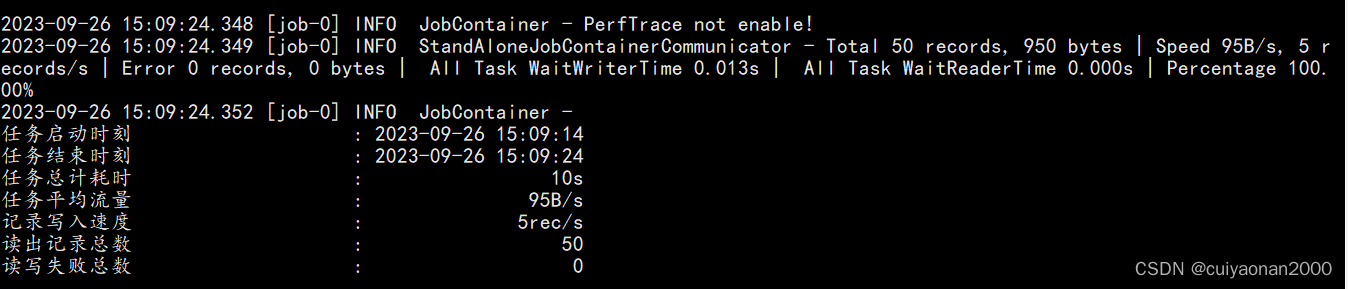
用例:Stream To Stream
{
"job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"sliceRecordCount": 10,
"column": [
{
"type": "long",
"value": "10"
},
{
"type": "string",
"value": "hello,你好,世界-DataX"
}
]
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "UTF-8",
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": 5
}
}
}
}执行结果
MysqlReader To Stream
通过命令python datax.py -r mysqlreader -w streamwriter 查看相关的模板为
DataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.
Please refer to the mysqlreader document:
https://github.com/alibaba/DataX/blob/master/mysqlreader/doc/mysqlreader.md
Please refer to the streamwriter document:
https://github.com/alibaba/DataX/blob/master/streamwriter/doc/streamwriter.md
Please save the following configuration as a json file and use
python {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json
to run the job.
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [],
"connection": [
{
"jdbcUrl": [],
"table": []
}
],
"password": "",
"username": "",
"where": ""
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "",
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": ""
}
}
}
}
然后编辑该json
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": ["Name","GroupName"],
"connection": [
{
"jdbcUrl": ["jdbc:mysql://192.168.137.2:3306/test"],
"table": ["employee"]
}
],
"password": "root",
"username": "root"
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "",
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
自定义插件
从设计之初,DataX就把异构数据源同步作为自身的使命,为了应对不同数据源的差异、同时提供一致的同步原语和扩展能力,DataX自然而然地采用了框架 + 插件 的模式:
- 插件只需关心数据的读取或者写入本身。
- 而同步的共性问题,比如:类型转换、性能、统计,则交由框架来处理。
作为插件开发人员,则需要关注两个问题----自定义插件要考虑的点感觉很简单啊cuiyaonan2000@163.com:
- 数据源本身的读写数据正确性。
- 如何与框架沟通、合理正确地使用框架。
逻辑执行模型
插件开发者不用关心太多,基本只需要关注特定系统读和写,以及自己的代码在逻辑上是怎样被执行的,哪一个方法是在什么时候被调用的。在此之前,需要明确以下概念:
Job:Job是DataX用以描述从一个源头到一个目的端的同步作业,是DataX数据同步的最小业务单元。比如:从一张mysql的表同步到odps的一个表的特定分区。Task:Task是为最大化而把Job拆分得到的最小执行单元。比如:读一张有1024个分表的mysql分库分表的Job,拆分成1024个读Task,用若干个并发执行。TaskGroup: 描述的是一组Task集合。在同一个TaskGroupContainer执行下的Task集合称之为TaskGroupJobContainer:Job执行器,负责Job全局拆分、调度、前置语句和后置语句等工作的工作单元。类似Yarn中的JobTrackerTaskGroupContainer:TaskGroup执行器,负责执行一组Task的工作单元,类似Yarn中的TaskTracker。
简而言之, Job拆分成Task,在分别在框架提供的容器中执行,插件只需要实现Job和Task两部分逻辑。
物理执行模型
框架为插件提供物理上的执行能力(线程)。DataX框架有三种运行模式:
Standalone: 单进程运行,没有外部依赖。Local: 单进程运行,统计信息、错误信息汇报到集中存储。Distrubuted: 分布式多进程运行,依赖DataX Service服务。
当然,上述三种模式对插件的编写而言没有什么区别,你只需要避开一些小错误,插件就能够在单机/分布式之间无缝切换了。 当JobContainer和TaskGroupContainer运行在同一个进程内时,就是单机模式(Standalone和Local);当它们分布在不同的进程中执行时,就是分布式(Distributed)模式。
编程接口
那么,Job和Task的逻辑应是怎么对应到具体的代码中的?
