




本案例由开发者:山东科技大学-崔宾阁老师提供
1 概述
1.1 案例介绍
随着葡萄酒市场的不断发展,对葡萄酒进行准确分类对于葡萄酒的生产、销售都具有重要意义。华为开发者空间云主机平台提供了稳定高效的开发环境,使开发者能够在云端快速搭建应用。
本案例依托华为开发者空间提供的云主机与CodeArts IDE,并利用深度学习框架PyTorch搭建多层感知机(MLP)模型实现葡萄酒(Wine)数据集分类。PyTorch是一个开源的机器学习库,广泛用于各种深度学习任务,如计算机视觉、自然语言处理等。它提供了强大的自动微分功能和灵活的张量计算能力,使得开发者能够轻松地构建和训练复杂的神经网络模型。多层感知机(MLP)是一种前馈神经网络,它包含一个或多个隐藏层。MLP能够学习非线性模型,因此在许多复杂的分类和回归任务中表现出色。
通过本案例,开发者将学习如何运用PyTorch框架进行数据预处理、MLP模型定义以及模型的训练与评估。同时,开发者将熟悉华为云主机平台及CodeArts IDE开发环境,提升项目实战能力,为后续更复杂的项目开发打下坚实基础。
1.2 适用对象
- 个人开发者
- 高校学生
1.3 案例时间
本案例总时长预计60分钟。
1.4 案例流程

说明:
① 申请并登录华为开发者空间—云主机,打开CodeArts IDE创建工程;
② 在云主机CodeArts IDE for Python中配置环境,安装项目所需的依赖包;
③ 在云主机CodeArts IDE for Python中编写项目代码并运行;
1.5 资源总览
本案例预计花费总计0元。
| 资源名称 | 规格 | 单价(元) | 时长(分钟) |
| 开发者空间—云主机 | 鲲鹏通用计算增强型 kC2 | 4vCPUs | 8G | Ubuntu | 免费 | 60 |
| CodeArts IDE | CodeArts IDE for Python | 免费 | 60 |
2 操作步骤
2.1 配置开发者空间—云主机
本案例中,使用华为开发者空间所提供的云主机平台以及CodeArts IDE + Python开发工具,基于Pytorch搭建多层感知机(MLP)模型实现葡萄酒(Wine)数据集分类。点击链接( https://support.developer.huaweicloud.com/doc/development/resource-tools/zh-cn_topic_0000002367559525-0000002367559525 ) 可跳转至免费领取云主机指南。
1. 在浏览器中输入华为云开发者空间网址:https://developer.huaweicloud.com/developerspace,进入到华为云开发者空间页面。
在华为开发者空间页面点击“免费领取”,跳转到开发者空间页面,如未领取根据页面提示进行云主机领取。

2. 在开发者空间页面,点击左侧“工作台”按钮进入工作台页面,再点击“配置云主机”进行云主机的配置。

3. 在配置云主机窗口中自定义云主机名称,配置完毕后点击“安装”。

4. 安装完毕后点击“打开云主机”>“进入桌面”即可进入云主机。

5. 等待环境云主机下载镜像、安装系统、安装工具集,首次进入云主机大约需要3至5分钟。

6. 环境准备完毕后,即可进入云主机,云主机桌面如下图所示。

2.2 创建项目
CodeArts IDE是一个集成开发环境(IDE),兼具源代码编辑器的简易性和开发人员工具的强大功能,如代码补全和调试。它将精简的源代码编辑器与强大的开发者工具结合在一起。
1. 双击打开云主机桌面上的CodeArts IDE for Python。

