




 这篇博客分享了多个关于DataFrame的操作技巧,包括属性行获取、数据合并、删除空值和重复行、列类型转换、选择特定数值、计算距离、条件删除行、Spark数据处理、数据保存、分组运算、列转换、数据可视化以及根据条件过滤数据等。
这篇博客分享了多个关于DataFrame的操作技巧,包括属性行获取、数据合并、删除空值和重复行、列类型转换、选择特定数值、计算距离、条件删除行、Spark数据处理、数据保存、分组运算、列转换、数据可视化以及根据条件过滤数据等。
1、获取属性行
id_list=df.columns.values.tolist()
2、两个dataframe合并,之后可以删除有空值的行,或者删除有重复的行
df3=pd.merge(df1,df2,how='left',on=['id'])
norepeat_df = df3.drop_duplicates(subset=['id'], keep='first')
nonan_df = norepeat_df.dropna(axis=0, how='any')
3、object列转变为int64
df['id'] = df['id'].astype('int')
4、选择某个index行某个列对应的数值
df.loc[2511531]['lng']
5、两个相同的dataframe合并,依次计算目标值
for i in df_final.index.values:
for j in df_final.index.values:
dis=geodesic((df_final.loc[i]['center_lat'], df_final.loc[i]['center_lng']), (df_final.loc[j]['center_lat'], df_final.loc[j]['center_lng'])).km
line1.append(i)
line2.append(j)
line3.append(dis)
6、删除满足特定条件的行
df = df.drop(df[(df.score < 50) & (df.score > 20)].index)
7、pyspark取数,保存为dataframe
导入相关的包
启动spark
sql='''sql语句'''
df1 = spark.sql(sql).toPandas()
8、将list存入txt,并以逗号分割
file = open("./park_ids.txt",'a')
for i in range(len(park_id_list)):
s = str(park_id_list[i]).replace('[','').replace(']','')#去除[],这两行按数据不同,可以选择
s = s.replace("'",'')+"," #去除单引号,每行末尾追加逗号
