







 本文对比了使用Excel和Jupyter Notebook对身高体重数据集进行线性回归分析的过程。通过20组、200组及2000组数据的分析,发现随着数据量增加,Excel中的R²值趋于0,表明相关性减弱。在Jupyter中,通过自编程序和sklearn库进行了重新分析,得到了更精确的结果,但操作相对复杂。结论是,虽然Excel操作简便,但在精度上不及Jupyter。
本文对比了使用Excel和Jupyter Notebook对身高体重数据集进行线性回归分析的过程。通过20组、200组及2000组数据的分析,发现随着数据量增加,Excel中的R²值趋于0,表明相关性减弱。在Jupyter中,通过自编程序和sklearn库进行了重新分析,得到了更精确的结果,但操作相对复杂。结论是,虽然Excel操作简便,但在精度上不及Jupyter。
人工智能与机器学习之初试线性回归
文章目录**
**1.使用Excel分析身高体重数据集
分别以 20、200、2000 组数据进行联系:**
20组数据
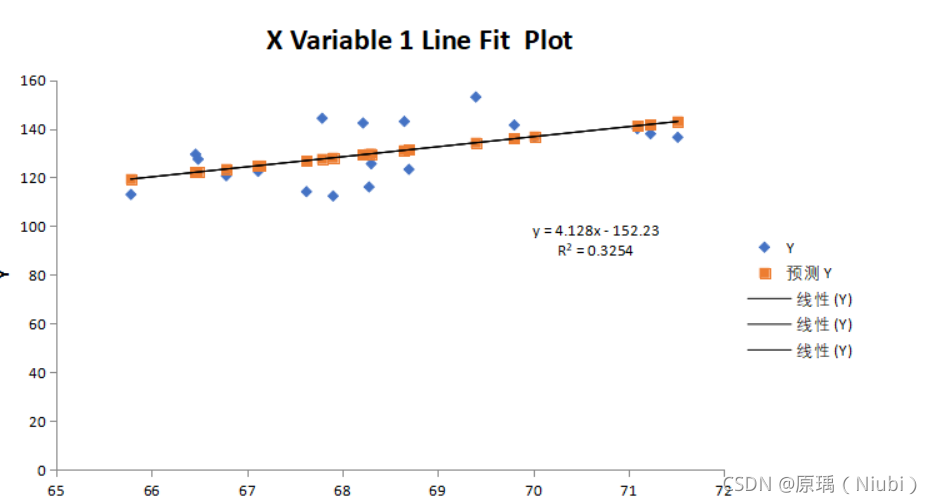
回归方程式:y=4.128-152.23
相关系数R2:R²=0.325
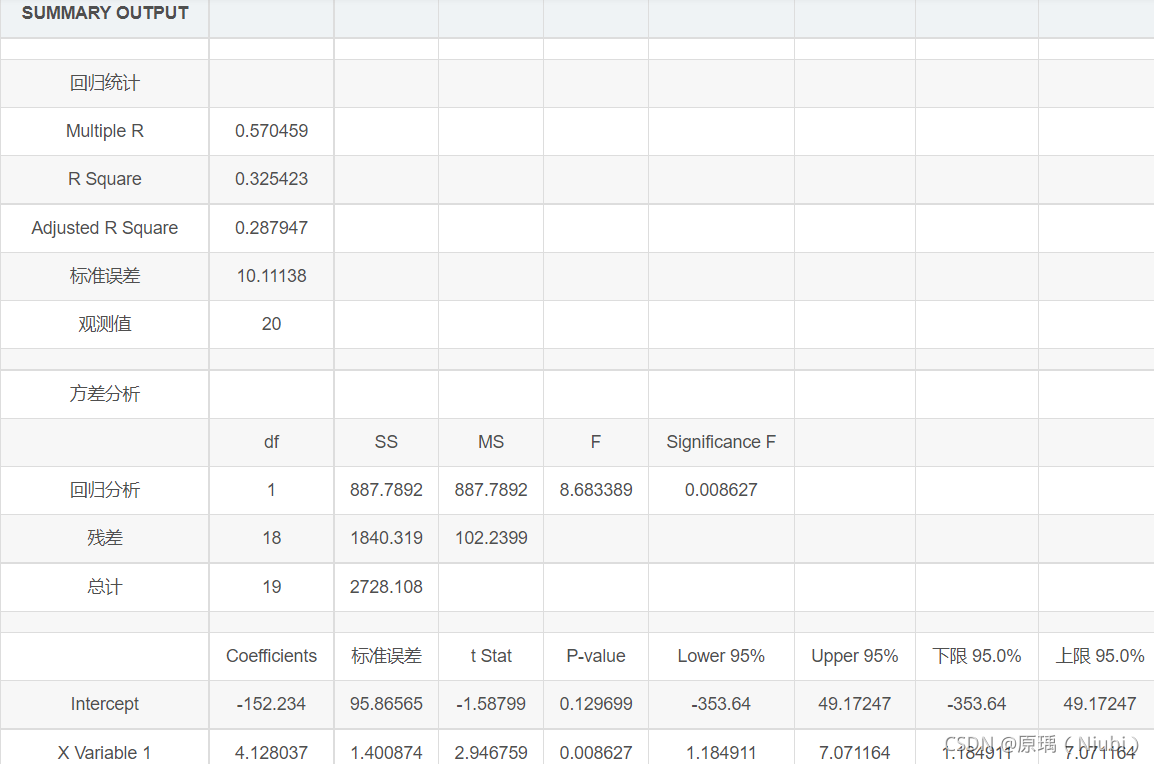
详情分析
200组数据
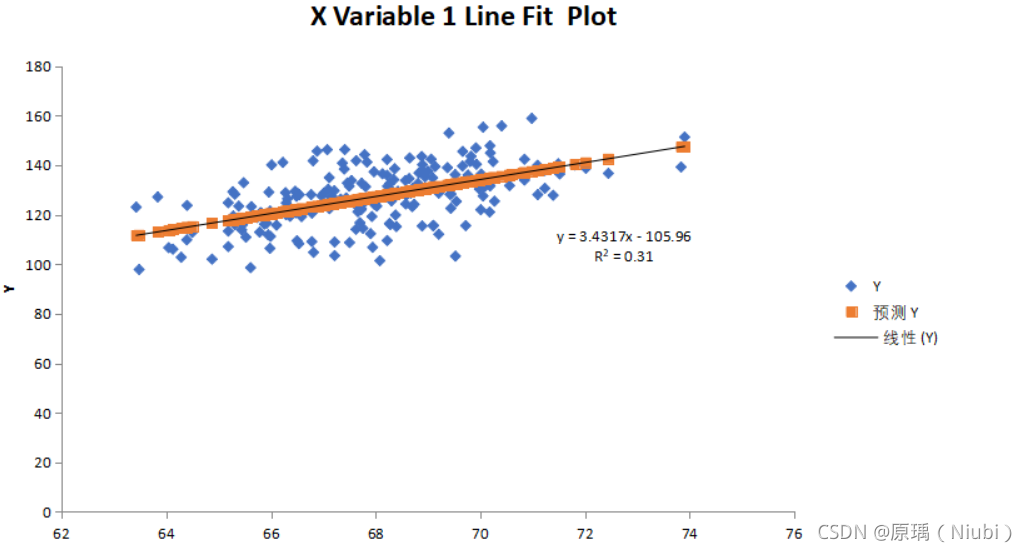
回归方程式:y=3.4317-105.96