2. 首次使用CodeArts IDE创建工程,可直接点击左侧栏目中的“新建工程”,项目名称为“WineClassifierMLP”(用户可自行取名),工程存放位置、Python解释器直接使用默认配置,接着点击右下角蓝色“创建”按钮。
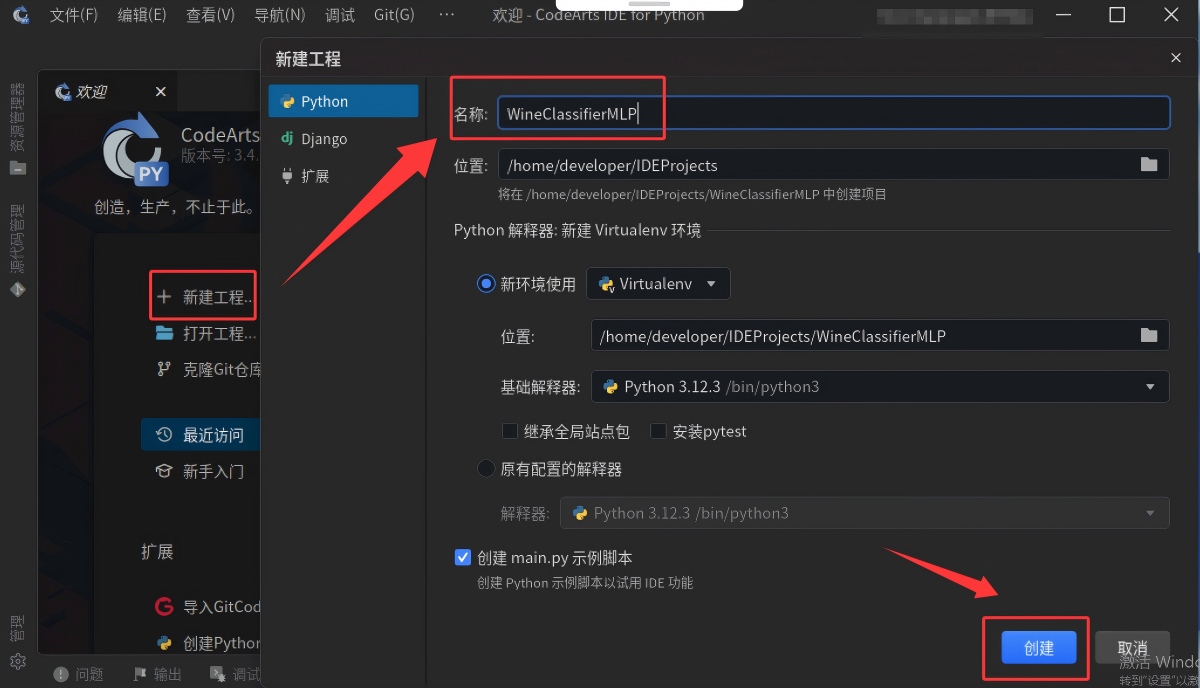
3. 在新建的“WineClassifierMLP”工程项目中,点击左上角的“文件”,依次点击“新建”—>“文件”,新建一个Jupyter Notebook类型的文件。

4. 在弹出的窗口中,选择文件类型为“Jupyter Notebook .ipynb支持”,从而创建一个Jupyter Notebook文件,该文件是一种交互式文档,支持分步执行代码。

5. 新创建的.ipynb文件默认命名为“Untitled-1.ipynb”,当保存该文件时,会提示重命名。点击右上角“选择内核”,为代码运行提供支持。

6. 在“选择内核”窗口中,点击第一项,选择“Jupyter”内核源。若在保存文件后,按提示 “安装/启动建议的扩展python+jupyter”却因版本冲突无法成功安装,此时可尝试重置云主机,更新到最新的IDE版本,之后再重新进行内核相关操作。

7. 内核选择在新建工程时新建的虚拟环境,点击第三项“venv(Python3.12.3)”。

8. 选择完成后,可以在右上角看到当前Notebook文件运行用到的内核。

9. 在Notebook文件的代码单元格中输入代码,点击单元格左上角的运行按钮,安装ipykernel模块,该模块是将Python环境注册为Jupyter内核的关键组件。

