 基于华为云与DeepSeek的数据分析工作流
基于华为云与DeepSeek的数据分析工作流





本案例由开发者:熊文涛提供
一. 概述
1. 案例介绍
在当今这个数字经济时代,数据无疑成为企业最核心的资产之一。面对激烈的市场竞争,企业若想精准决策,迅速响应市场变化,就必须依赖高效的数据分析能力。数据分析不仅能够帮助企业洞察市场趋势、预测消费者行为,更可以优化运营效率,降低成本,提升企业的整体竞争力。
本案例通过华为开发者空间云开发环境和DeepSeek打造全链路高效数据分析工作流,帮助开发者和企业在数据驱动的道路上走得更快、更稳。
华为开发者空间是为全球开发者打造的专属开发者空间,致力于为每位开发者提供一台云主机、一套开发工具和云上存储空间,汇聚昇腾、鸿蒙、鲲鹏、GaussDB、欧拉等华为各项根技术的开发工具资源,并提供配套案例指导开发者从开发编码到应用调测,基于华为根技术生态高效便捷的知识学习、技术体验、应用创新。
2. 适用对象
- 企业
- 个人开发者
- 高校学生
3. 案例时间
本案例总时长预计90分钟。
4. 案例流程

说明: 1. 用户进入华为开发者空间云开发环境; 2. 通过CLI工具连接云开发环境; 3. 安装ollama并启动本地推理模型DeepSeek; 4. 结合Python中丰富的三方库、MySQL、DeepSeek,从数据采集、清洗、建模到可视化展示,构建全链路数据分析工作流。
5. 资源总览
本案例预计花费0元。
| 资源名称 | 规格 | 单价(元) | 时长(分钟) |
|---|---|---|---|
| 华为开发者空间 - 云开发环境 | 鲲鹏通用计算增强型 kc1 | 2vCPUs | 4G | HCE | 免费 | 90 |
二. 云开发环境及开发工具准备
2.1 云开发环境
本案例中,使用华为云《开发者空间云开发环境使用指导》的“三、PC端创建和管理云开发环境”章节完成cli工具安装、环境配置、创建云开发环境、开机、建立隧道连接的功能。

2.2 开发工具准备
本案例中,使用华为云《本地CodeArts IDE基于华为开发者空间云开发环境完成小游戏开发》的“三.本地IDE直连云开发环境完成上传下载”章节完成本地IDE连接远程开发环境。

三. 部署DeepSeek大模型
3.1 下载安装ollama
输入以下命令下载ollama:
curl -fsSL https://dtse-mirrors.obs.cn-north-4.myhuaweicloud.com/case/0035/install.sh | sudo bash
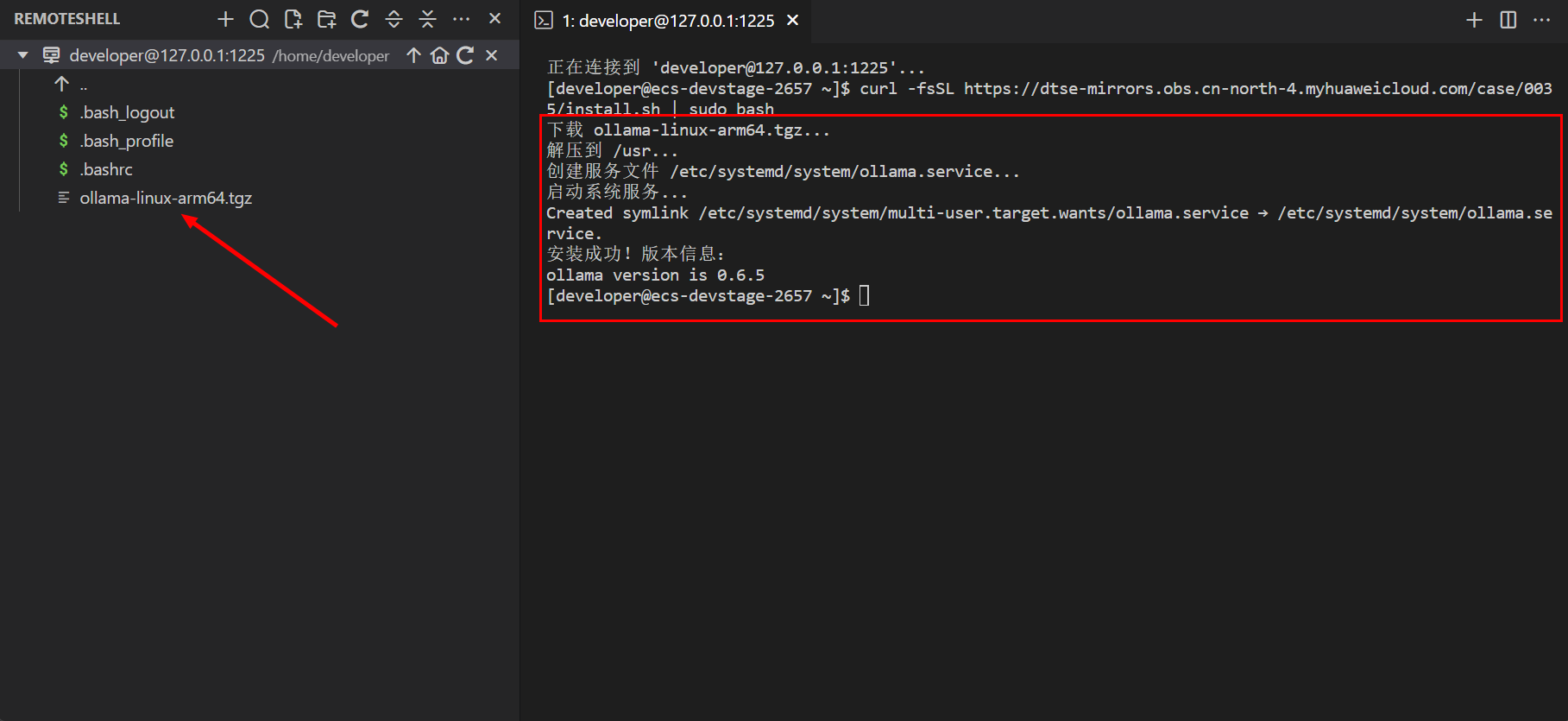
下载完毕之后我们可以借助 Ollama 工具来部署 Deepseek 大模型,部署 deepseek-r1:1.5b 版本,如果硬件支撑可以部署更高效的模型,执行命令:
ollama run deepseek-r1:1.5b