file.write(s)
file.close()
9、groupby之后对每个分组中的两列做运算(比如求rmse、mape等)
数据长这样,目的是以city_id为分组依据,计算每个分组的in_list in_cnt之间的rmse
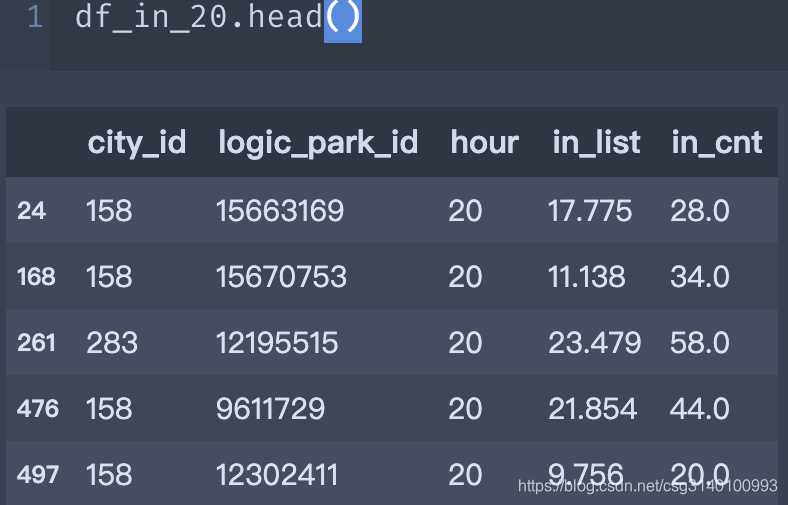
主要依据就是每个分组其实都可以按照一个dataframe来操作,遍历每个分组即可,本来想用transform或者apply来操作的,但是搞了半天没搞明白就放弃了,选择了这种写起来麻烦但是很容易理解的方式
def compute_rmse(list1,list2):
data={"a":list1,"b":list2}
datafr=pd.DataFrame(data)
datafr["er"]=abs((datafr["a"]-datafr["b"]))**2
return (datafr["er"].mean())**0.5
def compute_mape(list1,list2):#list1为真实值,真实值不能为0
data={"a":list1,"b":list2}
datafr=pd.DataFrame(data)
datafr["er"]=abs(((datafr["a"]-datafr["b"]))/datafr["a"])
return (datafr["er"].mean())*100
city_id_list_20=df_in_20.city_id.unique()
print(len(city_id_list))
rmse_in_20=[]
for i in city_id_list_20:
i=int(i)
tmp=df_in_20.groupby(['city_id']).get_group(i)
rmse_in_20.append(compute_rmse(tmp.in_cnt,tmp.in_list))
df_in_rmse_20=pd.DataFrame({"city_id":city_id_list_20,"rmse_20":rmse_in_20})
df_in_rmse_20.head()
df_in_rmse_20.to_csv("./df_in_rmse_20.csv",index=None)
10、将dataframe中的某一列数据转为float或者int64
import pandas as pd
df1['out_list'] = pd.to_numeric(df1['out_list'])#float
df1["hour"]=df1["hour"].values.astype(int)#int64
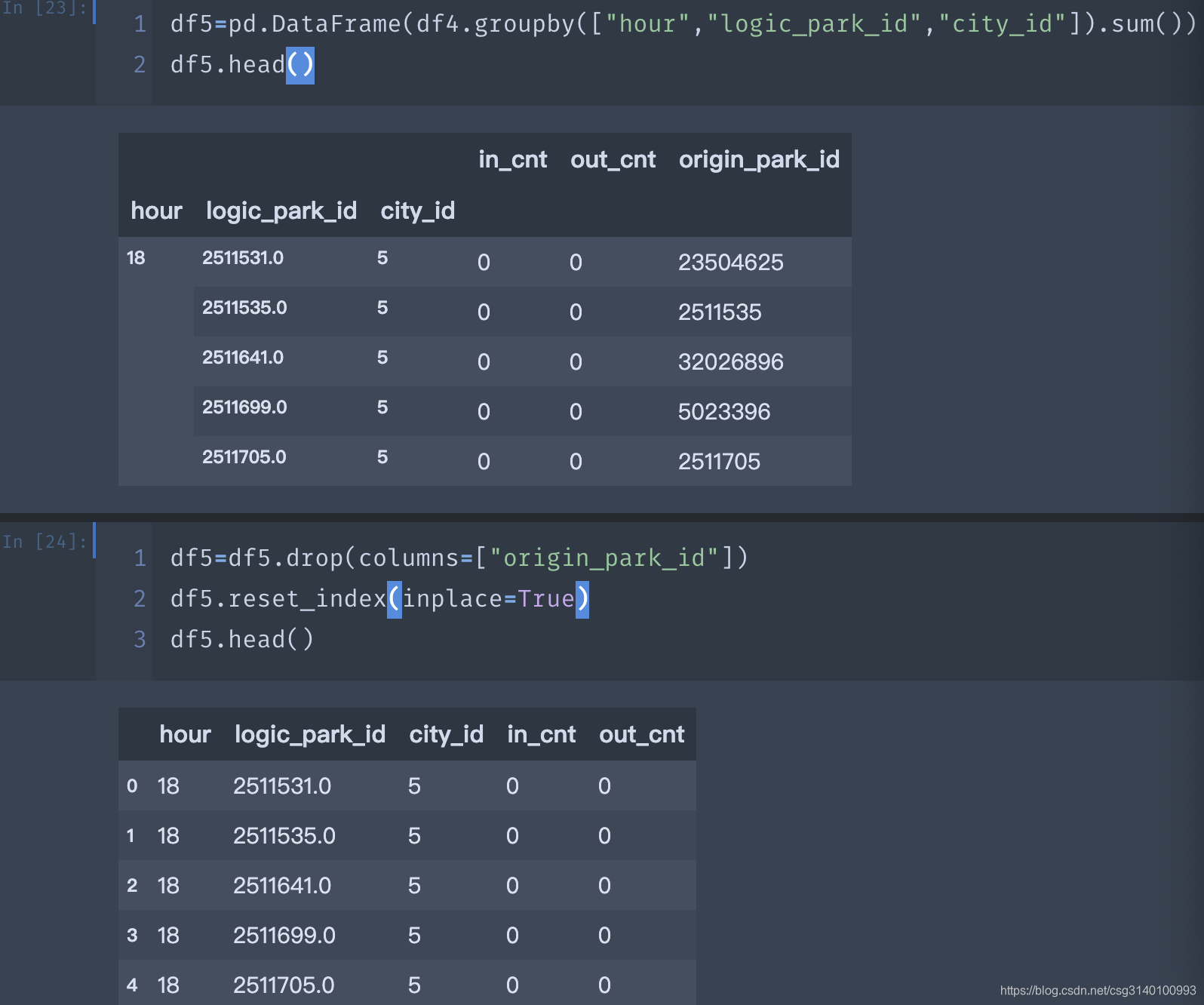