10. 可以在右下角看到ipykernel包的安装,大约等待5-8分钟,该包安装完成。

2.3 葡萄酒分类数据集介绍
本案例采用的葡萄酒分类数据集,由加州大学欧文分校(UCI)的Arthur D. Anderson博士于1991年创建,旨在为葡萄酒化学成分与其产地之间的关联研究提供数据支持。该数据集包含了来自意大利三个不同产区的178种葡萄酒样本,每种样本记录了13种化学成分的测量值。这13种化学成分分别为酒精、苹果酸、灰、灰分的碱度、镁、总酚、黄酮类化合物、非黄烷类酚类、原花色素、颜色强度、色调、稀释葡萄酒的OD280/OD315、脯氨酸。其中第1类有59个样本,第2类有71个样本,第3类有48个样本。
下图使用“print()”函数输出一些关于葡萄酒数据集的基本信息,包括特征名称、目标类别、 数据形状和目标形状,并展示了数据集的前五行数据。

2.4 安装项目所需的依赖包
1. 首先点击CodeArts for Python下方工具栏中的“终端”进入到命令行交互界面,然后输入下面代码中的命令,以激活环境。
source /home/developer/IDEProjects/WineClassifierMLP/venv/bin/activate
2. 在终端界面中输入下面代码中的安装命令,以安装项目所需的依赖包。
pip3 install torch torchvision torchaudio scikit-learn matplotlib 如果安装太慢,可以使用国内源,如使用下面代码中的命令进行安装。
pip3 install torch torchvision torchaudio scikit-learn matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple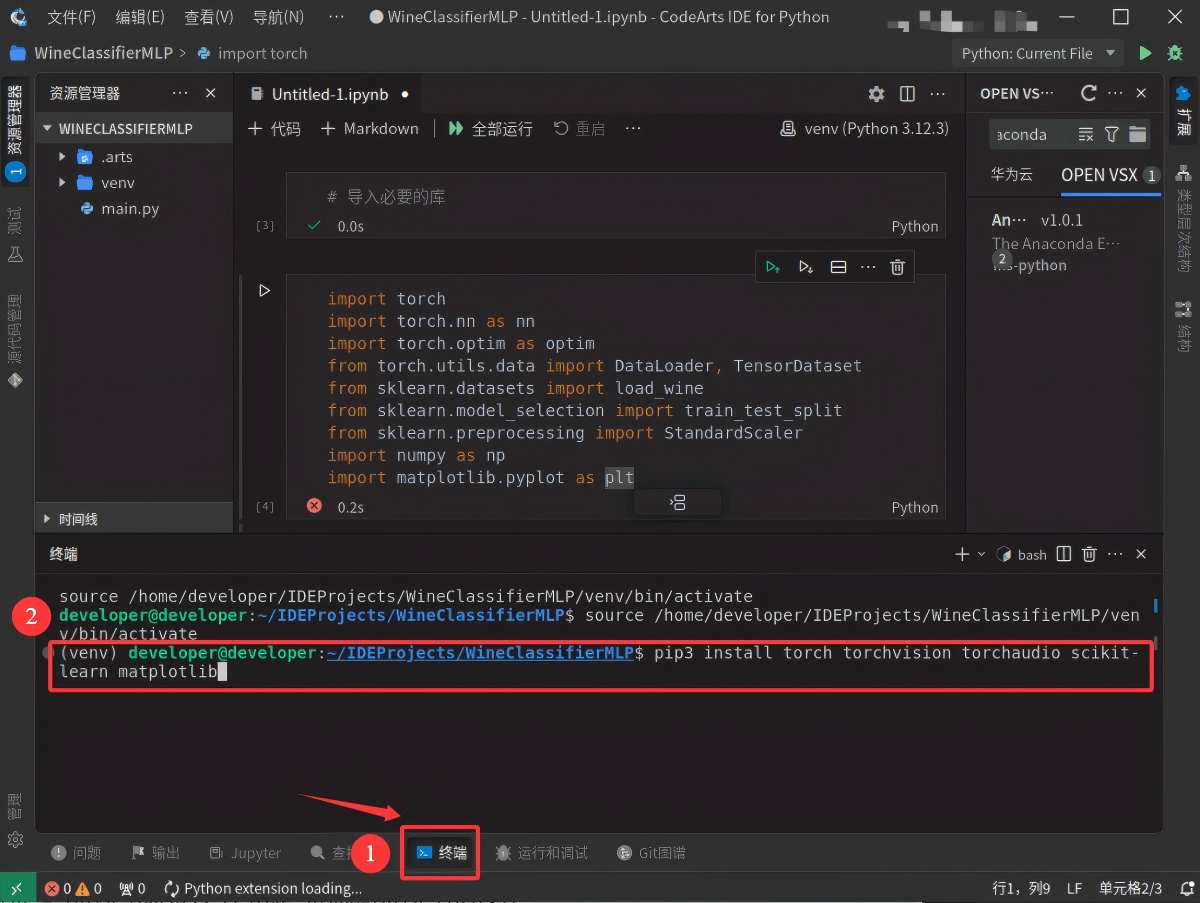
3. 安装依赖包预计需要10-15分钟,具体取决于网络环境。当终端界面出现如下图所示的信息时,表示项目所需的依赖包安装成功。同时,通过点击单元格代码左侧的“运行”按钮,等待3秒左右后如果出现一个绿色的“√”,也可验证项目所需的依赖包安装成功。

