




 本文详细介绍了Python Numpy库中的数组变形操作,包括重塑、打平、翻转数组、连接数组、分割数组以及添加和删除数组元素。通过实例展示了reshape、resize、ravel、flatten、transpose、swapaxes、concatenate、split、hstack、vstack、dstack等功能,以及如何使用r_和c_对象进行数组合并。此外,文章还涵盖了数组的计算,如元素级别的加减乘除、线性代数运算,以及广播机制在不同形状数组运算中的应用。
本文详细介绍了Python Numpy库中的数组变形操作,包括重塑、打平、翻转数组、连接数组、分割数组以及添加和删除数组元素。通过实例展示了reshape、resize、ravel、flatten、transpose、swapaxes、concatenate、split、hstack、vstack、dstack等功能,以及如何使用r_和c_对象进行数组合并。此外,文章还涵盖了数组的计算,如元素级别的加减乘除、线性代数运算,以及广播机制在不同形状数组运算中的应用。
一、数组的变形
1、修改数组的形状
(1)、重塑
重塑顾名思义就是将重新塑造数组的形状,即改变数组的维度。***np.reshape***函数和***np.resize***两个函数都可以实现这一点。
np.reshape在不改变数据的条件下修改形状,以下是它的定义:
- numpy.reshape(arr, newshape, order=‘C’)
| 参数 | 说明 |
|---|---|
| arr | 要修改形状的数组 |
| newshape | 整数或者整数数组,新的形状应当兼容原有形状 |
| order | ‘C’ – 按行主序,‘F’ – 按列主序,‘A’ – 原顺序,‘k’ – 元素在内存中的出现顺序。 |
例如下面将一维数组变为二维数组:
import numpy as np
x=np.arange(16)
print(x)
y = x.reshape(4,4)
print(y)
[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15]
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]
[12 13 14 15]]
当数组元素很多的时候或者该数组是高维数组时,当我们确定其他维的元素个数但是不想计算最后一个维度元素的个数,我们可以用**-1**来来取代。例如我把x重塑为(2,6)的形状,可以写作(2,-1):
y = x.reshape(2,-1)
print(y)
[[ 0 1 2 3 4 5 6 7]
[ 8 9 10 11 12 13 14 15]]
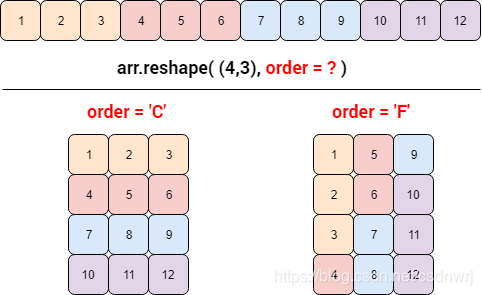
针对于第三个参数的含义,我们先来看个例子:
x=np.arange(12)
print(x)
y1 = x.reshape((4,3))
print("y1 = \n{}".format(y1))
y2 = x.reshape((4,3),order = 'F')
print("y2 = \n{}".format(y2))
[ 0 1 2 3 4 5 6 7 8 9 10 11]
y1 =
[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]]
y2 =
[[ 0 4 8]
[ 1 5 9]
[ 2 6 10]
[ 3 7 11]]
通过上面我们可以发现设定行为主序和列为主序两种情况得到的数组是不一样的。
行主序指每行的元素在内存块中彼此相邻,而列主序指每列的元素在内存块中彼此相邻。在众多计算机语言中,
- 默认行主序的有 C 语言(下图 order=‘C’ 等价于行主序)
- 默认列主序的有 Fortran 语言(下图 order=‘F’ 等价于列主序)
np.resize函数会返回指定形状的新数组,其定义如下:
- numpy.resize(arr, shape)
| 参数 | 说明 |
|---|---|
| arr | 要修改大小的数组 |
| shape | 返回数组的新形状 |
np.reshape函数与np.resize函数最大的区别就在于np.resize函数没有复制原数组(即完成操作后原数组改变),np.reshape函数复制了原数组(即完成操作后原数组不发生改变)。下面用代码验证一下:
import numpy as np
x=np.arange(16)
print(x)
y = x.reshape((4,4))
print(x)
z = x.resize((4,4))