3.2 部署测试模型
以上我们就部署完了,可以尝试输入prompt来测试效果:

通过以下命令,可以查看olloama开放的本地端口:
sudo netstat -tunlp

那么接下来我们可以打开CodeArt IDE for Python,对端口进行通信,完成这一步之后我们可以开始尝试构建智能体。
我们知道 ollama serve 默认监听地址为 http://localhost:11434 ,首先下载requests库:
pip install requests

新建DataAnalysis/src文件夹,用于存放项目源码,src下新建文件main.py:
import requests
def chat_with_ollama(prompt, model="deepseek-r1:1.5b"):
url = "http://localhost:11434/api/generate"
headers = {
"Content-Type": "application/json"
}
data = {
"model": model,
"prompt": prompt,
"stream": False # 关闭流式返回,适合简单测试
}
try:
response = requests.post(url, json=data, headers=headers)
response.raise_for_status()
result = response.json()
print("模型回复:", result["response"])
except requests.exceptions.RequestException as e:
print("请求出错:", e)
except Exception as e:
print("其他错误:", e)
if __name__ == "__main__":
test_prompt = "你好"
chat_with_ollama(test_prompt)

我们进入DataAnalysis/src文件夹下,执行python代码:
cd DataAnalysis/src
python main.py
如何能获取到大模型输出,说明我们之前的过程都没有问题:

四. 数据分析工作流项目工程介绍及运行
我们下一步就可以开始全链路高效数据分析工作流搭建了,开始之前,我们首先看下整个项目的目录结构:

4.1 创建项目虚拟环境
因为业务场景的Python开发,多数都是构建一个大型应用程序,并且不希望各种组件的各种版本之间相互冲突,所以需要设置一个虚拟环境。
先需要更新下载源。执行如下命令:
sudo yum -y update
sudo yum -y upgrade


安装virtualenv:
pip3 install virtualenv -i https://repo.huaweicloud.com/repository/pypi/simple/

创建虚拟环境:
python3 -m venv myenv
激活环境:
source myenv/bin/activate

环境激活后,用户名前会有(myenv)字样,如上图所示。
4.2 安装依赖并配置模型
安装依赖之前,更新pip:
python3 -m pip install --upgrade pip -i https://repo.huaweicloud.com/repository/pypi/simple/

使用pip3依次安装pandas、sqlalchemy、pymysql、python-dotenv、requests、matplotlib、plotly模块:
pip3 install pandas==2.2.2 -i https://repo.huaweicloud.com/repository/pypi/simple/
pip3 install sqlalchemy==2.0.32 -i https://repo.huaweicloud.com/repository/pypi/simple/
pip3 install pymysql==1.1.1 -i https://repo.huaweicloud.com/repository/pypi/simple/
pip3 install python-dotenv==1.0.1 -i https://repo.huaweicloud.com/repository/pypi/simple/
pip3 install requests==2.32.3 -i https://repo.huaweicloud.com/repository/pypi/simple/
pip3 install matplotlib==3.9.0 -i https://repo.huaweicloud.com/repository/pypi/simple/
pip3 install plotly==5.23.0 -i https://repo.huaweicloud.com/repository/pypi/simple/