2.5 编写并运行代码
代码基于PyTorch搭建了一个多层感知机模型(MLP)用于实现葡萄酒(Wine)数据集分类,完整代码可以通过此链接https://github.com/xxxxfff/MLP进行获取,对于代码的详细讲解如下:
1. 导入必要的包
(1) torch.nn:PyTorch中的神经网络模块,包含各种神经网络层和激活函数。
(2) torch.optim:PyTorch中的优化器模块,用于更新模型的权重。
(3) torch.utils.data:PyTorch中的数据加载工具,用于创建数据加载器。
(4) sklearn.datasets:Scikit-learn中的数据集模块,用于加载Wine数据集。
(5) sklearn.model_selection:Scikit-learn中的模型选择模块,用于划分训练集和测试集。
(6) sklearn.preprocessing:Scikit-learn中的预处理模块,用于数据标准化。
(7) numpy:用于数值计算。
(8) matplotlib.pyplot:用于绘制图表。
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import numpy as np
import matplotlib.pyplot as plt点击“+ 代码”新建代码单元格,在新建的代码单元格中编写并运行“导入必要的包”的代码,运行成功的截图如下。

2. 加载数据集
创建数据集加载函数 load_data(),在函数中使用sklearn.datasets.load_wine()加载Wine数据集。
# 加载数据集
def load_data():
data = load_wine()
X = data.data
y = data.target
return X, y点击“+ 代码”新建代码单元格,在新建的代码单元格中编写并运行“创建加载数据集函数load_data()”的代码,运行成功的截图如下。

3. 数据预处理
创建数据预处理函数 preprocess_data(),首先使用StandardScaler对特征数据进行标准化处理,使每个特征的均值为0,标准差为1,然后将标准化后的数据和目标变量转换为PyTorch张量。
# 数据预处理
def preprocess_data(X, y):
# 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 转换为 PyTorch 张量
X_tensor = torch.tensor(X_scaled, dtype=torch.float32)
y_tensor = torch.tensor(y, dtype=torch.long)
return X_tensor, y_tensor点击“+ 代码”新建代码单元格,在新建的代码单元格中编写并运行“创建数据预处理函数preprocess_data()”的代码,运行成功的截图如下。

4. 构建MLP模型
使用PyTorch的torch.nn模块定义一个多层感知机(MLP)模型,在__init__方法中,定义了模型的各个层,包含三个全连接层和ReLU激活函数,在forward方法中,定义了数据在模型中的前向传播路径。
# 构建 MLP 模型
class MLP(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(MLP, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, hidden_size)
self.fc3 = nn.Linear(hidden_size, output_size)
def forward(self, x):
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
x = self.relu(x)
x = self.fc3(x)
return x点击“+ 代码”新建代码单元格,在新建的代码单元格中编写并运行“构建MLP模型”的代码,运行成功的截图如下。