print(x)
[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15]
[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15]
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]
[12 13 14 15]]
(2)、打平
打平数组顾名思义就是将多维数组变成一维数组。 ***np.ravel***函数或***np.flatten***方法可以实现这一点。下面是这两个函数的定义:
- ndarray.flatten(order=‘C’)
- numpy.ravel(a, order=‘C’)
例如:
a = np.arange(8).reshape(2,4)
print(a)
print(a.flatten())
print(np.ravel(a))
[[0 1 2 3]
[4 5 6 7]]
[0 1 2 3 4 5 6 7]
[0 1 2 3 4 5 6 7]
这二者的区别是:
- np.flatten方法返回的是原数组的一个复制,修改数组元素不会改变原数组
- np.ravel函数返回的是原数组的一个视图,修改数组元素会改变原数组
就拿上面的例子来说:
b = a.flatten()
b[0]=10
print(a)
c = np.ravel(a)
c[0]=10
print(a)
[[0 1 2 3]
[4 5 6 7]]
[[10 1 2 3]
[ 4 5 6 7]]
从结果我们可以看到当我们修改b数组的第一个元素值,a数组第一个元素值不改变。但是修改c数组第一个元素值a数组第一个元素值发生了改变。
2、翻转数组
(1)转置
在线性代数里面有矩阵的转置,在ndarray数组中也有相关的转置操作。其定义是:ndarray.T
例如:
a = np.arange(8).reshape(2,4)
print(a)
print(a.T)
[[0 1 2 3]
[4 5 6 7]]
[[0 4]
[1 5]
[2 6]
[3 7]]
(2)对换数组的维度
如果是多维数组中我想交换任意两个维度的顺序,或者将多个维度的顺序全部打乱,那么简单的转置并不能完成这一操作,这时候就要使用***np.transpose***方法,其定义如下:
- numpy.ndarray.transpose(axes)
| 参数 | 说明 |
|---|---|
| axes | 整数列表,列表中的数字顺序对应维度顺序 |
例如:现在有一个维度为(2,3,5)的数组,将数组的维度顺序变为2,3,1,即原来的第一维度变为第三维度,原来的第二维度变为第一维度,原来的第三维度变为第二维度:
a = np.arange(30).reshape(2,3,5)
print("原数组为:\n{}".format(a))
print("改变后的数组为:\n{}".format(a.transpose(1,2,0)))
原数组为:
[[[ 0 1 2 3 4]
[ 5 6 7 8 9]
[10 11 12 13 14]]
[[15 16 17 18 19]
[20 21 22 23 24]
[25 26 27 28 29]]]
改变后的数组为:
[[[ 0 15]
[ 1 16]
[ 2 17]
[ 3 18]
[ 4 19]]
[[ 5 20]
[ 6 21]
[ 7 22]
[ 8 23]
[ 9 24]]
[[10 25]
[11 26]
[12 27]
[13 28]
[14 29]]]
由于维度的改变,元素的坐标也发生改变。如果元素原来的坐标是(i,j,k),那么现在的坐标为(j,k,i)。
(3)对换数组的两个维度
如果我仅仅想对换数组的两个维度的顺序,那么就可以使用np.wapaxes函数,就不必设置所有维度的顺序了,其定义如下:
- numpy.swapaxes(arr, axis1, axis2)
| 参数 | 说明 |
|---|---|
| arr | 输入的数组 |
| axis1 | 对应第一个轴的整数 |
| axis2 | 对应第二个轴的整数 |
例如:我想交换维度为(2,3,5)的数组的第一和第二维度:
a = np.arange(30).reshape(2,3,5)
print("原数组为:\n{}".format(a))
print("改变后的数组为:\n{}".format(np.swapaxes(a,0,1)))
原数组为:
[[[ 0 1 2 3 4]
[ 5 6 7 8 9]
[10 11 12 13 14]]
[[15 16 17 18 19]
[20 21 22 23 24]
