






最近很火的deepseek模型用到了知识蒸馏的技术。
在深度学习中,较大的模型通常能取得更好的性能,但它们对计算资源的需求也更高。如何在保证性能的同时,降低模型的复杂度和计算需求成为了一大挑战。
知识蒸馏(Knowledge Distillation) 提供了一种有效的解决方案。今天我们就让大模型手把手带小模型刷题,看看这个让模型瘦身90%还能保持高智商的秘密配方!
一、知识蒸馏:AI界的"灌顶大法"
什么是知识蒸馏?
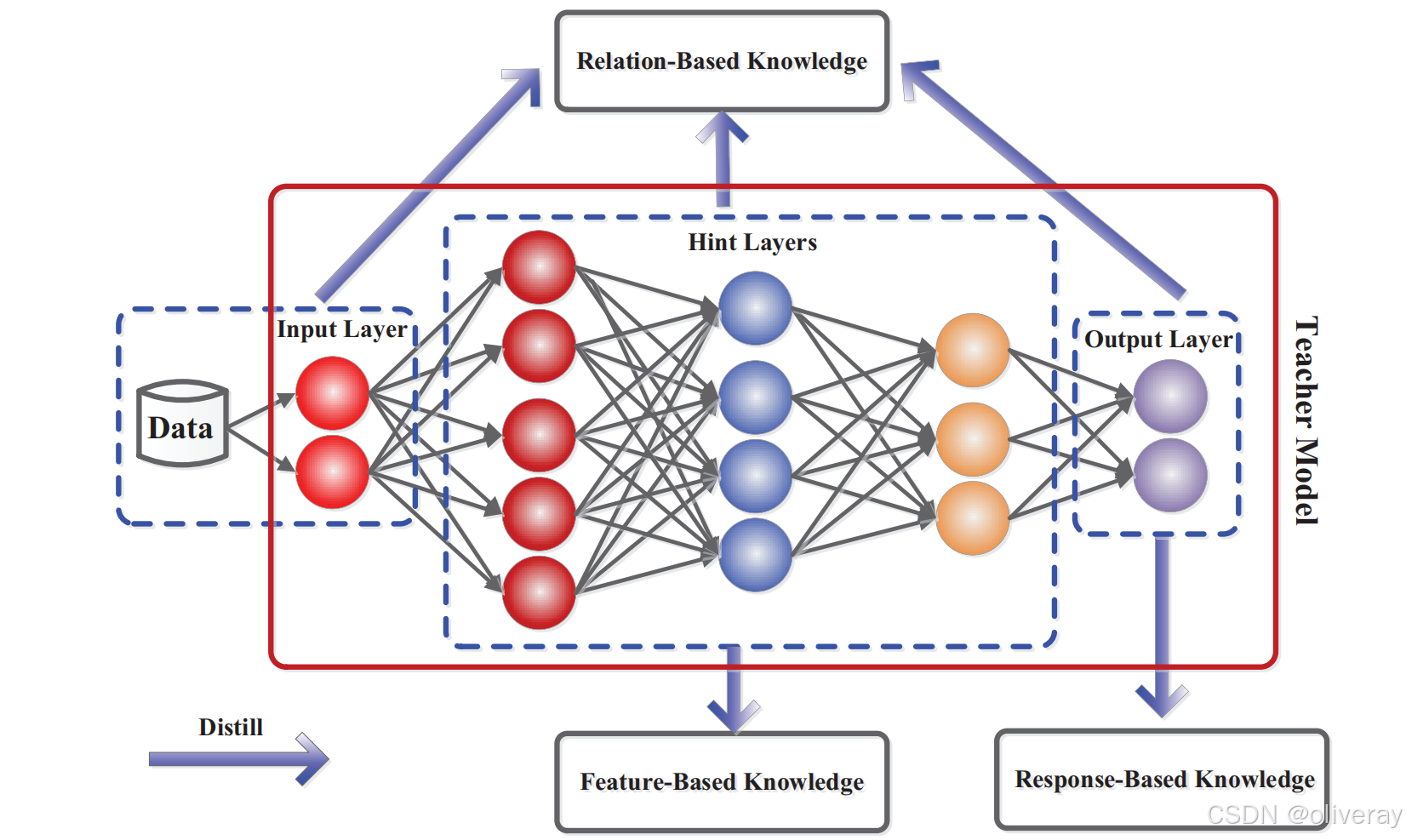
知识蒸馏是由 Hinton 等人提出的一种模型压缩技术。其核心思想是利用一个性能优异但复杂的教师模型(Teacher Model),来指导一个较小且简单的学生模型(Student Model)进行训练。
在传统的模型训练中,我们仅使用真实标签来计算损失。而在知识蒸馏中,学生模型除了使用真实标签外,还会学习教师模型软标签(Soft Label),即教师模型对各类别的预测概率分布。
教师模型(Teacher)将自己对数据的'理解感悟'通过soft targets传递给学生模型。不同于简单临摹标准答案,这种带温度的学习让学生既掌握解题思路(特征分布),又记住标准答案(hard labels)。
# 关键代码解读 - 知识传递的"温度控制器"
T = 4 # 知识蒸馏的"火候调节"
distill_loss = KLDivLoss(log_softmax(student_output/T), softmax(teacher_output/T))二、实战——双通道学习:学霸养成的秘密武器
首先,我训练好了一个结构较为复杂的分类模型FasterViT
def window_partition(x, window_size):
B, C, H, W = x.shape
x = x.view(B, C, H // window_size, window_size, W // window_size, window_size)
windows = x.permute(0, 2, 4, 3, 5, 1).reshape(-1, window_size*window_size, C)
return windows
def window_reverse(windows, window_size, H, W, B):
x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)
x = x.permute(0, 5, 1, 3, 2, 4).reshape(B, windows.shape[2], H, W)
return x
def ct_dewindow(ct, W, H, window_size):
bs = ct.shape[0]
N=ct.shape[2]
ct2 = ct.view(-1, W//window_size, H//window_size, window_size, window_size, N).permute(0, 5, 1, 3, 2, 4)
ct2 = ct2.reshape(bs, N, W*H).transpose(1, 2)
return ct2
def ct_window(ct, W, H, window_size):
bs = ct.shape[0]
N = ct.shape[2]
ct = ct.view(bs, H // window_size, window_size, W // window_size, window_size, N)
ct = ct.permute(0, 1, 3, 2, 4, 5)
return ct
def _load_state_dict(module, state_dict, strict=False, logger=None):
unexpected_keys = []
all_missing_keys = []
err_msg = []
metadata = getattr(state_dict, '_metadata', None)
state_dict = state_dict.copy()
if metadata is not None:
state_dict._metadata = metadata
def load(module, prefix=''):
local_metadata = {} if metadata is None else metadata.get(
prefix[:-1], {})
module._load_from_state_dict(state_dict, prefix, local_metadata, True,
all_missing_keys, unexpected_keys,
err_msg)
for name, child in module._modules.items():
if child is not None:
load(child, prefix + name + '.')
load(module)
load = None
missing_keys = [
key for key in all_missing_keys if 'num_batches_tracked' not in key
]
if unexpected_keys:
err_msg.append('unexpected key in source '
f'state_dict: {", ".join(unexpected_keys)}\n')
if missing_keys:
err_msg.append(
f'missing keys in source state_dict: {", ".join(missing_keys)}\n')
if len(err_msg) > 0:
err_msg.insert(
0, 'The model and loaded state dict do not match exactly\n')
err_msg = '\n'.join(err_msg)
if strict:
raise RuntimeError(err_msg)
elif logger is not None:
logger.warning(err_msg)
else:
print(err_msg)
def _load_checkpoint(model,
filename,
map_location='cpu',
strict=False,
logger=None):
checkpoint = torch.load(filename, map_location=map_location)
if not isinstance(checkpoint, dict):
raise RuntimeError(
f'No state_dict found in checkpoint file {filename}')
if 'state_dict' in checkpoint:
state_dict = checkpoint['state_dict']
elif 'model' in checkpoint:
state_dict = checkpoint['model']
else:
state_dict = checkpoint
if list(state_dict.keys())[0].startswith('module.'):
state_dict = {k[7:]: v for k, v in state_dict.items()}
if sorted(list(state_dict.keys()))[0].startswith('encoder'):
state_dict = {k.replace('encoder.', ''): v for k, v in state_dict.items() if k.startswith('encoder.')}
_load_state_dict(model, state_dict, strict, logger)
return checkpoint
class PosEmbMLPSwinv2D(nn.Module):
def __init__(self,
window_size,
pretrained_window_size,
num_heads, seq_length,
ct_correct=False,
no_log=False):
super().__init__()
self.window_size = window_size
self.num_heads = num_heads
self.cpb_mlp = nn.Sequential(nn.Linear(2, 512, bias=True),