5. 训练模型
创建训练模型函数 train_model(),在train_model()函数中,使用model.train()将模型设置为训练模式,然后遍历每个epoch,对训练数据进行迭代,并计算每个epoch的平均损失和准确率,并记录到losses和accuracies列表中,最终返回losses和accuracies列表。
# 训练模型
def train_model(model, train_loader, criterion, optimizer, num_epochs=20):
model.train()
losses = []
accuracies = []
for epoch in range(num_epochs):
epoch_loss = 0
correct = 0
total = 0
for inputs, targets in train_loader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += targets.size(0)
correct += (predicted == targets).sum().item()
epoch_loss /= len(train_loader)
epoch_accuracy = correct / total
losses.append(epoch_loss)
accuracies.append(epoch_accuracy)
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {epoch_loss:.4f}, Accuracy: {epoch_accuracy:.4f}')
return losses, accuracies点击“+ 代码”新建代码单元格,在新建的代码单元格中编写并运行“创建训练模型函数train_model()”的代码,运行成功的截图如下。

6. 评估模型
创建评估模型函数 test_model(),在test_model()函数中,使用model.eval()将模型设置为评估模式,并使用torch.no_grad()禁用梯度计算,以提高评估速度。然后遍历测试数据,计算测试集的准确率。
# 评估模型
def test_model(model, test_loader):
model.eval()
with torch.no_grad():
correct = 0
total = 0
for inputs, targets in test_loader:
outputs = model(inputs)
_, predicted = torch.max(outputs.data, 1)
total += targets.size(0)
correct += (predicted == targets).sum().item()
accuracy = correct / total
print(f'Test Accuracy: {accuracy:.4f}')
return accuracy点击“+ 代码”新建代码单元格,在新建的代码单元格中编写并运行“创建评估模型函数test_model()”的代码,运行成功的截图如下。

7. 创建绘制训练损失和精度函数
创建plot_training_history()函数来绘制训练损失和精度随训练轮数的变化,首先使用matplotlib库创建一个图形,包含两个子图。第一个子图绘制训练损失随训练轮数(epoch)的变化,第二个子图绘制训练准确率随训练轮数(epoch)的变化。然后使用plt.legend()添加图例,并使用plt.tight_layout()调整子图布局,最后使用plt.savefig('training_loss_and_accuracy.png') 将图形保存为当前文件夹下的training_loss_and_accuracy.png图片。
# 绘制训练损失和精度并保存图片
def plot_training_history(losses, accuracies):
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(losses, label='Training Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(accuracies, label='Training Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.title('Training Accuracy')
plt.legend()
plt.tight_layout()
# 保存图片
plt.savefig('training_loss_and_accuracy.png')点击“+ 代码”新建代码单元格,在新建的代码单元格中编写并运行“创建绘制训练损失和精度函数plot_training_history()”的代码,运行成功的截图如下。

8. 创建主函数
(1) 加载数据:调用load_data函数加载Wine数据集。
(2) 数据预处理:调用preprocess_data函数对数据进行预处理。
(3) 划分训练集和测试集:使用train_test_split将样本划分为训练集和测试集,训练集占80%,测试集占20%。
(4) 创建DataLoader:使用TensorDataset和DataLoader创建训练集和测试集的数据加载器。
(5) 定义模型、损失函数和优化器:调用MLP类创建模型实例,使用交叉熵损失函数(CrossEntropyLoss)计算损失,使用Adam优化器进行优化。
(6) 训练模型:调用train_model函数训练模型,共训练20轮。
(7) 评估模型:调用test_model函数评估模型在测试集上的性能。
(8) 绘制训练损失和精度并保存图片:调用plot_training_history函数绘制训练损失和精度的图表,并将图表保存为training_loss_and_accuracy.png。
# 主函数
def main():
# 加载数据
X, y = load_data()
# 数据预处理
X_tensor, y_tensor = preprocess_data(X, y)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_tensor, y_tensor, test_size=0.2, random_state=42)
# 创建 DataLoader
train_dataset = TensorDataset(X_train, y_train)
test_dataset = TensorDataset(X_test, y_test)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
# 定义模型、损失函数和优化器
input_size = X.shape[1]
hidden_size = 100
output_size = 3
model = MLP(input_size, hidden_size, output_size)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练模型
losses, accuracies = train_model(model, train_loader, criterion, optimizer, num_epochs=20)
# 评估模型
test_accuracy = test_model(model, test_loader)
# 绘制训练损失和精度并保存图片
plot_training_history(losses, accuracies)点击“+ 代码”新建代码单元格,在新建的代码单元格中编写并运行“创建主函数main()”的代码,运行成功的截图如下。