首先,插件的入口类必须扩展Reader或Writer抽象类,并且实现分别实现Job和Task两个内部抽象类,Job和Task的实现必须是 内部类 的形式,原因见 加载原理 一节。
以Reader为例:
public class SomeReader extends Reader {
public static class Job extends Reader.Job {
@Override
public void init() {
}
@Override
public void prepare() {
}
@Override
public List<Configuration> split(int adviceNumber) {
return null;
}
@Override
public void post() {
}
@Override
public void destroy() {
}
}
public static class Task extends Reader.Task {
@Override
public void init() {
}
@Override
public void prepare() {
}
@Override
public void startRead(RecordSender recordSender) {
}
@Override
public void post() {
}
@Override
public void destroy() {
}
}
}Job接口功能如下:
init: Job对象初始化工作,此时可以通过super.getPluginJobConf()获取与本插件相关的配置。读插件获得配置中reader部分,写插件获得writer部分。-----获取插件配置信息cuiyaonan2000@163.comprepare: 全局准备工作,比如odpswriter清空目标表。split: 拆分Task。参数adviceNumber框架建议的拆分数,一般是运行时所配置的并发度。值返回的是Task的配置列表。post: 全局的后置工作,比如mysqlwriter同步完影子表后的rename操作。destroy: Job对象自身的销毁工作。
Task接口功能如下:
init:Task对象的初始化。此时可以通过super.getPluginJobConf()获取与本Task相关的配置。这里的配置是Job的split方法返回的配置列表中的其中一个。prepare:局部的准备工作。startRead: 从数据源读数据,写入到RecordSender中。RecordSender会把数据写入连接Reader和Writer的缓存队列。startWrite:从RecordReceiver中读取数据,写入目标数据源。RecordReceiver中的数据来自Reader和Writer之间的缓存队列。post: 局部的后置工作。destroy: Task象自身的销毁工作。
需要注意的是:
Job和Task之间一定不能有共享变量,因为分布式运行时不能保证共享变量会被正确初始化。两者之间只能通过配置文件进行依赖。prepare和post在Job和Task中都存在,插件需要根据实际情况确定在什么地方执行操作。
插件定义
码写好了,有没有想过框架是怎么找到插件的入口类的?框架是如何加载插件的呢?
