




 本文介绍如何使用Apache Flink与Kafka进行集成,包括配置依赖、连接器使用及自定义序列化等内容。演示了如何创建Flink Kafka生产者与消费者,并展示了如何设置水位线来处理乱序数据。
本文介绍如何使用Apache Flink与Kafka进行集成,包括配置依赖、连接器使用及自定义序列化等内容。演示了如何创建Flink Kafka生产者与消费者,并展示了如何设置水位线来处理乱序数据。
序言
Kafka作为Flink的数据源来进行Demo的制作。
参考:
- Apache Flink 1.12 Documentation: Apache Kafka 连接器
- Apache Flink 1.10 Documentation: 配置依赖、连接器、类库
- 生成 Watermark | Apache Flink
Kafka连接器版本选择
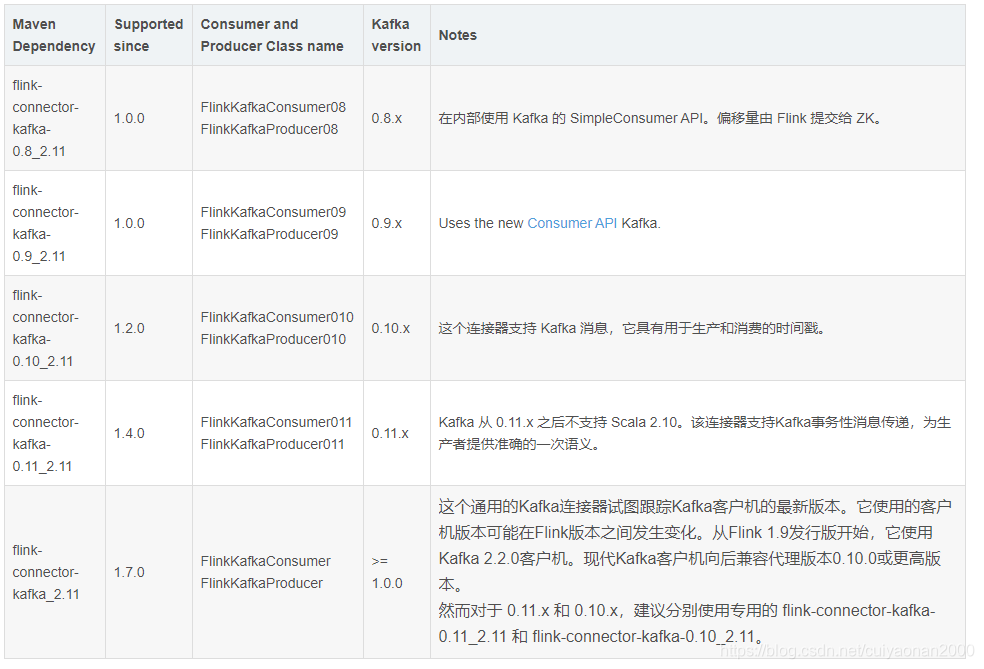
连接器JAR
Flink-kafka-connector用来做什么?
Kafka中的partition机制和Flink的并行度机制结合,实现数据恢复
Kafka可以作为Flink的source和sink
任务失败,通过设置kafka的offset来恢复应用
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.12.0</version>
</dependency>自定义序列化
如果要自定义序列化类则需要用到如下的jar
- flink 提供的SimpleStringSchema反序列化默认只将消息输出,topic信息没有,
- JSONKeyValueDeserializationSchema类提供了topic消息,要求消息体为json。
- 当这些不能满足时,flink也提供了序列化和反序列化接口KeyedDeserializationSchema和KeyedSerializationSchema,可以自定义实现。我们一般都是从kafka消费消息自定义实现KeyedDeserializationSchema接口就可以了。
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-avro</artifactId>
<version>1.12.0</version>
</dependency>source
package cui.yao.nan.flink.string;
import java.util.Properties;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import org.springframework.boot.CommandLineRunner;
import com.google.gson.Gson;
import cui.yao.nan.pojo.Person;
public class KafkaProducer implements CommandLineRunner{
public static Gson gson = new Gson();
public static void main(String[] args) {
new KafkaProducer().run(null);
}
@Override
public void run(String... args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//FlinkKafkaConsumer<String>(String topic, DeserializationSchema<String> valueDeserializer, Properties props)
FlinkKafkaProducer<String> kafkaProducer = new
FlinkKafkaProducer<String>("topic-name-cui"
, new SimpleStringSchema() , getProperties());
// 加上时间戳,0.10版本之后可以用
kafkaProducer.setWriteTimestampToKafka(true);
DataStream<String> dataStream = env.fromElements(
gson.toJson(new Person("cui",1)),
gson.toJson(new Person("yao",2)),
gson.toJson(new Person("nan",3)));
//中间可以对dataStream进行处理
//print() 打印其结果到 task manager 的日志中
//(如果运行在 IDE 中时,将追加到你的 IDE 控制台)。它会对流中的每个元素都调用 toString() 方法。
dataStream.addSink(kafkaProducer);
try {
env.execute("start kafkaproducer");
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
private Properties getProperties() {
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "10.1.80.190:9092");
properties.setProperty("zookeeper.connect", "10.1.80.190:2181");
properties.setProperty("group.id", "15");
// properties.setProperty("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// properties.setProperty("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
return properties;
}
}
source中控制消费的位置
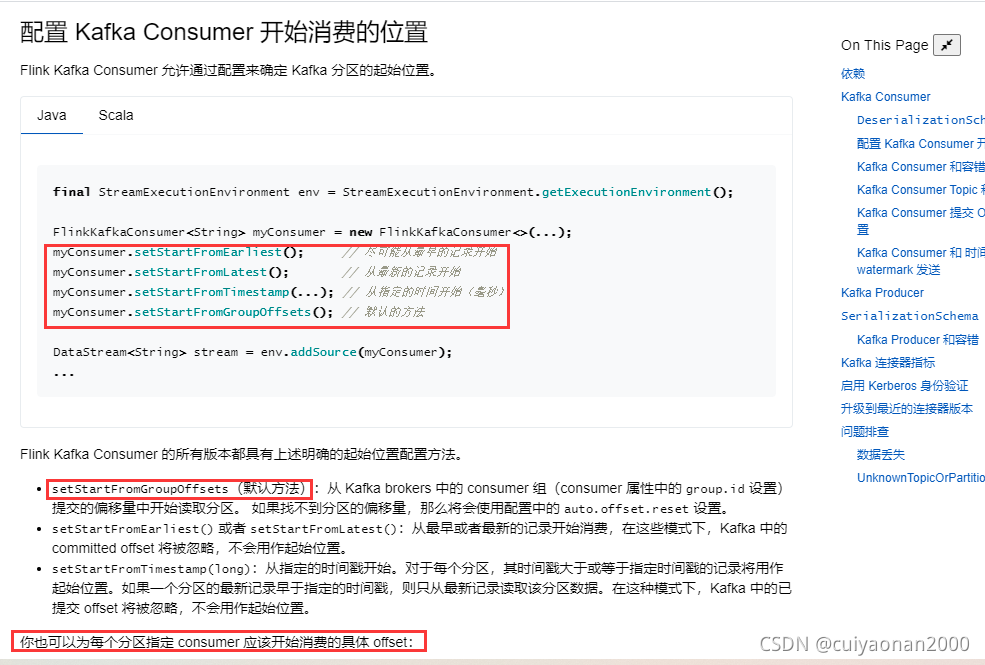
消费失败的管理