9. 调用主函数
最后使用if __name__ == "__main__":代码块调用主函数,从而实现对葡萄酒数据集(Wine)的分类。
if __name__ == "__main__":
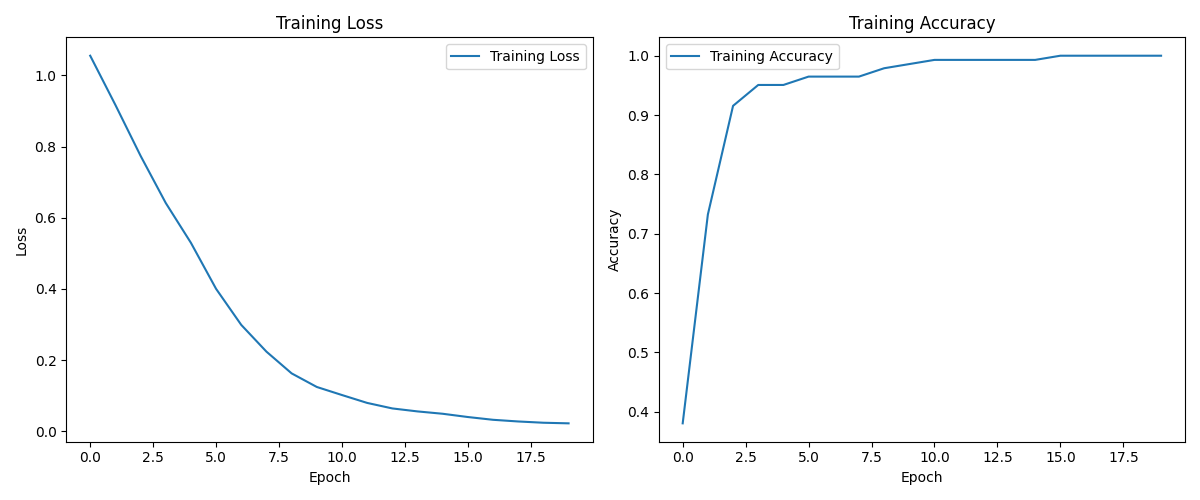
main()点击“+ 代码”新建代码单元格,在新建的代码单元格中编写并运行“调用主函数”的代码,运行成功的截图如下。等待5秒左右后,返回模型训练和测试的运行结果,并将training_loss_and_accuracy.png保存到当前文件夹下。从运行结果图中可以看到随着训练轮数(共20轮)的增加,Loss损失函数的值在缓慢地降低以及Accuracy准确率的值在缓慢地升高。

下图是训练损失(Training Loss)和训练准确率(Training Accuracy)的折线图,横轴表示训练轮次,纵轴分别表示损失和准确率,可以看到随着训练轮数的增加,Training Loss的值在缓慢地降低以及Training Accuracy的值在缓慢地升高。这是因为在训练过程中模型通过不断地优化参数,逐步学习到数据中的特征和模式,减少预测误差,从而提高了准确率。
至此本次实验全部内容完成。
2.6 拓展思考
1. 尝试增加MLP模型的隐藏层,观察模型的性能是否有所提升。
2. 尝试不同的激活函数,如ReLU、Sigmoid、Tanh等,比较它们对模型性能的影响。
3. 逐步增加训练轮数(epoch),观察模型的性能是否随着训练轮数的增加而提高。
3 释放资源
3.1 关闭云主机
1. 首先点击云主机桌面上面的“关机”按钮,然后在弹出来的提示框点击“确定”按钮,关闭云主机。

2. 点击“确定”按钮后页面自动跳转到开发者空间页面,可以看到我的云主机显示“关机中”,说明云主机正在关机。

3.2 检查资源
云主机关机后,等待3至5分钟,当我的云主机显示“已就绪”时,说明云主机成功关机,下次使用云主机只需点击“打开云主机”>“进入桌面”即可,可参考2.1小节。



















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