相关系数R2:R²=0.31
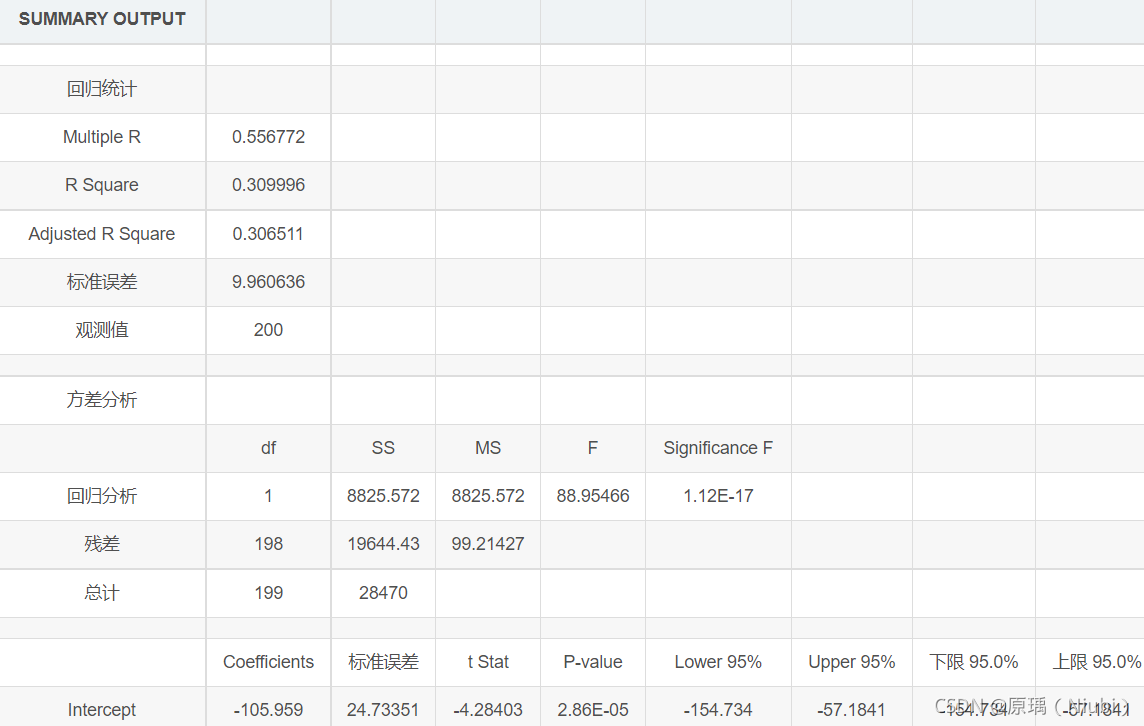
详情分析:
2000组数据
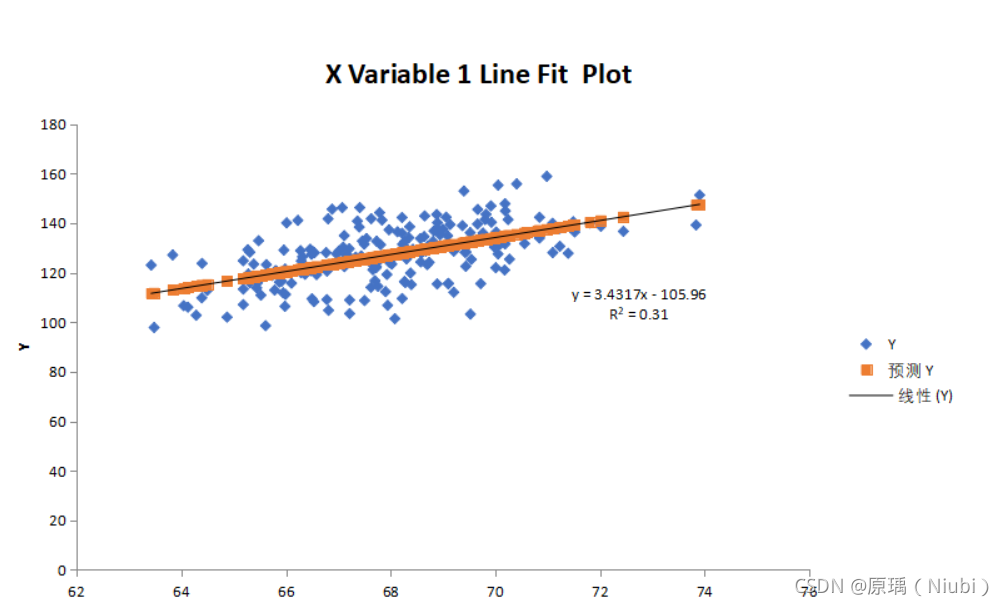
回归方程式:y=2.9555x-73.661
相关系数R2:R²=0.2483
详情分析:
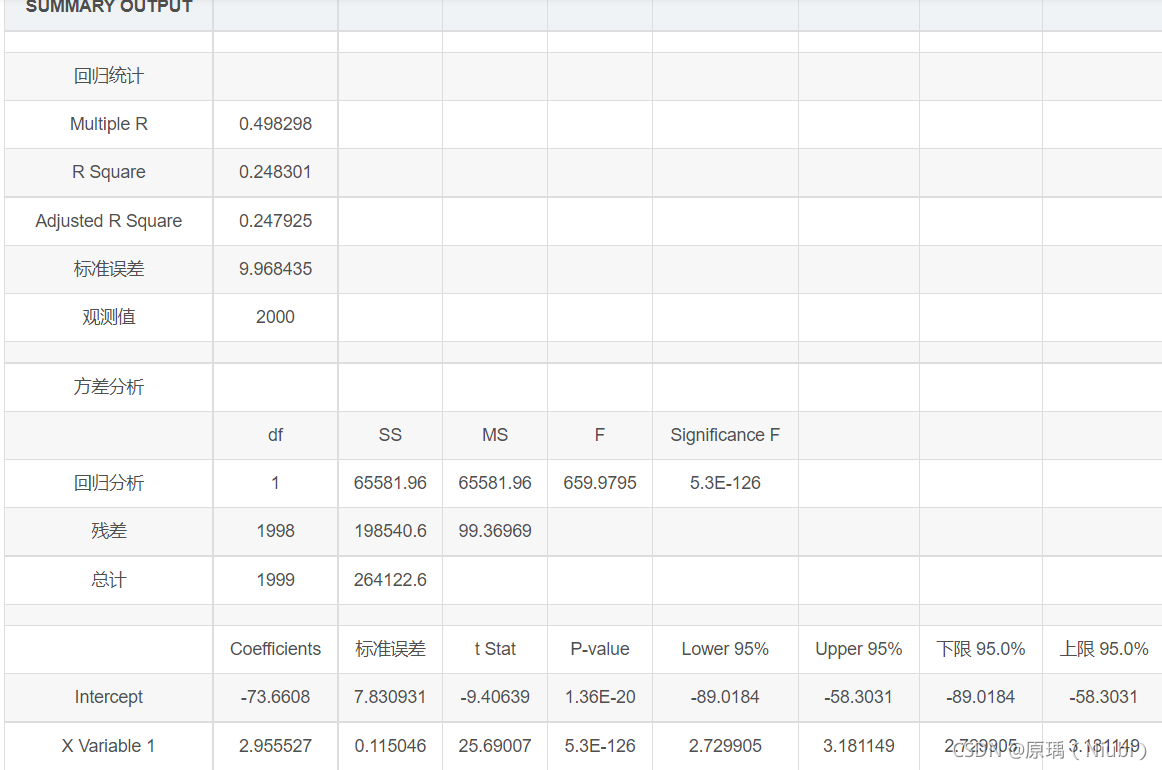
总结:数据越多,R2值越接近于0,证明身高与体重的相关性不大。
**
2.通过jupyter编程做出最小二乘法重新分析数据
2.1 不借助第三方库:
**运用Jupyter notebook编写一个可视化的线性回归方程程序:
new一个python3项目