nn.ReLU(inplace=True),
nn.Linear(512, num_heads, bias=False))
relative_coords_h = torch.arange(-(self.window_size[0] - 1), self.window_size[0], dtype=torch.float32)
relative_coords_w = torch.arange(-(self.window_size[1] - 1), self.window_size[1], dtype=torch.float32)
relative_coords_table = torch.stack(
torch.meshgrid([relative_coords_h,
relative_coords_w])).permute(1, 2, 0).contiguous().unsqueeze(0) # 1, 2*Wh-1, 2*Ww-1, 2
if pretrained_window_size[0] > 0:
relative_coords_table[:, :, :, 0] /= (pretrained_window_size[0] - 1)
relative_coords_table[:, :, :, 1] /= (pretrained_window_size[1] - 1)
else:
relative_coords_table[:, :, :, 0] /= (self.window_size[0] - 1)
relative_coords_table[:, :, :, 1] /= (self.window_size[1] - 1)
if not no_log:
relative_coords_table *= 8 # normalize to -8, 8
relative_coords_table = torch.sign(relative_coords_table) * torch.log2(
torch.abs(relative_coords_table) + 1.0) / np.log2(8)
self.register_buffer("relative_coords_table", relative_coords_table)
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w]))
coords_flatten = torch.flatten(coords, 1)
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :]
relative_coords = relative_coords.permute(1, 2, 0).contiguous()
relative_coords[:, :, 0] += self.window_size[0] - 1
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1)
self.register_buffer("relative_position_index", relative_position_index)
self.grid_exists = False
self.pos_emb = None
self.deploy = False
relative_bias = torch.zeros(1, num_heads, seq_length, seq_length)
self.seq_length = seq_length
self.register_buffer("relative_bias", relative_bias)
self.ct_correct=ct_correct
def switch_to_deploy(self):
self.deploy = True
def forward(self, input_tensor, local_window_size):
if self.deploy:
input_tensor += self.relative_bias
return input_tensor
else:
self.grid_exists = False
if not self.grid_exists:
self.grid_exists = True
relative_position_bias_table = self.cpb_mlp(self.relative_coords_table).view(-1, self.num_heads)
relative_position_bias = relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1],
-1)
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous()
relative_position_bias = 16 * torch.sigmoid(relative_position_bias)
n_global_feature = input_tensor.shape[2] - local_window_size
if n_global_feature > 0 and self.ct_correct:
step_for_ct=self.window_size[0]/(n_global_feature**0.5+1)
seq_length = int(n_global_feature ** 0.5)
indices = []
for i in range(seq_length):
for j in range(seq_length):
ind = (i+1)*step_for_ct*self.window_size[0] + (j+1)*step_for_ct
indices.append(int(ind))
top_part = relative_position_bias[:, indices, :]
lefttop_part = relative_position_bias[:, indices, :][:, :, indices]
left_part = relative_position_bias[:, :, indices]
relative_position_bias = torch.nn.functional.pad(relative_position_bias, (n_global_feature,
0,
n_global_feature,
0)).contiguous()
if n_global_feature>0 and self.ct_correct:
relative_position_bias = relative_position_bias*0.0
relative_position_bias[:, :n_global_feature, :n_global_feature] = lefttop_part
relative_position_bias[:, :n_global_feature, n_global_feature:] = top_part
relative_position_bias[:, n_global_feature:, :n_global_feature] = left_part
self.pos_emb = relative_position_bias.unsqueeze(0)
self.relative_bias = self.pos_emb
input_tensor += self.pos_emb
return input_tensor
class PosEmbMLPSwinv1D(nn.Module):
def __init__(self,
dim,
rank=2,
seq_length=4,
conv=False):
super().__init__()
self.rank = rank
if not conv:
self.cpb_mlp = nn.Sequential(nn.Linear(self.rank, 512, bias=True),
nn.ReLU(),
nn.Linear(512, dim, bias=False))
else:
self.cpb_mlp = nn.Sequential(nn.Conv1d(self.rank, 512, 1,bias=True),
nn.ReLU(),
nn.Conv1d(512, dim, 1,bias=False))
self.grid_exists = False
self.pos_emb = None
self.deploy = False