[25 26 27 28 29]]]
改变后的数组为:
[[[ 0 1 2 3 4]
[15 16 17 18 19]]
[[ 5 6 7 8 9]
[20 21 22 23 24]]
[[10 11 12 13 14]
[25 26 27 28 29]]]
如果原来的元素坐标为(i,j,k),那么变换后的坐标为(j,i,k)。
3、连接数组
(1)np.concatenate函数
np.concatenate函数可以说是通用的连接函数,因为它可以沿任意的现有轴进行连接数组。下面是其定义:
- numpy.concatenate((a1, a2, …), axis)
| 参数 | 说明 |
|---|---|
| a1, a2, … | 相同类型的数组 |
| axis | 沿着它连接数组的轴,默认为 0 |
例如下面分别对两个数组进行竖直方向(沿轴0)与水平方向(沿轴1)合并:
a = np.array([[1,2],[3,4]])
b = np.array([[5,6],[7,8]])
print ('a = \n{}'.format(a))
print ('b = \n{}'.format(b))
print ('沿轴 0 连接两个数组:')
print (np.concatenate((a,b)))
print ('沿轴 1 连接两个数组:')
print (np.concatenate((a,b),axis = 1))
a =
[[1 2]
[3 4]]
b =
[[5 6]
[7 8]]
沿轴 0 连接两个数组:
[[1 2]
[3 4]
[5 6]
[7 8]]
沿轴 1 连接两个数组:
[[1 2 5 6]
[3 4 7 8]]
(2)vstack, hstack, dstack函数
通用的东西虽然好,但是效率不高,NumPy 里还有专门合并的函数:
- np.vstack:v 代表 vertical,竖直合并,等价于 concatenate(axis=0)
- np.hstack:h 代表 horizontal,水平合并,等价于 concatenate(axis=1)
- np.dstack:d 代表 depth-wise,按深度合并,可以理解为增加维度
下面是这三个函数的图示:
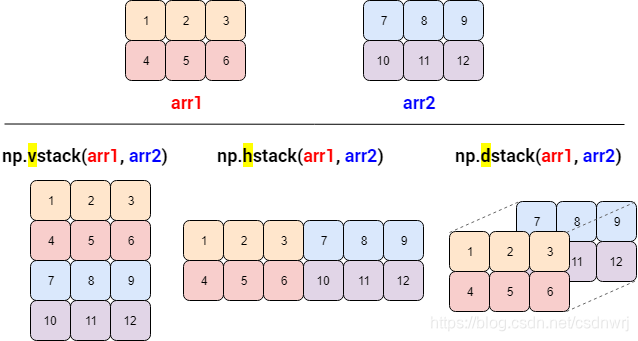
下面用代码验证一下:
print( np.vstack((a, b)) )
print( np.hstack((a, b)) )
print( np.dstack((a, b)) )
[[1 2]
[3 4]
[5 6]
[7 8]]
--------------
[[1 2 5 6]
[3 4 7 8]]
--------------
[[[1 5]
[2 6]]
[[3 7]
[4 8]]]
(3)r_, c_对象
还有一种更简单的在竖直和水平方向合并的函数方法,使用np.r_和 np.c_对象。
它们可以像vstack, hstack函数一样做简单的合并:
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
c = np.c_[a,b]
print(np.r_[a,b])
print(c)
print(np.c_[c,a])
[1 2 3 4 5 6]
----------------
[[1 4]
[2 5]
[3 6]]
----------------
[[1 4 1]
[2 5 2]
[3 6 3]]
**注意:np.r_和 np.c_的参数用[]括起来,不是()。**因为np.r_和 np.c_本质上是将多个序列或数组合并成一个数组并返回,它们实际上是数组对象并不是函数。
如果np.r_和 np.c_仅有这个功能那么就完全和 vstack和hstack一样了就没有存在的必要了,所以下面介绍它们的特别用法:
- 参数可以是切片。
print( np.r_[-2:2:1, [0]*3, 5, 6] )
[-2 -1 0 1 0 0 0 5 6]
- 第一个参数可以是控制参数,如果它用 ‘r’ 或 ‘c’ 字符可生成线性代数最常用的矩阵 matrix (和二维 numpy array 稍微有些不同,在后面会详细介绍)
a = np.r_['r', [1,2,3], [4,5,6]]
print(a,type(a))
[[1 2 3 4 5 6]] <class 'numpy.matrix'>
- 第一个参数可以是控制参数,如果它写成 ‘a,b,c’ 的形式,其中
- a:代表轴,按「轴 a」来合并
- b:合并后数组维度至少是 b
- c:在第 c 维上做维度提升
这么说可能有些抽象,那么用代码看一看具体的例子:
print( np.r_['0,2,0', [1,2,3], [4,5,6]] )
print( np.r_['0,2,1', [1,2,3], [4,5,6]] )
print( np.r_['1,2,0', [1,2,3], [4,5,6]] )
print( np.r_['1,2,1', [1,2,3], [4,5,6]] )
print( np.r_['1,3,1', [1,2,3], [4,5,6]] )
[[1]
[2]
[3]
[4]
[5]
[6]]
-----------------
[[1 2 3]
[4 5 6]]
-----------------
[[1 4]
[2 5]
[3 6]]
------------------
[[1 2 3 4 5 6]]
-------------------
[[[1]
[2]
[3]
[4]
[5]
[6]]]
首先我们来看b参数的含义,通过上面的例子显而易见b参数决定了数组的维数,b = 2,那么最后得到的数组为二维数组。b = 3,那么最后得到的数组为三维数组。
然后我们再来看c参数,它的定义为:在第 c 维上做维度提升。如果b = 2,因为两个数组 [1,2,3], [4,5,6] 都是一维,所以:
- c = 0 代表在轴 0(列)上升一维,因此得到 [[1],[2],[3]] 和 [[4],[5],[6]]
- c = 1 代表在轴 1(行)上升一维,因此得到 [[1,2,3]] 和 [[4,5,6]]
如果b = 3:
- c = 0 代表在轴 0 上升两维,因此得到 [[[1]],[[2]],[[3]]] 和 [[[4]],[[5]],[[6]]]
- c = 1 代表在轴 1(列)上升两维,因此得到 [[[1],[2],[3]]] 和 [[[4],[5],[6]]]
- c = 2 代表在轴 2(行)上升两维,因此得到 [[[1,2,3]]] 和 [[[4,5,6]]]
最后我们来看参数a,以b = 2为例:
- a = 0, 沿着轴 0(列)合并
- a = 1, 沿着轴 1(行)合并
下面是 b = 2 时的过程图:
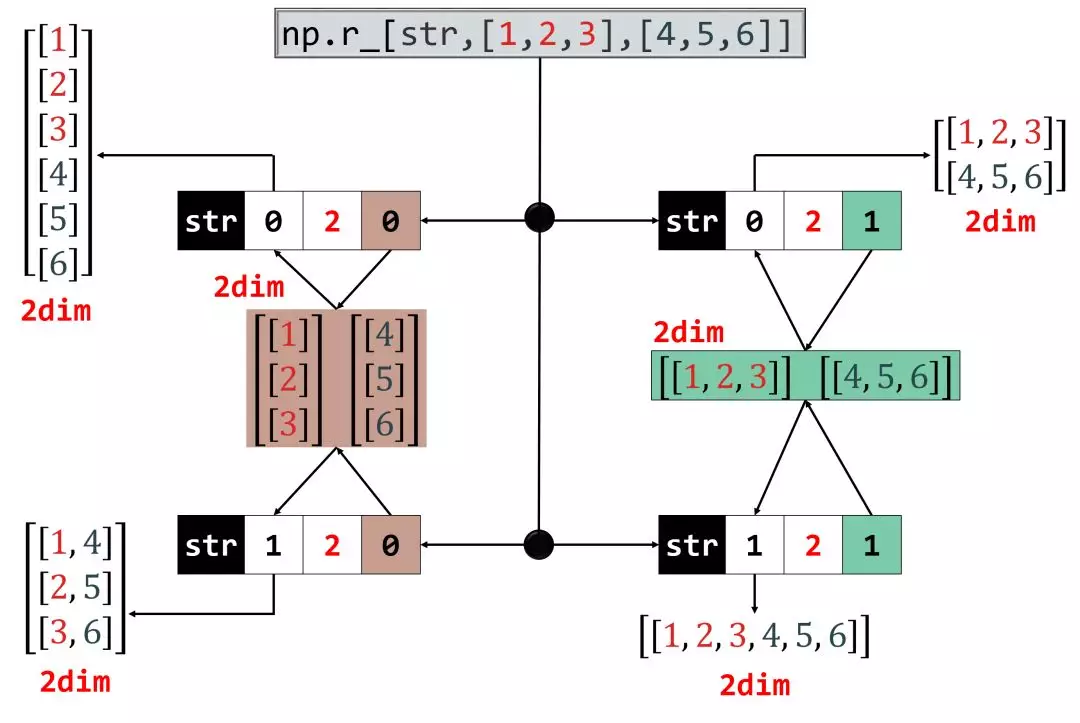
4、分割数组
(1)np.split函数
和 concatenate() 函数一样,我们可以在 split() 函数里通过设定轴,来对数组沿着竖直方向分裂 (轴 0) 和沿着水平方向分裂 (轴 1)。下面是它的定义:
- numpy.split(ary, indices_or_sections, axis)
| 参数 | 说明 |
|---|---|
| ary | 被分割的数组 |
| indices_or_sections | 如果是一个整数,就用该数平均切分,如果是一个数组,为沿轴切分的位置 |
| axis | 沿着哪个维度进行切向,默认为0,横向切分。为1时,纵向切分 |
a = np.arange(9)
print ('第一个数组:')
print (a)
print ('将数组分为三个大小相等的子数组:')
b = np.split(a,3)
print (b)
print ('将数组在一维数组中表明的位置分割:')
b = np.split(a,[4,7])
print (b)
第一个数组:
[0 1 2 3 4 5 6 7 8]
将数组分为三个大小相等的子数组:
[array([0, 1, 2]), array([3, 4, 5]), array([6, 7, 8])]
将数组在一维数组中表明的位置分割:
[array([0, 1, 2, 3]), array([4, 5, 6]), array([7, 8])]
其中第三步操作中的第二个参数 [4, 7] 相当于是个切片操作,将数组分成三部分:
- 第一部分 - 0:3
- 第二部分 - 4:6
- 第二部分 - 6:8
(2)np.hsplit, np.vsplit函数
vsplit() 和 split(axis=0) 等价,hsplit() 和 split(axis=1) 等价。下面是图示:
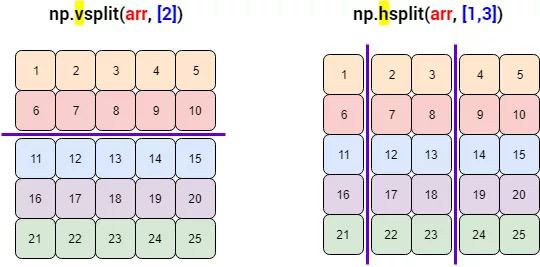
下面用代码展示一下np.hsplit函数:
a = np.arange(25).reshape((5,5))
first, second, third = np.hsplit(a,[1,3])
print( '第一个数组是:\n{}'.format(first) )
print( '第二个数组是:\n{}'.format(second) )
print( '第三个数组是:\n{}'.format(third) )
第一个数组是:
[[ 0]
[ 5]
[15]
[20]]
第二个数组是:
[[ 1 2]
[ 6 7]
[11 12]
[16 17]
[21 22]]
第三个数组是:
[[ 3 4]
[ 8 9]
[13 14]
[18 19]
[23 24]]
5、添加和删除数组元素
(1)添加
添加数组元素主要有两个函数:np.append和np.insert函数。他们的区别是:
- np.append 函数在数组的末尾插入元素
- np.insert 函数在某个特定位置之前插入元素
np.append 函数在数组的末尾添加值。 追加操作会分配整个数组,并把原来的数组复制到新数组中。此外,输入数组的维度必须匹配否则将生成ValueError。下面是函数定义:
- numpy.append(arr, values, axis=None)
| 参数 | 说明 |
|---|---|
| arr | 输入数组 |
| values | 要向arr添加的值,需要和arr形状相同(除了要添加的轴) |
| axis | 默认为 None。当axis无定义时,是横向加成,返回总是为一维数组!当axis有定义的时候,分别为0和1的时候。当axis有定义的时候,分别为0和1的时候(列数要相同)。当axis为1时,数组是加在右边(行数要相同)。 |
例如:
a = np.array([[1,2,3],[4,5,6]])
print ('第一个数组:')
print (a)
print ('向数组添加元素:')
print (np.append(a, [7,8,9]))
print ('沿轴 0 添加元素:')
print (np.append(a, [[7,8,9]],axis = 0))
print ('沿轴 1 添加元素:')
print (np.append(a, [[5,5,5],[7,8,9]],axis = 1))
第一个数组:
[[1 2 3]
[4 5 6]]
向数组添加元素:
[1 2 3 4 5 6 7 8 9]
沿轴 0 添加元素:
[[1 2 3]
[4 5 6]
[7 8 9]]
沿轴 1 添加元素:
[[1 2 3 5 5 5]
[4 5 6 7 8 9]]
numpy.insert 函数在给定索引之前,沿给定轴在输入数组中插入值。如果值的类型转换为要插入,则它会广播(广播在下面数组的计算会详细说明)输入的值数组来匹配原数组进行插入。此外,如果未提供轴,则输入数组会被展开。下面是函数的定义:
- numpy.insert(arr, obj, values, axis)
| 参数 | 说明 |
|---|---|
| arr | 输入数组 |
| obj | 在其之前插入值的索引 |
| values | 要插入的值 |
| axis | 沿着它插入的轴,如果未提供,则输入数组会被展开 |
下面用代码实践一下:
a = np.array([[1,2],[3,4],[5,6]])
print ('第一个数组:')
print (a)
print ('\n')
print ('未传递 Axis 参数。 在插入之前输入数组会被展开。')
print (np.insert(a,3,[11,12]))
print ('传递了 Axis 参数。 会广播值数组来配输入数组。')
print ('沿轴 0 广播:')
print (np.insert(a,1,[11],axis = 0))
print ('沿轴 1 广播:')
print (np.insert(a,1,11,axis = 1))
第一个数组:
[[1 2]
[3 4]
[5 6]]
未传递 Axis 参数。 在插入之前输入数组会被展开。
[ 1 2 3 11 12 4 5 6]
传递了 Axis 参数。 会广播值数组来配输入数组。
沿轴 0 广播:
[[ 1 2]
[11 11]
[ 3 4]
[ 5 6]]
沿轴 1 广播:
[[ 1 11 2]
[ 3 11 4]
[ 5 11 6]]
(2)删除
删除数组元素要用到np.delete函数。np.delete 函数返回从输入数组中删除指定子数组的新数组。 与 np.insert() 函数的情况一样,如果未提供轴参数,则输入数组将展开。下面是函数定义:
- numpy.delete(arr, obj, axis)
| 参数 | 说明 |
|---|---|
| arr | 输入数组 |
| obj | 可以被切片,整数或者整数数组,表明要从输入数组删除的子数组 |
| axis | 沿着它删除给定子数组的轴,如果未提供,则输入数组会被展开 |
下面是具体例子:
a = np.arange(12).reshape(3,4)
print ('第一个数组:')
print (a)
