 Spark Streaming:输入数据源详解
Spark Streaming:输入数据源详解








 本文详细介绍了Spark Streaming的输入数据源,包括基本源如文件流、套接字流和RDD队列流,以及高级数据源如Flume数据接收。讲解了如何设置接收器从数据源获取DStreams,强调了数据一致性与处理方式,提供了Flume Push模式和Pull模式的配置与测试流程。
本文详细介绍了Spark Streaming的输入数据源,包括基本源如文件流、套接字流和RDD队列流,以及高级数据源如Flume数据接收。讲解了如何设置接收器从数据源获取DStreams,强调了数据一致性与处理方式,提供了Flume Push模式和Pull模式的配置与测试流程。
输入DStreams和接收器
输入DStreams表示从数据源获取输入数据流的DStreams。在NetworkWordCount例子中,lines表示输入DStream,它代表从netcat服务器获取的数据流。每一个输入流DStream和一个Receiver对象相关联,这个Receiver从源中获取数据,并将数据存入内存中用于处理。
输入DStreams表示从数据源获取的原始数据流。Spark Streaming拥有两类数据源:
- 基本源(Basic sources):这些源在StreamingContext API中直接可用。例如文件系统、套接字连接、Akka的actor等
- 高级源(Advanced sources):这些源包括Kafka,Flume,Kinesis,Twitter等等
文件流:通过监控文件系统的变化,若有新文件添加,则将它读入并作为数据流
需要注意的是
① 这些文件具有相同的格式
② 这些文件通过原子移动或重命名文件的方式在dataDirectory创建
③ 如果在文件中追加内容,这些追加的新数据也不会被读取。

注意:要演示成功,需要在原文件中编辑,然后拷贝一份

import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* @Autho: Administrator and wind
* @Version: 2019/11/22 & 1.0
*
* 文件流
* Streaming监控文件系统变化,把变化类容采集进来
*/
object FileStreaming {
def main(args: Array[String]): Unit = {
//减少日志打印
Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
val conf = new SparkConf().setMaster("local[2]").setAppName("FileStreaming")
val ssc = new StreamingContext(conf,Seconds(3))
val lines = ssc.textFileStream("E:\\test\\temp")
lines.print()
ssc.start()
ssc.awaitTermination()
}
}
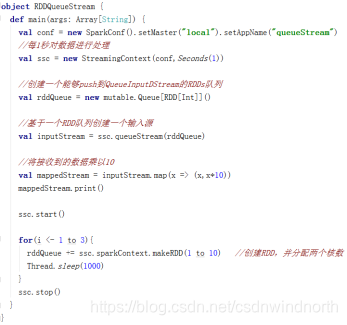
RDD队列流
使用streamingContext.queueStream(queueOfRDD)创建基于RDD队列的DStream,用于调试Spark Streaming应用程序
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutable.Queue
/**
* @Autho: Administrator and wind
* @Version: 2019/11/22 & 1.0
*
* RDD队列流
*/
object RDDQueueStream {
def main(args: Array[String]): Unit = {
//减少日志打印
Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
val conf = new SparkConf().setAppName("RDDQueueStream").setMaster("local[2]")
val ssc = new StreamingContext(conf,Seconds(3))
val rddQueue = new Queue[RDD[Int]]()
for(i <- 1 to 3){
rddQueue += ssc.sparkContext.makeRDD(1 to 10)
Thread.sleep(3000)
}
//从对列中接收数据
val inputDStream = ssc.queueStream(rddQueue)
val result = inputDStream.map(x=>(x,x*2))
result.print()
ssc.start()
ssc.awaitTermination()
}
}
套接字流:通过监听Socket端口来接收数据