relative_bias = torch.zeros(1,seq_length, dim)
self.register_buffer("relative_bias", relative_bias)
self.conv = conv
def switch_to_deploy(self):
self.deploy = True
def forward(self, input_tensor):
seq_length = input_tensor.shape[1] if not self.conv else input_tensor.shape[2]
if self.deploy:
return input_tensor + self.relative_bias
else:
self.grid_exists = False
if not self.grid_exists:
self.grid_exists = True
if self.rank == 1:
relative_coords_h = torch.arange(0, seq_length, device=input_tensor.device, dtype = input_tensor.dtype)
relative_coords_h -= seq_length//2
relative_coords_h /= (seq_length//2)
relative_coords_table = relative_coords_h
self.pos_emb = self.cpb_mlp(relative_coords_table.unsqueeze(0).unsqueeze(2))
self.relative_bias = self.pos_emb
else:
seq_length = int(seq_length**0.5)
relative_coords_h = torch.arange(0, seq_length, device=input_tensor.device, dtype = input_tensor.dtype)
relative_coords_w = torch.arange(0, seq_length, device=input_tensor.device, dtype = input_tensor.dtype)
relative_coords_table = torch.stack(torch.meshgrid([relative_coords_h, relative_coords_w])).contiguous().unsqueeze(0)
relative_coords_table -= seq_length // 2
relative_coords_table /= (seq_length // 2)
if not self.conv:
self.pos_emb = self.cpb_mlp(relative_coords_table.flatten(2).transpose(1,2))
else:
self.pos_emb = self.cpb_mlp(relative_coords_table.flatten(2))
self.relative_bias = self.pos_emb
input_tensor = input_tensor + self.pos_emb
return input_tensor
class Mlp(nn.Module):
def __init__(self,
in_features,
hidden_features=None,
out_features=None,
act_layer=nn.GELU,
drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x_size = x.size()
x = x.view(-1, x_size[-1])
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
x = x.view(x_size)
return x
class Downsample(nn.Module):
def __init__(self,
dim,
keep_dim=False,
):
super().__init__()
if keep_dim:
dim_out = dim
else:
dim_out = 2 * dim
self.norm = LayerNorm2d(dim)
self.reduction = nn.Sequential(
nn.Conv2d(dim, dim_out, 3, 2, 1, bias=False),
)
def forward(self, x):
x = self.norm(x)
x = self.reduction(x)
return x
class PatchEmbed(nn.Module):
def __init__(self, in_chans=3, in_dim=64, dim=96):
super().__init__()
self.proj = nn.Identity()
self.conv_down = nn.Sequential(
nn.Conv2d(in_chans, in_dim, 3, 2, 1, bias=False),
nn.BatchNorm2d(in_dim, eps=1e-4),
nn.ReLU(),
nn.Conv2d(in_dim, dim, 3, 2, 1, bias=False),
nn.BatchNorm2d(dim, eps=1e-4),
nn.ReLU()
)
def forward(self, x):
x = self.proj(x)
x = self.conv_down(x)
return x
class ConvBlock(nn.Module):
def __init__(self, dim,
drop_path=0.,
layer_scale=None,
kernel_size=3):
super().__init__()
self.conv1 = nn.Conv2d(dim, dim, kernel_size=kernel_size, stride=1, padding=1)
self.norm1 = nn.BatchNorm2d(dim, eps=1e-5)
self.act1 = nn.GELU()
self.conv2 = nn.Conv2d(dim, dim, kernel_size=kernel_size, stride=1, padding=1)
self.norm2 = nn.BatchNorm2d(dim, eps=1e-5)
self.layer_scale = layer_scale
if layer_scale is not None and type(layer_scale) in [int, float]:
self.gamma = nn.Parameter(layer_scale * torch.ones(dim))
self.layer_scale = True
else:
self.layer_scale = False
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x, global_feature=None):
input = x
x = self.conv1(x)
x = self.norm1(x)
x = self.act1(x)
x = self.conv2(x)
x = self.norm2(x)
if self.layer_scale:
x = x * self.gamma.view(1, -1, 1, 1)
x = input + self.drop_path(x)
return x, global_feature
class WindowAttention(nn.Module):
def __init__(self,
dim,
num_heads=8,
qkv_bias=False,
qk_scale=None,
attn_drop=0.,
proj_drop=0.,
resolution=0,
seq_length=0):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
# attention positional bias
self.pos_emb_funct = PosEmbMLPSwinv2D(window_size=[resolution, resolution],
pretrained_window_size=[resolution, resolution],
num_heads=num_heads,