启动本地推理模型:
ollama pull deepseek-r1:1.5b
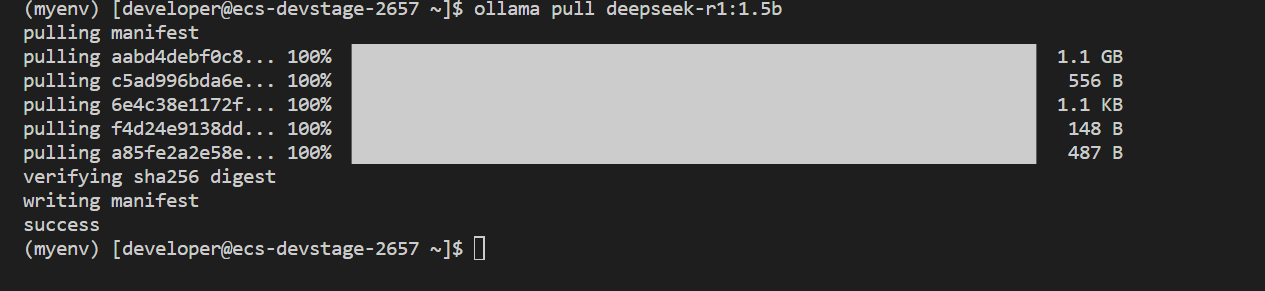
本地模型配置:
在DataAnalysis目录下,新建.env文件:
LLM_PROVIDER=ollama
LLM_HOST=http://localhost:11434
LLM_MODEL=deepseek-r1:1.5b
4.3 文本预处理(Text Cleaning & 信息抽取)
进行数据清洗及信息抽取,格式化输出数据,便于模型调用。
4.3.1 代码:src/data_cleaning.py
data_cleaning.py:用于数据清洗及信息抽取,便于模型调用。
import os, re, json, requests
from typing import List, Dict, Any
from dotenv import load_dotenv
from typing import Optional, Union
load_dotenv()
class LLMClient:
def __init__(self):
self.provider = os.getenv("LLM_PROVIDER", "ollama")
self.host = os.getenv("LLM_HOST", "http://localhost:11434")
self.model = os.getenv("LLM_MODEL", "deepseek-r1:1.5b")
self.api_key = os.getenv("LLM_API_KEY", "")
def generate(self, prompt: str) -> str:
if self.provider == "ollama":
resp = requests.post(f"{self.host}/api/generate", json={
"model": self.model, "prompt": prompt, "stream": False
})
resp.raise_for_status()
return resp.json().get("response", "").strip()
else:
raise ValueError(f"Unsupported LLM provider: {self.provider}")
class DataCleaningAgent:
def __init__(self, llm: Optional[LLMClient] = None):
self.llm = llm or LLMClient()
@staticmethod
def clean_text(text: str) -> str:
text = re.sub(r"<[^>]+>", " ", text) # 去HTML
text = re.sub(r"\s+", " ", text) # 合并空白
text = re.sub(r"[^\w\s\u4e00-\u9fa5@::,,。.\-—/()()]+", " ", text) # 去特殊符
return text.strip()
def extract_fields(self, text: str, instruction: str) -> Dict[str, Any]:
"""
instruction 示例:
从文本中提取公司名称(company)、联系人(contact)、电话(phone)。返回JSON,如:
{"company": "...", "contact": "...", "phone": "..."}
"""
prompt = f"""你是信息抽取助手。请严格输出JSON。
文本:{text}
任务:{instruction}
注意:
1. 只输出一个JSON对象,不要输出多余文字。
2. 缺失字段请用null。
"""
raw = self.llm.generate(prompt)
return parse_llm_json_response(raw)
# try:
# return json.loads(raw)
# except Exception:
# # LLM 偶发输出非纯JSON,兜底提取
# m = re.search(r"\{.*\}", raw, re.S)
# return json.loads(m.group(0)) if m else {"_raw": raw}
def batch_process(self, samples: List[str], instruction: str) -> List[Dict[str,Any]]:
out = []
for s in samples:
cleaned = self.clean_text(s)
extracted = self.extract_fields(cleaned, instruction)
out.append({"original": s, "cleaned": cleaned, "extracted": extracted})
return out
def parse_llm_json_response(raw: str) -> Dict[str, Any]:
"""
解析 LLM 生成的 JSON 响应,带有强大的错误处理和回退机制
Args:
raw: LLM 生成的原始响应字符串
Returns:
解析后的 JSON 字典,或包含原始响应的字典
"""
# 首先尝试直接解析
try:
return json.loads(raw)
except json.JSONDecodeError:
# 如果直接解析失败,尝试提取可能的 JSON 部分
pass
# 使用更精确的正则表达式匹配 JSON 对象
# 改进1: 非贪婪匹配,匹配第一个{到最后一个}之间的内容
# 改进2: 处理可能的嵌套结构
json_pattern = r"\{.*\}"
match = re.search(json_pattern, raw, re.DOTALL)
if match:
try:
return json.loads(match.group())
except json.JSONDecodeError:
# 如果提取的内容仍然不是有效 JSON,尝试清理内容
cleaned_json = clean_json_string(match.group())
try:
return json.loads(cleaned_json)
except json.JSONDecodeError:
# 最终回退
pass
# 如果所有尝试都失败,返回原始文本
return {"_raw": raw, "_error": "Failed to parse JSON response"}
def clean_json_string(json_str: str) -> str:
"""
清理 JSON 字符串,尝试修复常见问题
Args:
json_str: 需要清理的 JSON 字符串
Returns:
清理后的 JSON 字符串
"""
# 移除尾随逗号(在最后一个元素后)
cleaned = re.sub(r',\s*}', '}', json_str)
cleaned = re.sub(r',\s*]', ']', cleaned)
# 修复单引号(JSON 标准要求双引号)
cleaned = re.sub(r"'([^']*)'", r'"\1"', cleaned)
# 移除注释(JSON 不支持注释)
cleaned = re.sub(r'//.*?$', '', cleaned, flags=re.MULTILINE)
cleaned = re.sub(r'/\*.*?\*/', '', cleaned, flags=re.DOTALL)
return cleaned
4.3.2 运行脚本:src/preprocess.py
preprocess.py:数据清洗及信息抽取的执行类,输出清洗后的格式化数据。
import json, os
from pathlib import Path
from data_cleaning import DataCleaningAgent
ROOT = Path(__file__).resolve().parents[2]
RAW_DIR = ROOT / "data" / "raw"
PROC_DIR = ROOT / "data" / "processed"
PROC_DIR.mkdir(parents=True, exist_ok=True)
def read_raw_samples():
files = sorted(RAW_DIR.glob("*.txt"))
if not files:
# 内置两条示例,避免“无数据就跑不起来
return [
"联系人:张三,联系电话:123456789,公司:江西省招标有限公司",
"地址:南昌市东湖区,北京华为技术有限公司;联系人王五,电话:13800001234"
]
samples = []
for f in files:
samples.append(f.read_text(encoding="utf-8"))
return samples
if __name__ == "__main__":
agent = DataCleaningAgent()
samples = read_raw_samples()
instruction = "请提取company(公司名称)、contact(联系人)、phone(电话)。返回JSON。"
results = agent.batch_process(samples, instruction)
# 写入两个文件,便于排查与复用
with open(PROC_DIR / "cleaned.jsonl", "w", encoding="utf-8") as fw1, \
open(PROC_DIR / "extracted.jsonl", "w", encoding="utf-8") as fw2:
for r in results:
fw1.write(json.dumps({"original": r["original"], "cleaned": r["cleaned"]},ensure_ascii=False) + "\n")
fw2.write(json.dumps(r["extracted"], ensure_ascii=False) + "\n")
print(f"已输出:{PROC_DIR/'cleaned.jsonl'} 与 {PROC_DIR/'extracted.jsonl'}")
激活python虚拟环境,进入DataAnalysis/src 目录下,执行python文件。
依次执行以下命令:
source myenv/bin/activate
cd DataAnalysis/
cd src
python preprocess.py