print ('未传递 Axis 参数。 在插入之前输入数组会被展开。')
print (np.delete(a,5))
print ('删除第二列:')
print (np.delete(a,1,axis = 1))
print ('从数组中删除切片对应的元素:')
a = np.array([1,2,3,4,5,6,7,8,9,10])
print (np.delete(a, np.s_[::2]))
第一个数组:
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
未传递 Axis 参数。 在插入之前输入数组会被展开。
[ 0 1 2 3 4 6 7 8 9 10 11]
删除第二列:
[[ 0 2 3]
[ 4 6 7]
[ 8 10 11]]
从数组中删除切片对应的元素:
[ 2 4 6 8 10]
6、数组的复制
数组的复制其实包括两种:重复 (repeat) 和拼接 (tile) 。
- 重复是在元素层面复制
- 拼接是在数组层面复制
np.repeat 方法复制的是数组的每一个元素,参数有几种设定方法:
- 一维数组:用标量和列表来复制元素的个数
- 多维数组:用标量和列表来复制元素的个数,用轴来控制复制的行和列
用具体例子来说明:
a = np.arange(3)
print( a )
print( a.repeat(3) )
print( a.repeat([2,3,4]) )
[0 1 2]
[0 0 0 1 1 1 2 2 2]
[0 0 1 1 1 2 2 2 2]
由上面的例子可以清晰地看到:
- 标量参数 3 表示数组 a 中每个元素复制 3 遍。
- 列表参数 [2,3,4] 表示数组 a 中每个元素分别复制 2, 3, 4 遍。
b = np.arange(6).reshape((2,3))
print( b )
print( b.repeat(2, axis=0) )
print( b.repeat([2,3,4], axis=1) )
[[0 1 2]
[3 4 5]]
[[0 1 2]
[0 1 2]
[3 4 5]
[3 4 5]]
[[0 0 1 1 1 2 2 2 2]
[3 3 4 4 4 5 5 5 5]]
由上面的例子可以看到:
- 标量参数 2 和轴参数 0 表示数组b 中每个元素沿着轴 0 复制 2 遍。
- 列表参数 [2,3,4] 和轴 1表示数组 b 中每个元素沿着轴 1 分别复制 2, 3, 4 遍。
np.tile() 方法复制的是数组本身,参数有几种设定方法:
标量:把数组当成一个元素,一列一列复制
形状:把数组当成一个元素,按形状复制
a = np.arange(6).reshape((2,3))
print( a )
print( np.tile(a,2) )
print( np.tile(a, (2,3)) )
[[0 1 2]
[3 4 5]]
[[0 1 2 0 1 2]
[3 4 5 3 4 5]]
[[0 1 2 0 1 2 0 1 2]
[3 4 5 3 4 5 3 4 5]
[0 1 2 0 1 2 0 1 2]
[3 4 5 3 4 5 3 4 5]]
由上面的例子可以清晰地看到:
- 标量参数 2 表示数组 a 按列复制 2 遍。
- 形状参数 (2,3) - 数组 a 按形状复制 6 (2×3) 遍,并以 (2,3) 的形式展现。
二、数组的计算
1、元素层面的计算
(1)一元运算
一元运算包括倒数、平方、指数、对数、三角函数等等:
a = np.array([[1., 2., 3.], [4., 5., 6.]])
print( 1 / a )
print( a ** 2 )
print( np.exp(a) )
print( np.log(a) )
[[1. 0.5 0.33333333]
[0.25 0.2 0.16666667]]
[[ 1. 4. 9.]
[16. 25. 36.]]
[[ 2.71828183 7.3890561 20.08553692]
[ 54.59815003 148.4131591 403.42879349]]
[[0. 0.69314718 1.09861229]
[1.38629436 1.60943791 1.79175947]]
(2)二元运算
二元运算包括数组间的加减乘除:
a = np.array([[1., 2., 3.], [4., 5., 6.]])
b = np.ones((2,3)) * 2
print( a + b + 1 )
print( a - b )
print( a * b )
print( a / b )
[[4. 5. 6.]