seq_length=seq_length)
self.resolution = resolution
def forward(self, x):
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, -1, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = self.pos_emb_funct(attn, self.resolution ** 2)
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, -1, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class HAT(nn.Module):
def __init__(self,
dim,
num_heads,
mlp_ratio=4.,
qkv_bias=False,
qk_scale=None,
drop=0.,
attn_drop=0.,
drop_path=0.,
act_layer=nn.GELU,
norm_layer=nn.LayerNorm,
sr_ratio=1.,
window_size=7,
last=False,
layer_scale=None,
ct_size=1,
do_propagation=False):
super().__init__()
# positional encoding for windowed attention tokens
self.pos_embed = PosEmbMLPSwinv1D(dim, rank=2, seq_length=window_size**2)
self.norm1 = norm_layer(dim)
# number of carrier tokens per every window
cr_tokens_per_window = ct_size**2 if sr_ratio > 1 else 0
# total number of carrier tokens
cr_tokens_total = cr_tokens_per_window*sr_ratio*sr_ratio
self.cr_window = ct_size
self.attn = WindowAttention(dim,
num_heads=num_heads,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
attn_drop=attn_drop,
proj_drop=drop,
resolution=window_size,
seq_length=window_size**2 + cr_tokens_per_window)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
self.window_size = window_size
use_layer_scale = layer_scale is not None and type(layer_scale) in [int, float]
self.gamma3 = nn.Parameter(layer_scale * torch.ones(dim)) if use_layer_scale else 1
self.gamma4 = nn.Parameter(layer_scale * torch.ones(dim)) if use_layer_scale else 1
self.sr_ratio = sr_ratio
if sr_ratio > 1:
# if do hierarchical attention, this part is for carrier tokens
self.hat_norm1 = norm_layer(dim)
self.hat_norm2 = norm_layer(dim)
self.hat_attn = WindowAttention(
dim,
num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, proj_drop=drop, resolution=int(cr_tokens_total**0.5),
seq_length=cr_tokens_total)
self.hat_mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
self.hat_drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.hat_pos_embed = PosEmbMLPSwinv1D(dim, rank=2, seq_length=cr_tokens_total)
self.gamma1 = nn.Parameter(layer_scale * torch.ones(dim)) if use_layer_scale else 1
self.gamma2 = nn.Parameter(layer_scale * torch.ones(dim)) if use_layer_scale else 1
self.upsampler = nn.Upsample(size=window_size, mode='nearest')
# keep track for the last block to explicitly add carrier tokens to feature maps
self.last = last
self.do_propagation = do_propagation
def forward(self, x, carrier_tokens):
B, T, N = x.shape
ct = carrier_tokens
x = self.pos_embed(x)
if self.sr_ratio > 1:
# do hierarchical attention via carrier tokens
# first do attention for carrier tokens
Bg, Ng, Hg = ct.shape
# ct are located quite differently
ct = ct_dewindow(ct, self.cr_window*self.sr_ratio, self.cr_window*self.sr_ratio, self.cr_window)
# positional bias for carrier tokens
ct = self.hat_pos_embed(ct)
# attention plus mlp
ct = ct + self.hat_drop_path(self.gamma1*self.hat_attn(self.hat_norm1(ct)))
ct = ct + self.hat_drop_path(self.gamma2*self.hat_mlp(self.hat_norm2(ct)))
# ct are put back to windows
ct = ct_window(ct, self.cr_window * self.sr_ratio, self.cr_window * self.sr_ratio, self.cr_window)
ct = ct.reshape(x.shape[0], -1, N)
# concatenate carrier_tokens to the windowed tokens
x = torch.cat((ct, x), dim=1)
# window attention together with carrier tokens
x = x + self.drop_path(self.gamma3*self.attn(self.norm1(x)))
x = x + self.drop_path(self.gamma4*self.mlp(self.norm2(x)))
if self.sr_ratio > 1:
# for hierarchical attention we need to split carrier tokens and window tokens back
ctr, x = x.split([x.shape[1] - self.window_size*self.window_size, self.window_size*self.window_size], dim=1)
ct = ctr.reshape(Bg, Ng, Hg) # reshape carrier tokens.