下面是源代码
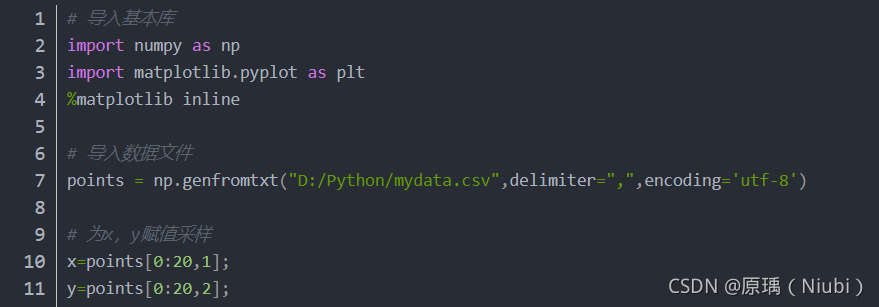
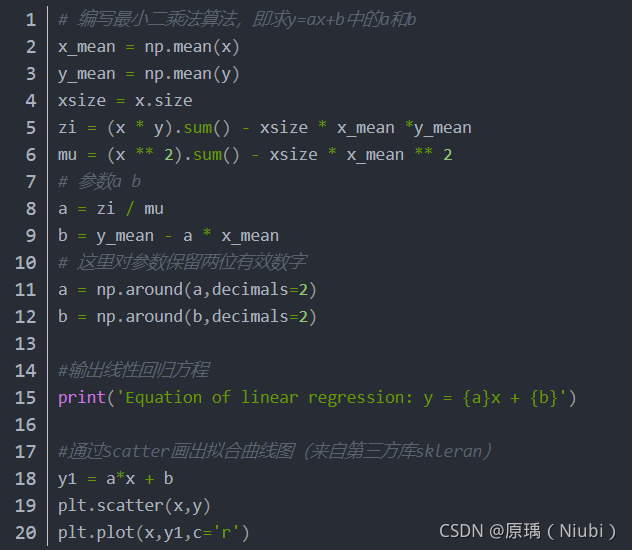
运行结果:
20组数据:
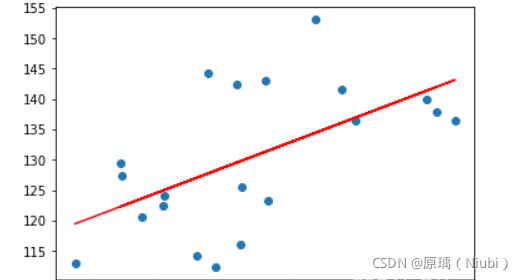
200组数据:
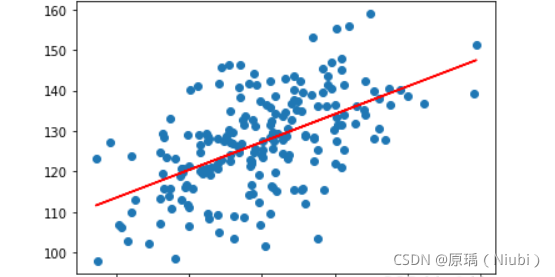
2000组数据:
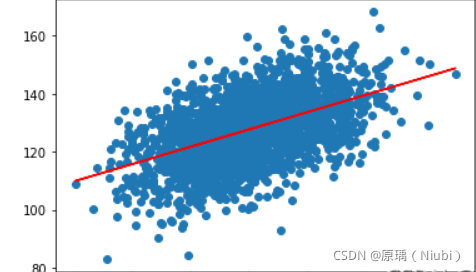
借助skleran库##
依然使用jupyter notebook编写一个可视化的线性回归方程程序,但是这次借助了sklearan库。
输出结果:
20组数据:
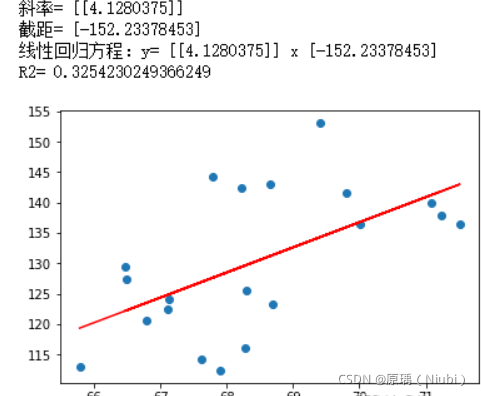
200组数据:
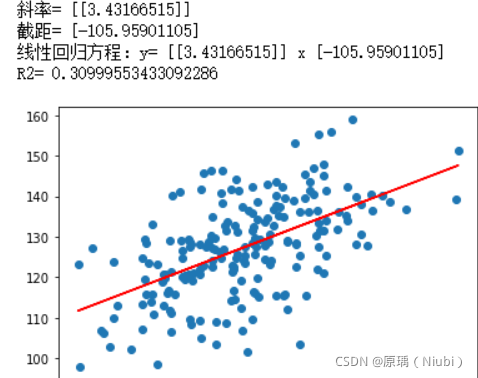
2000组数据:
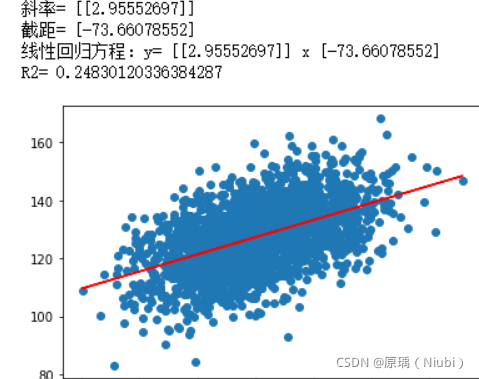
3. 结果对比:

总结:如图所示,两种jupyter的操作可以得到相对更加准确的数据,但是操作起来较困难,excel的操作很简单,结果相对准确,但是精度不如jupter

















 2848
2848

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