[7. 8. 9.]]
[[-1. 0. 1.]
[ 2. 3. 4.]]
[[ 2. 4. 6.]
[ 8. 10. 12.]]
[[0.5 1. 1.5]
[2. 2.5 3. ]]
(3)比较
a = np.array([[1., 2., 3.], [4., 5., 6.]])
b = np.ones((2,3)) * 2
print(a > b)
print(a > 3)
[[False False True]
[ True True True]]
[[False False False]
[ True True True]]
2、线性代数的计算
因为运行速度的要求,通常会向量化 (vectorization) 而涉及大量的线性代数运算,尤其是矩阵之间的乘积运算。但是,在 NumPy 默认不采用矩阵运算,而是数组 (ndarray) 运算。矩阵只是二维,而数组可以是任何维度,因此数组运算更通用些。
下面我们分别对 数组 和 矩阵 从创建、转置、求逆和相乘四个方面看看它们的同异。
(1)创建
创建数组 arr2d 和矩阵 A:
arr2d = np.array([[1,2],[3,1]])
arr2d
A = np.asmatrix(arr2d)
A
array([[1, 2],
[3, 1]])
matrix([[1, 2],
[3, 1]])
(2)转置
数组用 arr2d.T 操作或 arr.tranpose() 方法,而矩阵用 A.T 操作。主要原因就是 .T 只适合二维数据,在上面也举了个三维数组三个轴之间的变换,这时就需要用函数 arr2d.tranpose 来实现了。
print( arr2d.T )
print( arr2d.transpose() )
print( A.T )
[[1 3]
[2 1]]
[[1 3]
[2 1]]
[[1 3]
[2 1]]
(3)求逆
数组用 np.linalg.inv() 函数,而矩阵用 A.I 和 A**-1 操作:
print( np.linalg.inv(arr2d) )
print( A.I )
print( A**-1 )
[[-0.2 0.4]
[ 0.6 -0.2]]
[[-0.2 0.4]
[ 0.6 -0.2]]
[[-0.2 0.4]
[ 0.6 -0.2]]
(4)相乘
矩阵和数组的相乘是有区别的:
- 数组相乘是在元素层面进行,
- 矩阵相乘要就是数学定义的矩阵相乘 (比如第一个矩阵的列要和第二个矩阵的行一样)
首先看个例子,二维数组相乘一维数组,矩阵相乘向量我们先定义一个一维数组和向量:
a = np.array([1,2])
b = np.asmatrix(a)
print(a,type(a),a.shape)
print(b,type(b),b.shape)
[1 2] <class 'numpy.ndarray'> (2,)
[[1 2]] <class 'numpy.matrix'> (1, 2)
通过结果我们可以看出 a 的形状是 (2,),只含一个元素的元组只说明 arr 是一维,数组是不分行数组或列数组的。而 b 的形状是 (1,2),显然是列向量。
数组和矩阵相乘都是用*:
#array([[1, 2],[3, 1]])
#matrix([[1, 2],[3, 1]])
print( arr2d*arr )
print( A*b )
[[1 4]
[3 2]]
[[7 4]]
由上面结果可知:
- 二维数组相乘一维数组得到的还是个二维数组,解释它需要用到广播机制,这是下节的重点讨论内容。现在大概知道一维数组 [1 2] 第一个元素 1 乘上 [1 3] 得到 [1 3],而第二个元素 2 乘上 [2 1] 得到 [4 2]。
- 而矩阵相乘向量的结果和我们学了很多年的线代结果很吻合。
再看一个例子,二维数组相乘二维数组,矩阵相乘矩阵:
print( arr2d*arr2d )
print( A*A )
[[1 4]
[9 1]]
[[7 4]
[6 7]]
由上面结果可以看出:
- 虽然两个二维数组相乘得到二维数组,但不是根据数学上矩阵相乘的规则得来的,而且由元素层面相乘得到的。两个 [[1 2], [3,1]] 的元素相乘确实等于 [[1 4], [9,1]]。
- 而矩阵相乘矩阵的结果和我们学了很多年的线代结果很吻合。
那么怎么才能在数组上实现「矩阵相乘向量」和「矩阵相乘矩阵」呢?用点乘函数np. dot()。
print( np.dot(arr2d,a) )
print( np.dot(arr2d,arr2d) )
[7 4]
[[7 4]
[6 7]]
结果对了,但还有一个小小的差异
- 矩阵相乘列向量的结果是个列向量,写成 [[7,4]],形状是 (1,2)
- 二维数组点乘一维数组结果是个一维数组,写成 [7,4],形状是 (2,)
3、元素整合计算