if self.last and self.do_propagation:
# propagate carrier token information into the image
ctr_image_space = ctr.transpose(1, 2).reshape(B, N, self.cr_window, self.cr_window)
x = x + self.gamma1 * self.upsampler(ctr_image_space.to(dtype=torch.float32)).flatten(2).transpose(1, 2).to(dtype=x.dtype)
return x, ct
class TokenInitializer(nn.Module):
def __init__(self,
dim,
input_resolution,
window_size,
ct_size=1):
super().__init__()
output_size = int(ct_size * input_resolution/window_size)
stride_size = int(input_resolution/output_size)
kernel_size = input_resolution - (output_size - 1) * stride_size
self.pos_embed = nn.Conv2d(dim, dim, 3, padding=1, groups=dim)
to_global_feature = nn.Sequential()
to_global_feature.add_module("pos", self.pos_embed)
to_global_feature.add_module("pool", nn.AvgPool2d(kernel_size=kernel_size, stride=stride_size))
self.to_global_feature = to_global_feature
self.window_size = ct_size
def forward(self, x):
x = self.to_global_feature(x)
B, C, H, W = x.shape
ct = x.view(B, C, H // self.window_size, self.window_size, W // self.window_size, self.window_size)
ct = ct.permute(0, 2, 4, 3, 5, 1).reshape(-1, H*W, C)
return ct
class FasterViTLayer(nn.Module):
def __init__(self,
dim,
depth,
input_resolution,
num_heads,
window_size,
ct_size=1,
conv=False,
downsample=True,
mlp_ratio=4.,
qkv_bias=True,
qk_scale=None,
drop=0.,
attn_drop=0.,
drop_path=0.,
layer_scale=None,
layer_scale_conv=None,
only_local=False,
hierarchy=True,
do_propagation=False
):
super().__init__()
self.conv = conv
self.transformer_block = False
if conv:
self.blocks = nn.ModuleList([
ConvBlock(dim=dim,
drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
layer_scale=layer_scale_conv)
for i in range(depth)])
self.transformer_block = False
else:
sr_ratio = input_resolution // window_size if not only_local else 1
self.blocks = nn.ModuleList([
HAT(dim=dim,
num_heads=num_heads,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
drop=drop,
attn_drop=attn_drop,
drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
sr_ratio=sr_ratio,
window_size=window_size,
last=(i == depth-1),
layer_scale=layer_scale,
ct_size=ct_size,
do_propagation=do_propagation,
)
for i in range(depth)])
self.transformer_block = True
self.downsample = None if not downsample else Downsample(dim=dim)
if len(self.blocks) and not only_local and input_resolution // window_size > 1 and hierarchy and not self.conv:
self.global_tokenizer = TokenInitializer(dim,
input_resolution,
window_size,
ct_size=ct_size)
self.do_gt = True
else:
self.do_gt = False
self.window_size = window_size
def forward(self, x):
ct = self.global_tokenizer(x) if self.do_gt else None
B, C, H, W = x.shape
if self.transformer_block:
x = window_partition(x, self.window_size)
for bn, blk in enumerate(self.blocks):
x, ct = blk(x, ct)
if self.transformer_block:
x = window_reverse(x, self.window_size, H, W, B)
if self.downsample is None:
return x
return self.downsample(x)
class FasterViT(nn.Module):
def __init__(self,
dim, #特征大小的维度
in_dim, #内部平面特征大小的维度
depths, #层数的深度
window_size, #窗口大小
ct_size, #载体令牌局部窗口的空间维度
mlp_ratio, #MLP的比率
num_heads, #注意头的数量
resolution=224, #图像分辨率
drop_path_rate=0.2, #drop path率
in_chans=3, #输入通道的维度
num_classes=3,
qkv_bias=True, #查询、键、值是否具有可学习的偏置
qk_scale=None, #是否对查询、键进行缩放
drop_rate=0., #dropout率
attn_drop_rate=0., #注意头dropout率