在每个插件的项目中,都有一个plugin.json文件,这个文件定义了插件的相关信息,包括入口类。例如:
{
"name": "mysqlwriter",
"class": "com.alibaba.datax.plugin.writer.mysqlwriter.MysqlWriter",
"description": "Use Jdbc connect to database, execute insert sql.",
"developer": "alibaba"
}
name: 插件名称,大小写敏感。框架根据用户在配置文件中指定的名称来搜寻插件。 十分重要 。class: 入口类的全限定名称,框架通过反射插件入口类的实例。十分重要 。description: 描述信息。developer: 开发人员。
例如:
插件打包
打包后的位置跟目录其它插件一样,举例来说:
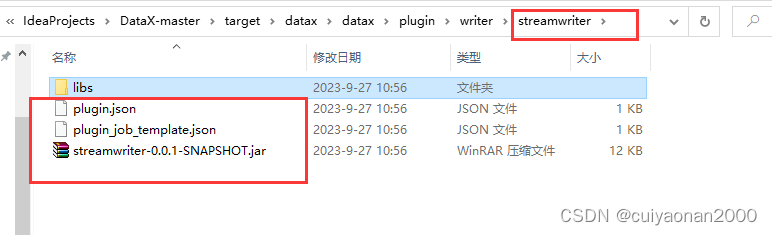
插件目录分为reader和writer子目录,读写插件分别存放。插件目录规范如下:
${PLUGIN_HOME}/libs: 插件的依赖库。${PLUGIN_HOME}/plugin-name-version.jar: 插件本身的jar。${PLUGIN_HOME}/plugin.json: 插件描述文件。
尽管框架加载插件时,会把${PLUGIN_HOME}下所有的jar放到classpath,但还是推荐依赖库的jar和插件本身的jar分开存放
插件配置文件设计
DataX使用json作为配置文件的格式。一个典型的DataX任务配置如下:
{
"job": {
"content": [
{
"reader": {
"name": "odpsreader",
"parameter": {
"accessKey": "",
"accessId": "",
"column": [""],
"isCompress": "",
"odpsServer": "",
"partition": [
""
],
"project": "",
"table": "",
"tunnelServer": ""
}
},
"writer": {
"name": "oraclewriter",
"parameter": {
"username": "",
"password": "",
"column": ["*"],
"connection": [
{
"jdbcUrl": "",
"table": [
""
]
}
]
}
}
}
]
}
}DataX框架有core.json配置文件,指定了框架的默认行为。任务的配置里头可以指定框架中已经存在的配置项,而且具有更高的优先级,会覆盖core.json中的默认值。
配置中job.content.reader.parameter的value部分会传给Reader.Job;job.content.writer.parameter的value部分会传给Writer.Job ,Reader.Job和Writer.Job可以通过super.getPluginJobConf()来获取。----------就是我们自定义插件也要满足core.json的整体格式,在规定的key下编辑自己的插件属性cuiyaonan2000@163.com
DataX框架支持对特定的配置项进行RSA加密,例子中以*开头的项目便是加密后的值。 配置项加密解密过程对插件是透明,插件仍然以不带*的key来查询配置和操作配置项 。-------这个可定时有用的cuiyaonan2000@163.com
工具Configuration
为了简化对json的操作,DataX提供了简单的DSL配合Configuration类使用。---提供了一个解析Json的工具类
Configuration提供了常见的get, 带类型get,带默认值get,set等读写配置项的操作,以及clone, toJSON等方法。配置项读写操作都需要传入一个path做为参数,这个path就是DataX定义的DSL。语法有两条:
- 子map用
.key表示,path的第一个点省略。 - 数组元素用
[index]表示。
比如操作如下json:
{
"a": {
"b": {
"c": 2
},
"f": [
1,
2,
{
"g": true,
"h": false
},
4
]
},
"x": 4
}
比如调用configuration.get(path)方法,当path为如下值的时候得到的结果为:
x:4a.b.c:2a.b.c.d:nulla.b.f[0]:1a.b.f[2].g:true
注意,因为插件看到的配置只是整个配置的一部分。使用Configuration对象时,需要注意当前的根路径是什么。
更多Configuration的操作请参考ConfigurationTest.java。
Channel
跟一般的生产者-消费者模式一样,Reader插件和Writer插件之间也是通过channel来实现数据的传输的。channel可以是内存的,也可能是持久化的,插件不必关心。插件通过RecordSender往channel写入数据,通过RecordReceiver从channel读取数据。
channel中的一条数据为一个Record的对象,Record中可以放多个Column对象,这可以简单理解为数据库中的记录和列。
Record有如下方法(感觉最外层是个数组cuiyaonan2000@163.com):
public interface Record {
// 加入一个列,放在最后的位置
void addColumn(Column column);
