







 本文主要探讨了如何优化Spark Streaming的性能,包括减少批数据执行时间的策略,如并行接收和处理数据、调整批容量,以及内存调优,如序列化格式优化和管理持久化RDD,以确保稳定的数据处理速率和降低GC暂停时间。
本文主要探讨了如何优化Spark Streaming的性能,包括减少批数据执行时间的策略,如并行接收和处理数据、调整批容量,以及内存调优,如序列化格式优化和管理持久化RDD,以确保稳定的数据处理速率和降低GC暂停时间。
减少批数据的执行时间
在Spark中有几个优化可以减少批处理的时间:
① 数据接收的并行水平
通过网络(如kafka,flume,socket等)接收数据需要这些数据反序列化并被保存到Spark中。如果数据接收成为系统的瓶颈,就要考虑并行地接收数据。注意,每个输入DStream创建一个receiver(运行在worker机器上)接收单个数据流。创建多个输入DStream并配置它们可以从源中接收不同分区的数据流,从而实现多数据流接收。例如,接收两个topic数据的单个输入DStream可以被切分为两个kafka输入流,每个接收一个topic。这将在两个worker上运行两个receiver,因此允许数据并行接收,提高整体的吞吐量。多个DStream可以被合并生成单个DStream,这样运用在单个输入DStream的transformation操作可以运用在合并的DStream上
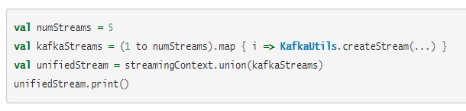
② 数据处理的并行水平
如果运行在计算stage上的并发任务数不足够大,就不会充分利用集群的资源。默认的并发任务数通过配置属性来确定spark.default.parallelism。
③ 数据序列化
可以通过改变序列化格式来减少数据序列化的开销。在流式传输的情况下,有两种类型的数据会被序列化
- 输入数据
- 由流操作生成的持久RDD
在上述两种情况下,使用Kryo序列化格式可以减少CPU和内存开销
kryo
spark 支持使用kryo序列化类库来进行序列化
比java序列化机制更快,且占用数据空间更小,比Java序列化数据占用空间小10倍。
如何使用kryo序列化机制
(1)设置spark conf
bin/spark-submit will also read configuration options from conf/spark-defaults.conf, in which each line consists of a key and a value separated by whitespace. For example:
spark.master spark://5.6.7.8:7077
spark.executor.memory 4g
spark.eventLog.enabled true
spark.serializer org.apache.spark.serializer.KryoSerializer
(2)使用kryo时,要求需要序列化的类,提前进行注册,以获得高性能。
conf.registerKryoClasses(Array(classOf[String],classOf[Student],classOf[Integer]))
kryo类库的优化
(1)优化缓存大小
如果注册的序列化的自定义类型,本身特别大,比如包含了超过100个字段。就会导致序列化的对象过大。
此时需要对kryo本身进行优化。因为kryo本身内部缓存可能不能存放这么大的class对象。
需要设置:
spark.kryoserializer.buffer.max 64m 将其调大
Maximum allowable size of Kryo serialization buffer.
This must be larger than any object you attempt to serialize.
Increase this if you get a “buffer limit exceeded” exception inside Kryo.
(2)预先注册自定义类型
conf.registerKryoClasses(Array(classOf[String],classOf[Student],classOf[Integer]))
推荐预先注册要序列化的自定义类型。
设置正确的批容量
为了Spark Streaming应用程序能够在集群中稳定运行,系统应该能够以足够的速度处理接收的数据(即处理速度应该大于或等于接收数据的速度)。这可以通过流的网络UI观察得到。批处理时间应该小于批间隔时间。
根据流计算的性质,批间隔时间可能显著的影响数据处理速率,这个速率可以通过应用程序维持。可以考虑WordCountNetwork这个例子,对于一个特定的数据处理速率,系统可能可以每2秒打印一次单词计数(批间隔时间为2秒),但无法每500毫秒打印一次单词计数。所以,为了在生产环境中维持期望的数据处理速率,就应该设置合适的批间隔时间(即批数据的容量)。
找出正确的批容量的一个好的办法是用一个保守的批间隔时间(5-10,秒)和低数据速率来测试你的应用程序。
内存调优
它们可以减少Spark Streaming应用程序垃圾回收的相关暂停,获得更稳定的批处理时间。
-
Default persistence level of DStreams:和RDDs不同的是,默认的持久化级别是序列化数据到内存中(DStream是StorageLevel.MEMORY_ONLY_SER,RDD是StorageLevel.MEMORY_ONLY)。即使保存数据为序列化形态会增加序列化/反序列化的开销,但是可以明显的减少垃圾回收的暂停
-
Clearing persistent RDDs:默认情况下,通过Spark内置策略(LUR),Spark Streaming生成的持久化RDD将会从内存中清理掉。如果spark.cleaner.ttl已经设置了,比这个时间存在更老的持久化RDD将会被定时的清理掉。正如前面提到的那样,这个值需要根据Spark Streaming应用程序的操作小心设置。然而,可以设置配置选项spark.streaming.unpersist为true来更智能的去持久化(unpersist)RDD。这个配置使系统找出那些不需要经常保有的RDD,然后去持久化它们。这可以减少Spark RDD的内存使用,也可能改善垃圾回收的行为
-
Concurrent garbage collector:使用并发的标记-清除垃圾回收可以进一步减少垃圾回收的暂停时间。尽管并发的垃圾回收会减少系统的整体吞吐量,但是仍然推荐使用它以获得更稳定的批处理时间

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