layer_scale=None, #层缩放系数
layer_scale_conv=None, #卷积层缩放系数
layer_norm_last=False, #最后一个层是否进行层归一化
hat=None, #分层注意力标志
do_propagation=False, #是否使用载体令牌传播
**kwargs):
super().__init__()
num_features = int(dim * 2 ** (len(depths) - 1))
self.num_classes = num_classes
self.patch_embed = PatchEmbed(in_chans=in_chans, in_dim=in_dim, dim=dim)
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))]
self.levels = nn.ModuleList()
if hat is None: hat = [True, ]*len(depths)
for i in range(len(depths)):
conv = True if (i == 0 or i == 1) else False
level = FasterViTLayer(dim=int(dim * 2 ** i),
depth=depths[i],
num_heads=num_heads[i],
window_size=window_size[i],
ct_size=ct_size,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
conv=conv,
drop=drop_rate,
attn_drop=attn_drop_rate,
drop_path=dpr[sum(depths[:i]):sum(depths[:i + 1])],
downsample=(i < 3),
layer_scale=layer_scale,
layer_scale_conv=layer_scale_conv,
input_resolution=int(2 ** (-2 - i) * resolution),
only_local=not hat[i],
do_propagation=do_propagation)
self.levels.append(level)
self.norm = LayerNorm2d(num_features) if layer_norm_last else nn.BatchNorm2d(num_features)
self.avgpool = nn.AdaptiveAvgPool2d(1)
#self.attention_module = TripletAttention() #添加TripletAttention模块
self.head = nn.Linear(num_features, num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, LayerNorm2d):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
@torch.jit.ignore
def no_weight_decay_keywords(self):
return {'rpb'}
def forward_features(self, x):
x = self.patch_embed(x)
for level in self.levels:
x = level(x)
x = self.norm(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
return x
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
def _load_state_dict(self,
pretrained,
strict: bool = False):
_load_checkpoint(self,
pretrained,
strict=strict)它的表现轻轻松松能上99%
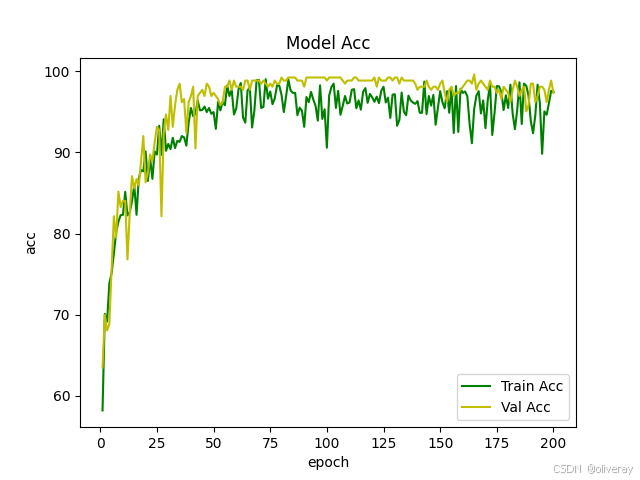
然后,以FasterViT为教师模型,我又定义了一个轻量化模型:
class StudentFasterViT(nn.Module):
def __init__(self,
dim,
in_dim,
depths,
window_size,
ct_size,
mlp_ratio,
num_heads,
resolution=224,
drop_path_rate=0.1,
in_chans=3,
num_classes=3,
qkv_bias=True,
qk_scale=None,
drop_rate=0.,
attn_drop_rate=0.,
layer_scale=None,
layer_scale_conv=None,
layer_norm_last=False,
hat=None,
do_propagation=False,
**kwargs):
super().__init__()
# 减少模型复杂度
dim = dim // 2
in_dim = in_dim // 2
depths = [d // 2 for d in depths]
num_heads = [h // 2 for h in num_heads]
num_features = int(dim * 2 ** (len(depths) - 1))
self.num_classes = num_classes
self.patch_embed = PatchEmbed(in_chans=in_chans, in_dim=in_dim, dim=dim)
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))]
self.levels = nn.ModuleList()
if hat is None: hat = [True, ] * len(depths)
for i in range(len(depths)):
conv = True if (i == 0 or i == 1) else False
level = FasterViTLayer(dim=int(dim * 2 ** i),
depth=depths[i],
num_heads=num_heads[i],
window_size=window_size[i],
ct_size=ct_size,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
conv=conv,
drop=drop_rate,
attn_drop=attn_drop_rate,
drop_path=dpr[sum(depths[:i]):sum(depths[:i + 1])],
downsample=(i < 3),
layer_scale=layer_scale,
layer_scale_conv=layer_scale_conv,
input_resolution=int(2 ** (-2 - i) * resolution),
only_local=not hat[i],
do_propagation=do_propagation)
self.levels.append(level)
self.norm = LayerNorm2d(num_features) if layer_norm_last else nn.BatchNorm2d(num_features)