// 在指定下标处放置一个列
void setColumn(int i, final Column column);
// 获取一个列
Column getColumn(int i);
// 转换为json String
String toString();
// 获取总列数
int getColumnNumber();
// 计算整条记录在内存中占用的字节数
int getByteSize();
}- 因为
Record是一个接口,Reader插件首先调用RecordSender.createRecord()创建一个Record实例,然后把Column一个个添加到Record中。 Writer插件调用RecordReceiver.getFromReader()方法获取Record,然后把Column遍历出来,写入目标存储中。当Reader尚未退出,传输还在进行时,如果暂时没有数据RecordReceiver.getFromReader()方法会阻塞直到有数据。如果传输已经结束,会返回null,Writer插件可以据此判断是否结束startWrite方法。-----------结束标致太够模糊了,没有固定的标识么cuiyaonan2000@163.com
Column的构造和操作,我们在《类型转换》一节介绍。
类型转换
为了规范源端和目的端类型转换操作,保证数据不失真,DataX支持六种内部数据类型:
Long:定点数(Int、Short、Long、BigInteger等)。Double:浮点数(Float、Double、BigDecimal(无限精度)等)。String:字符串类型,底层不限长,使用通用字符集(Unicode)。Date:日期类型。Bool:布尔值。Bytes:二进制,可以存放诸如MP3等非结构化数据。
对应地,有DateColumn、LongColumn、DoubleColumn、BytesColumn、StringColumn和BoolColumn六种Column的实现。
Column除了提供数据相关的方法外,还提供一系列以as开头的数据类型转换转换方法。
DataX的内部类型在实现上会选用不同的java类型:
| 内部类型 | 实现类型 | 备注 |
|---|---|---|
| Date | java.util.Date | |
| Long | java.math.BigInteger | 使用无限精度的大整数,保证不失真 |
| Double | java.lang.String | 用String表示,保证不失真 |
| Bytes | byte[] | |
| String | java.lang.String | |
| Bool | java.lang.Boolean |
类型之间相互转换的关系如下:
| from\to | Date | Long | Double | Bytes | String | Bool |
|---|---|---|---|---|---|---|
| Date | - | 使用毫秒时间戳 | 不支持 | 不支持 | 使用系统配置的date/time/datetime格式转换 | 不支持 |
| Long | 作为毫秒时间戳构造Date | - | BigInteger转为BigDecimal,然后BigDecimal.doubleValue() | 不支持 | BigInteger.toString() | 0为false,否则true |
| Double | 不支持 | 内部String构造BigDecimal,然后BigDecimal.longValue() | - | 不支持 | 直接返回内部String | |
| Bytes | 不支持 | 不支持 | 不支持 | - | 按照common.column.encoding配置的编码转换为String,默认utf-8 | 不支持 |
| String | 按照配置的date/time/datetime/extra格式解析 | 用String构造BigDecimal,然后取longValue() | 用String构造BigDecimal,然后取doubleValue(),会正确处理NaN/Infinity/-Infinity | 按照common.column.encoding配置的编码转换为byte[],默认utf-8 | - | "true"为true, "false"为false,大小写不敏感。其他字符串不支持 |
| Bool | 不支持 | true为1L,否则0L | true为1.0,否则0.0 | 不支持 | - |
脏数据处理
目前主要有三类脏数据:
- Reader读到不支持的类型、不合法的值。
- 不支持的类型转换,比如:
Bytes转换为Date。 - 写入目标端失败,比如:写mysql整型长度超长。
在Reader.Task和Writer.Task中,通过AbstractTaskPlugin.getTaskPluginCollector()可以拿到一个TaskPluginCollector,它提供了一系列collectDirtyRecord的方法。当脏数据出现时,只需要调用合适的collectDirtyRecord方法,把被认为是脏数据的Record传入即可。
用户可以在任务的配置中指定脏数据限制条数或者百分比限制,当脏数据超出限制时,框架会结束同步任务,退出。插件需要保证脏数据都被收集到,其他工作交给框架就好。



















 1593
1593

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