高级数据源
Spark Streaming接收Flume数据
- 基于Flume的Push模式
Flume被用于在Flume agents之间推送数据.在这种方式下,Spark Streaming可以很方便的建立一个receiver,起到一个Avro agent的作用.Flume可以将数据推送到改receiver.
第一步:Flume的配置文件
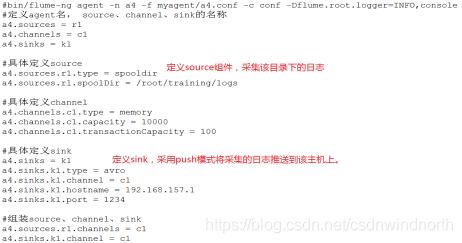
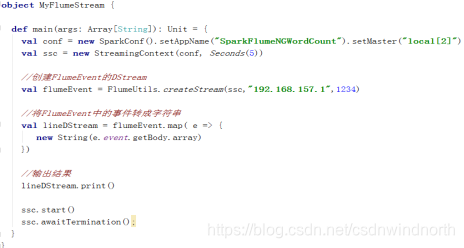
第二步:Spark Streaming程序
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.flume.FlumeUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* @Autho: Administrator and wind
* @Version: 2019/11/22 & 1.0
*
*/
object MyFlumeStream {
def main(args: Array[String]): Unit = {
//减少日志打印
Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
val conf = new SparkConf().setMaster("local[2]").setAppName("MyFlumeStream")
val ssc = new StreamingContext(conf,Seconds(3))
val flumeEventDStream = FlumeUtils.createStream(ssc,"192.168.1.1",1234)
val lineDStream = flumeEventDStream.map(e => {
new String(e.event.getBody.array())
})
lineDStream.print()
ssc.start()
ssc.awaitTermination()
}
}
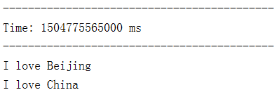
第三步:测试
- 启动Spark Streaming程序
- 启动Flume
- 拷贝日志文件到/root/training/logs目录
- 观察输出,采集到数据
基于Custom Sink的Pull模式
不同于Flume直接将数据推送到Spark Streaming中,第二种模式通过以下条件运行一个正常的Flume sink。Flume将数据推送到sink中,并且数据保持buffered状态。Spark Streaming使用一个可靠的Flume接收器和转换器从sink拉取数据。只要当数据被接收并且被Spark Streaming备份后,转换器才运行成功。
这样,与第一种模式相比,保证了很好的健壮性和容错能力。然而,这种模式需要为Flume配置一个正常的sink。
以下为配置步骤:
第一步:Flume的配置文件
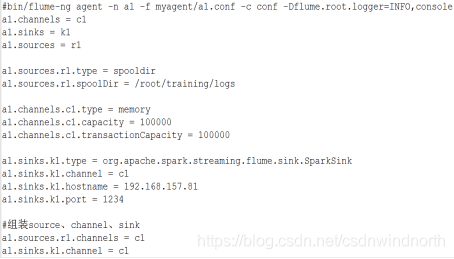
第二步:Spark Streaming程序
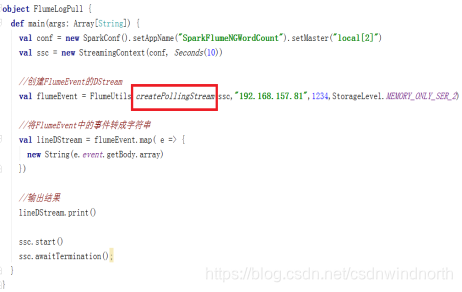
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.flume.FlumeUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* @Autho: Administrator and wind
* @Version: 2019/11/24 & 1.0
*
*/
object FlumeLogPull {
def main(args: Array[String]): Unit = {
//减少日志打印
Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
val conf = new SparkConf().setAppName("FlumeLogPull").setMaster("local[2]")
val ssc = new StreamingContext(conf,Seconds(3))
val flumeEvent = FlumeUtils.createPollingStream(ssc,"192.168.1.121",1234,StorageLevel.MEMORY_ONLY)
val lineDStream = flumeEvent.map(e => {
new String(e.event.getBody.array())
})
lineDStream.print()
ssc.start()
ssc.awaitTermination()
}
}
第三步:需要的jar包
- 将Spark的jar包拷贝到Flume的lib目录下
- 下面的这个jar包也需要拷贝到Flume的lib目录下,同时加入IDEA工程的classpath
https://pan.baidu.com/s/1d39r_tIen3e51O98jCLGfw
第四步:测试
- 启动Flume
- 在IDEA中启动FlumeLogPull
- 将测试数据拷贝到/root/training/logs
- 观察IDEA中的输出


















 8417
8417

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