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.head = nn.Linear(num_features, num_classes) if num_classes > 0 else nn.Identity()
# 添加蒸馏头
self.distillation_head = nn.Linear(num_features, num_classes)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, LayerNorm2d):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
def forward_features(self, x):
x = self.patch_embed(x)
for level in self.levels:
x = level(x)
x = self.norm(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
return x
def forward(self, x):
x = self.forward_features(x)
class_output = self.head(x)
distill_output = self.distillation_head(x)
return class_output, distill_output我们的StudentFasterViT是个聪明的学徒,设计了两个学习通道:class_output:正经做题(直接分类训练);distill_output:偷师学艺(模仿教师输出)
通过α参数平衡两种学习方式,既保证基础扎实又领悟高阶技巧
# 模型结构亮点 - 双通道学习设计
class_output, distill_output = student_model(data) # 分头学习
loss = alpha*distill_loss + (1-alpha)*ce_loss # 智慧融合然后就是训练代码:模型在精确率和召回率之间反复横跳,最终在知识蒸馏的调和下找到平衡点
from models.faster_vit import StudentFasterViT
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from sklearn.metrics import precision_score, recall_score, f1_score
import matplotlib.pyplot as plt
import seaborn as sns
def calculate_accuracy(outputs, targets):
_, predicted = torch.max(outputs.data, 1)
total = targets.size(0)
correct = (predicted == targets).sum().item()
return correct / total
def main():
# 加载教师模型
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
teacher_model = torch.load('best.pth', map_location=DEVICE)
teacher_model.eval()
# 使用示例
student_model = StudentFasterViT(dim=32, in_dim=16, depths=[2, 2, 4, 2], num_heads=[1, 2, 4, 8],
window_size=[7, 7, 7, 7], ct_size=1, mlp_ratio=2).to((DEVICE))
# print(student_model)
# 定义损失函数
criterion = nn.KLDivLoss(reduction='batchmean')
ce_loss = nn.CrossEntropyLoss()
# 定义优化器
optimizer = optim.AdamW(student_model.parameters(), lr=0.001)
# 数据预处理
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
# 加载数据集
train_dataset = datasets.ImageFolder('dataset/train', transform=transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True, num_workers=4)
val_dataset = datasets.ImageFolder('dataset/val', transform=transform)
val_loader = DataLoader(val_dataset, batch_size=64, shuffle=False, num_workers=4)
def train(epoch, dataloader):
student_model.train()
total_loss = 0
correct = 0
total = 0
for batch_idx, (data, target) in enumerate(dataloader):
data, target = data.to(DEVICE), target.to(DEVICE)
optimizer.zero_grad()
# 前向传播
class_output, distill_output = student_model(data)
with torch.no_grad():
teacher_output = teacher_model(data)
# 计算损失
distillation_loss = criterion(F.log_softmax(distill_output / T, dim=1),
F.softmax(teacher_output / T, dim=1))
student_loss = ce_loss(class_output, target)
loss = alpha * distillation_loss + (1 - alpha) * student_loss
# 反向传播
loss.backward()
optimizer.step()
# 计算准确率
_, predicted = torch.max(class_output.data, 1)
total += target.size(0)
correct += (predicted == target).sum().item()
total_loss += loss.item()
avg_loss = total_loss / len(dataloader)
avg_acc = correct / total
print(f'Epoch: {epoch}, Avg Loss: {avg_loss:.4f}, Avg Acc: {avg_acc:.4f}')
return avg_loss, avg_acc
def validate(dataloader):
student_model.eval()
val_loss = 0
all_predictions = []
all_targets = []
with torch.no_grad():
for data, target in dataloader:
data, target = data.to(DEVICE), target.to(DEVICE)
class_output, _ = student_model(data)
val_loss += ce_loss(class_output, target).item()
_, predicted = torch.max(class_output.data, 1)
all_predictions.extend(predicted.cpu().numpy())
all_targets.extend(target.cpu().numpy())
avg_val_loss = val_loss / len(dataloader)
# 计算各种指标
accuracy = sum(p == t for p, t in zip(all_predictions, all_targets)) / len(all_targets)
precision = precision_score(all_targets, all_predictions, average='weighted')
recall = recall_score(all_targets, all_predictions, average='weighted')
f1 = f1_score(all_targets, all_predictions, average='weighted')
print(f'Validation Loss: {avg_val_loss:.4f}')
print(f'Accuracy: {accuracy:.4f}')
print(f'Precision: {precision:.4f}')
print(f'Recall: {recall:.4f}')
print(f'F1 Score: {f1:.4f}')
return accuracy, precision, recall, f1
# 设置超参数
T = 4 # 温度参数
alpha = 0.5 # 平衡蒸馏损失和学生损失的权重
# 初始化用于存储指标的列表
train_losses = []
train_accs = []
val_accs = []
val_f1s = []
epochs = []
# 训练循环
num_epochs = 100
best_val_f1 = 0
for epoch in range(1, num_epochs + 1):
train_loss, train_acc = train(epoch, train_loader)
val_acc, val_precision, val_recall, val_f1 = validate(val_loader)
print(f'Epoch {epoch}: Train Acc: {train_acc:.4f}, Val Acc: {val_acc:.4f}, Val F1: {val_f1:.4f}')
# 保存最佳模型(这里我们使用F1分数作为标准)
if val_f1 > best_val_f1:
best_val_f1 = val_f1
torch.save(student_model.state_dict(), 'best_lighter_student_model_new.pth')
# 存储指标
train_losses.append(train_loss)
train_accs.append(train_acc)
val_accs.append(val_acc)
val_f1s.append(val_f1)
epochs.append(epoch)
print(f'Best validation F1 score: {best_val_f1:.4f}')
# 绘制训练曲线
sns.set_style("whitegrid")
plt.figure(figsize=(12, 8))
plt.subplot(2, 2, 1)
sns.lineplot(x=epochs, y=train_losses, marker='o')
plt.title('Training Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.subplot(2, 2, 2)
sns.lineplot(x=epochs, y=train_accs, marker='o', label='Train Accuracy')
sns.lineplot(x=epochs, y=val_accs, marker='o', label='Validation Accuracy')
plt.title('Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.subplot(2, 2, 3)
sns.lineplot(x=epochs, y=val_f1s, marker='o')
plt.title('Validation F1 Score')
plt.xlabel('Epoch')
plt.ylabel('F1 Score')
plt.tight_layout()
plt.savefig('training_curves.png', dpi=300)
plt.show()
if __name__ == '__main__':
main()学生模型的表现也可以近似复现出教师模型的准确率,但是学生模型所占用的计算资源和内存确实大大减少了,更容易完成小成本的识别任务和边缘系统的部署。
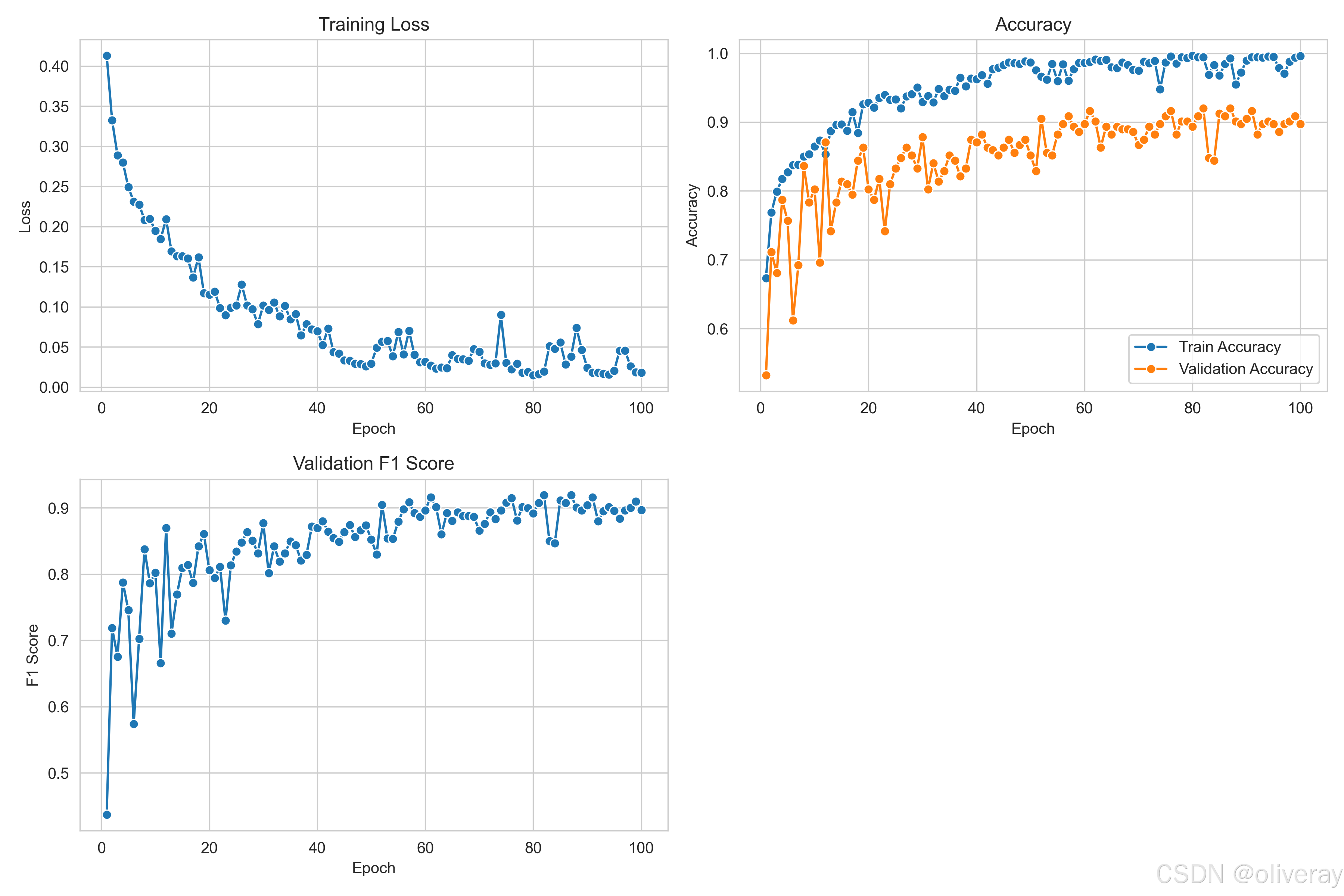
同样的,这种方法几乎可以训练出各种轻量性模型出来,那么,知识蒸馏的好处是什么,为什么定义了一个小的学生模型不能直接训练它,而是要学教师模型呢
知识蒸馏的主要好处在于能够将一个大而复杂的教师模型的知识迁移到一个较小的学生模型中,从而在保持相对高准确率的同时大大降低模型的复杂性和计算成本。直接训练一个小的学生模型往往难以达到教师模型的性能,因为小模型在直接训练过程中可能会忽略或难以捕捉到数据中的复杂模式和信息。而通过知识蒸馏,学生模型不仅仅是从训练数据中学习,还能够从教师模型输出的软标签(即概率分布)中学习,这些软标签包含了更多的关于类别之间相似性的信息,使学生模型能够更好地泛化和捕捉数据中的细微差别。因此,知识蒸馏能够有效地提升小模型的性能,接近于大模型的效果,同时保持较低的计算和存储需求。
三、总结
知识蒸馏中的重要概念:
软标签:教师模型输出的概率分布比硬标签(即标准的0和1标记)更丰富,包含了类别之间的相似度。学生模型通过学习这些软标签,能够理解类别之间的关系和模型决策的细节,从而帮助它更好地泛化。
温度系数:在知识蒸馏过程中,使用温度参数来调整教师模型的输出概率分布的平滑度。较高的温度使得教师模型的输出概率分布更加平滑,从而帮助学生模型学习到更多的类别间的微妙信息。这个温度系数常常在模型蒸馏中调节,以便让学生模型更容易从教师模型中获取有用的知识。
损失函数:知识蒸馏的损失函数通常结合了学生模型在目标任务上的损失(交叉熵损失)与学生模型与教师模型输出之间的差异(KL散度)。通过平衡这两部分损失,学生模型可以既学习到标注数据的标准知识,又能吸收教师模型的经验。
学生模型的性能提升:即使学生模型较小,但通过蒸馏过程,学生模型能够学到更有信息量的表示,弥补其结构上的限制,提升其泛化能力。这使得知识蒸馏在边缘设备和实时应用中非常有用,因为它可以显著减少模型的大小和计算量。


















 3641
3641

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









