




 本文深入探讨Spark Streaming,介绍其如何通过批处理实现实时数据流处理,强调DStream作为基本抽象的概念,详细阐述DStream的转换操作,特别是transform和updateStateByKey,以及窗口计算的重要性和工作原理,包括窗口长度和滑动间隔的设置,并展示了如何在数据流上集成Spark SQL进行更复杂的分析。
本文深入探讨Spark Streaming,介绍其如何通过批处理实现实时数据流处理,强调DStream作为基本抽象的概念,详细阐述DStream的转换操作,特别是transform和updateStateByKey,以及窗口计算的重要性和工作原理,包括窗口长度和滑动间隔的设置,并展示了如何在数据流上集成Spark SQL进行更复杂的分析。
Spark Streaming简介
Spark Streaming是核心Spark API的扩展,可实现可扩展、高吞吐量、可容错的实时数据流处理。数据可以从诸如Kafka,Flume,Kinesis或TCP套接字等众多来源获取,并且可以使用由高级函数(如map,reduce,join和window)开发的复杂算法进行流数据处理。最后,处理后的数据可以被推送到文件系统,数据库和实时仪表板。而且,您还可以在数据流上应用Spark提供的机器学习和图处理算法

Spark Streaming的特点

Spark Streaming的内部结构
在内部,它的工作原理如下。Spark Streaming接收实时输入数据流,并将数据切分成批,然后由Spark引擎对其进行处理,最后生成“批”形式的结果流。

Spark Streaming将连续的数据流抽象为discretizedstream或DStream。在内部,DStream 由一个RDD序列表示。
案例:NetworkWordCount
由于在本案例中需要使用netcat网络工具,所以需要先安装
Linux命令
yum install nc
**启动netcat数据流服务器,并监听端口:1234
命令:nc -l -p 1234
服务器端
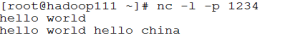
启动客户端
bin/run-example streaming.NetworkWordCount localhost 1234
客户端:

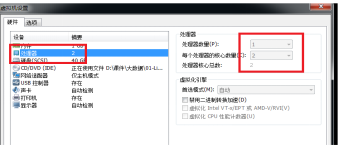
(一定注意):如果要执行本例,必须确保机器cpu核数大于2
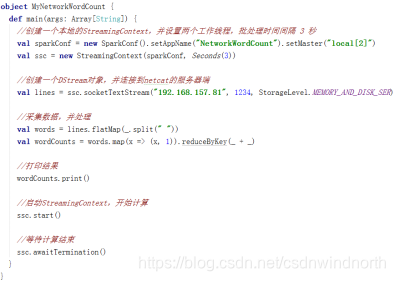
开发自己的NetworkWordCount
(一定注意):
val sparkConf = new SparkConf().setAppName(“NetworkWordCount”).setMaster(“local[2]”)
官方的解释:
import org.apac 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 630
630

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