在数组中,元素可以以不同方式整合 (aggregation)。拿求和 (sum) 函数来说,我们可以对数组
- 所有的元素求和
- 在某个轴 (axis) 上的元素求和
先定义数组
arr = np.arange(1,7).reshape((2,3))
arr
array([[1, 2, 3],
[4, 5, 6]])
然后对于数组分别对全部元素、跨行 (across rows)、跨列 (across columns) 求和:
arr = np.arange(1,7).reshape((2,3))
print( "所有元素之和:", arr.sum() )
print( "每一列上元素之和", arr.sum(axis=0) )
print( '每一行上元素之和', arr.sum(axis=1) )
所有元素之和: 21
每一列上元素之和 [5 7 9]
每一行上元素之和 [ 6 15]
除了 sum 函数,整合函数还包括 min, max, mean, std 和 cumsum,分别是求最小值、最大值、均值、标准差和累加,这些函数对数组里的元素整合方式和 sum 函数相同,就不多讲了。
4、广播机制的计算
当对两个形状不同的数组按元素操作时,可能会触发「广播机制」。具体做法,先适当复制元素使得这两个数组形状相同后再按元素操作,两个步骤:
- 广播轴 (broadcast axis):比对两个数组的维度,将形状小的数组的维度 (轴) 补齐
- 复制元素:顺着补齐的轴,将形状小的数组里的元素复制,使得最终形状和另一个数组吻合
先来看来例子:
a = np.array([[0, 0, 0],[1, 1, 1],[2, 2, 2], [3, 3, 3]]) #arr1.shape = (4,3)
b = np.array([1, 2, 3]) #arr2.shape = (3,)
print(a + b)
[[1 2 3]
[2 3 4]
[3 4 5]
[4 5 6]]
上例中arr1的shape为(4,3),arr2的shape为(3,)。可以说前者是二维的,而后者是一维的。但是arr1的第二维长度为3,和arr2的维度相同。arr1和arr2的形状并不一样,但是它们可以执行相加操作,这就是通过广播完成的,在这个例子当中是将arr2沿着0轴进行扩展。上面程序当中的广播如下图所示:
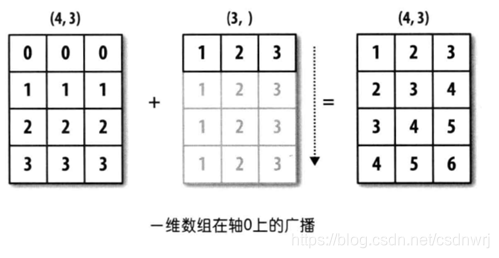
因此,进行广播机制分两步:
- 检查两个数组形状是否兼容,即从两个形状元组最后一个元素,来检查:
a. 它们是否有对应维度的相等子集
b. 是否有一个等于 1 - 一旦它们形状兼容,确定两个数组的最终形状。
触发广播机制一般有两种情况:
(1)维度一样,形状不一样
先举个例子:
a = np.array([[1,2,3]])
b = np.array([[4],[5],[6]])
print( 'a的形状:', a.shape )
print( 'b的形状:', b.shape )
a的形状: (1, 3)
b的形状: (3, 1)
回顾进行广播机制的两步:
- 检查数组 a 和 b 形状是否兼容,从两个形状元组 (1, 3) 和 (3, 1)最后一个元素开始检查,发现它们没有对应维度的相等子集,但它们都满足有一个等于 1的条件。
- 因此它们形状兼容,两个数组的最终形状为 (max(1,3), max(3,1)) = (3, 3)
让我们看看 a + b 等于多少:
c = a + b
print("c的形状:",c.shape)
print(c)
c的形状: (3, 3)
[[5 6 7]
[6 7 8]
[7 8 9]]
(2)维度不一样
也先举个例子:
a = np.array( [[[1,2,3], [4,5,6]]] )
b = np.arange(6).reshape((2,3))
print( 'a的形状:', a.shape )
print( 'b的形状:', b.shape )
a的形状: (1, 2, 3)
b的形状: (2, 3)
回顾进行广播机制的两步:
- 检查数组 a 和 b 形状是否兼容,从两个形状元组 (1,2,3) 和 (2,3)最后一个元素开始检查,发现它们有对应维度的相等子集(2,3),但是维度不同,这时可以让数组b缺失的维度用1补齐,则为(1,2,3),与数组a的形状元组相同。
- 因此它们形状兼容,两个数组的最终形状为 (1,2,3)
c = a + b
print("c的形状:",c.shape)
print(c)
c的形状: (1, 2, 3)
[[[ 1 3 5]
[ 7 9 11]]]

















 1209
1209

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