11、分组之后求每个分组的和(其实和8相比主要区别在于这里是对单列操作,8是对双列或者多列操作)
df5=pd.DataFrame(df4.groupby(["hour","logic_park_id","city_id"]).sum())
df5.head()
df5=df5.drop(columns=["origin_park_id"])
df5.reset_index(inplace=True)
df5.head()
12、删除df.ts_code大于等于"500000"且小于"600000"的所有行
df = df.drop(df[(df.ts_code >= "500000") & (df.ts_code < "600000")].index)
13、将dataframe的某一列转为datetime类型,并作差之后和实数作比较
import pandas as pd
df["op_time"]=pd.to_datetime(df["op_time"])
df["recommend_time"]=pd.to_datetime(df["recommend_time"])
df=df.drop(df[((df["op_time"]-df["recommend_time"])/np.timedelta64(1, "D")>1/12)|((df["op_time"]-df["recommend_time"])/np.timedelta64(1, "D")<0)].index)
df.head()
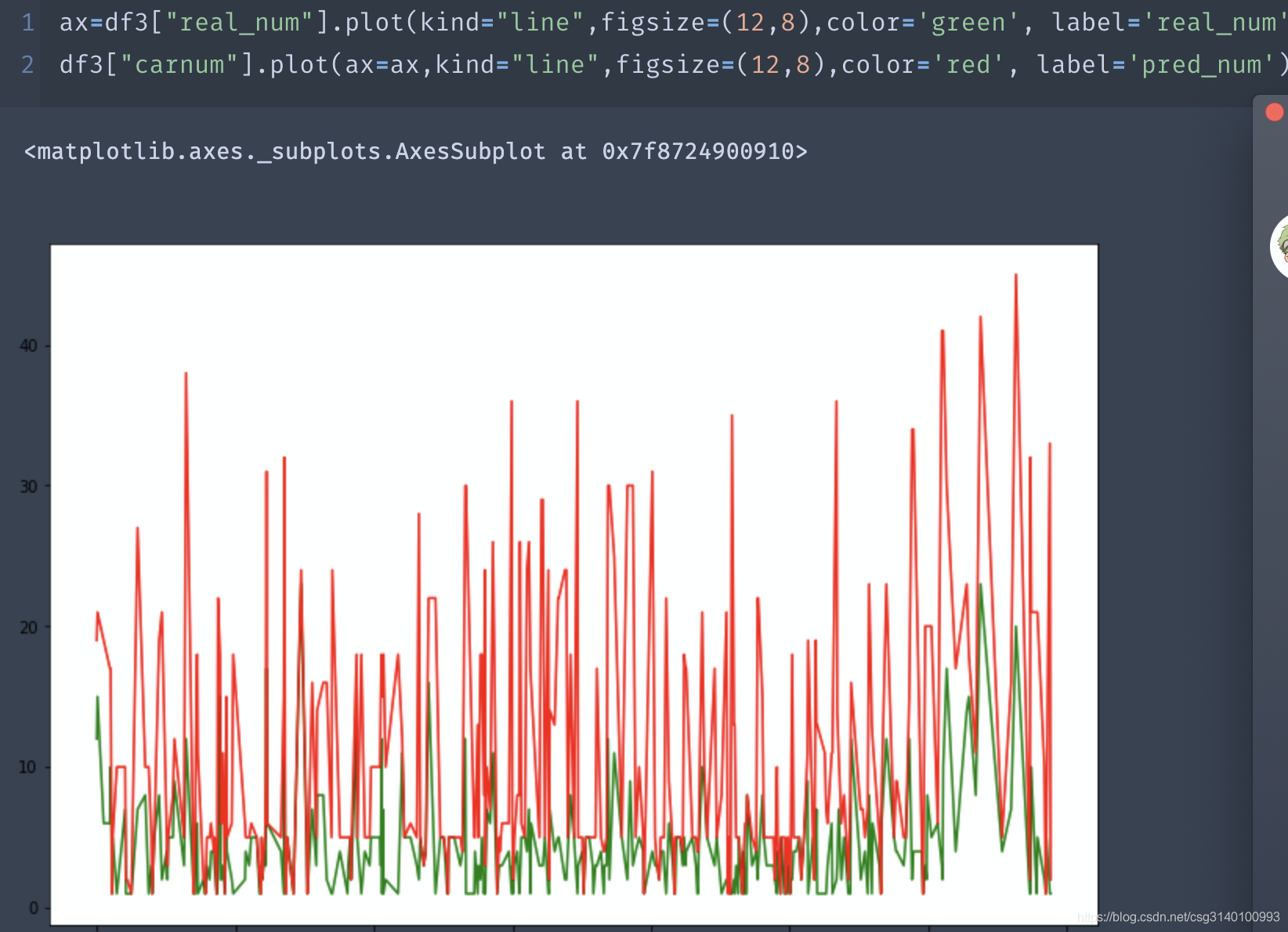
14、对dataframe某一列做折线图
15、groupby之后按照group进行绘图
ax=df8.groupby(["pt"]).get_group("2020-06-30").plot(x="put_park_id",y="active_data",kind="line",figsize=(12,8),color='green', label='2020-06-30')
df8.groupby(["pt"]).get_group("2020-07-01").plot(x="put_park_id",y="active_data",kind="line",ax=ax,figsize=(12,8),color='red', label='2020-07-01')
16、groupby之后对每个group求均值,并将均值赋给新列
def mean_time(group):
group['link_ID_en'] = group['travel_time'].mean()
return group
df = df.groupby('link_ID').apply(mean_time)
df.head()