对应的代码如下:

设置水位线控制类
这里必须要设置否则没窗口
这里写法较多可以参考生成 Watermark | Apache Flink

参考代码如下:
package demo;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
import java.time.Duration;
/**
* Author: Chenghui Bai
* Date: 2021/3/4 17:48
* ProjectName: frauddetection
* PackageName: demo
* ClassName: WatermarkWCDemo
* Version:
* Description:
*/
public class WatermarkWCDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> inputStream = env.socketTextStream("localhost", 7777);
SerializableTimestampAssigner<String> timestampAssigner = new SerializableTimestampAssigner<String>() {
@Override
public long extractTimestamp(String element, long recordTimestamp) {
String[] fields = element.split(",");
Long aLong = new Long(fields[0]);
return aLong * 1000L;
}
};
SingleOutputStreamOperator<String> watermarkStream = inputStream.assignTimestampsAndWatermarks(WatermarkStrategy.<String>forBoundedOutOfOrderness(Duration.ofSeconds(10)).withTimestampAssigner(timestampAssigner));
watermarkStream.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] fields = value.split(",");
out.collect(new Tuple2<>(fields[1], 1));
}
}).keyBy(data -> data.f0).window(TumblingEventTimeWindows.of(Time.seconds(10))).sum(1).print();
env.execute("run watermark wc");
}
}sink
package cui.yao.nan.flink.string;
import java.util.Properties;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.springframework.boot.CommandLineRunner;
public class KafkaConsumer implements CommandLineRunner {
public static void main(String[] args) {
new KafkaConsumer().run(null);
}
@Override
public void run(String... args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// FlinkKafkaConsumer<String>(String topic, DeserializationSchema<String>
// valueDeserializer, Properties props)
FlinkKafkaConsumer<String> kafkaConsumer = new FlinkKafkaConsumer<>("topic-name-cui",
new SimpleStringSchema(),
getProperties());
DataStream<String> dataStream = env.addSource(kafkaConsumer);
//打印也是一种sink
dataStream.print();
try {
env.execute("start kafkaconsume");
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
private Properties getProperties() {
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "10.1.80.190:9092");
properties.setProperty("zookeeper.connect", "10.1.80.190:2181");
properties.setProperty("group.id", "422");
// properties.setProperty("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// properties.setProperty("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
return properties;
}
}
消费内容如下:( 2> 指出输出来自哪个 sub-task(即 thread))
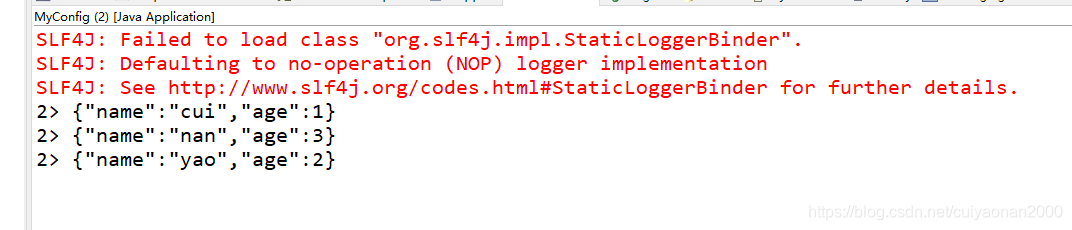



















 3562
3562

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