| link_ID | time_interval_begin | travel_time | date | length | width | link_class | in_links | out_links | links_num | area | link_ID_en | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 4377906289869500514 | 2017-04-01 06:00:00 | 1.026672 | 2017-04-01 | 57 | 3 | 1 | 1.0 | 1.0 | 1.0,1.0 | 171 | 1.117642 |
| 1 | 4377906289869500514 | 2017-04-01 06:02:00 | 1.026672 | 2017-04-01 | 57 | 3 | 1 | 1.0 | 1.0 | 1.0,1.0 | 171 | 1.117642 |
| 2 | 4377906289869500514 | 2017-04-01 06:04:00 | 1.014454 | 2017-04-01 | 57 | 3 | 1 | 1.0 | 1.0 | 1.0,1.0 | 171 | 1.117642 |
| 3 | 4377906289869500514 | 2017-04-01 06:06:00 | 1.014454 | 2017-04-01 | 57 | 3 | 1 | 1.0 | 1.0 | 1.0,1.0 | 171 | 1.117642 |
| 4 | 4377906289869500514 | 2017-04-01 06:08:00 | 1.014454 | 2017-04-01 | 57 | 3 | 1 | 1.0 | 1.0 | 1.0,1.0 | 171 | 1.117642 |
17、删除不想要的行
nonan_df=nonan_df.drop(nonan_df[~nonan_df["group_id"].isin(df1["group_id"])].index)
18、合并分组
df_test=pd.DataFrame({"park_id":[],"pt":[],"out_cnt":[]})
for i in park_id_list:
if df3.groupby('park_id').get_group(i).out_cnt.sum()>10:
df_test=df_test.append(df3.groupby('park_id').get_group(i))

















 761
761

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