执行成功后,在/home/developer/data/processed目录下生成cleaned.json1和extracted.json1文件,数据清理并提取json数据。
4.4 Text2SQL(自然语言 → SQL → 结果)
自然语言转换成SQL语句,使用SQL语句查询MySQL数据库,返回查询结果。
4.4.1 安装MySQL
更新系统软件包:
sudo yum update
sudo yum upgrade -y

安装MySQL服务器:
sudo yum install mysql-server -y

启动并设置开机自启:
sudo systemctl start mysqld
sudo systemctl enable mysqld

验证 MySQL 运行状态:
sudo systemctl status mysqld

显示 active (running) 则表示成功启动。
安装nano:
sudo yum install nano

先创建目录,再配置MySQL:
sudo mkdir -p /etc/mysql/mysql.conf.d
sudo nano /etc/mysql/mysql.conf.d/mysqld.cnf
[mysqld]
bind-address = 0.0.0.0 # 允许远程连接(生产环境建议注释或设置为服务器IP)
port = 3306
character-set-server = utf8mb4 # 字符集设置
collation-server = utf8mb4_unicode_ci
innodb_buffer_pool_size = 1G # 内存分配(根据服务器总内存调整)
max_connections = 200 # 最大连接数

按下Ctrl+x,再按下Y保存,最后按下Enter键,退出编辑状态。
重启MySQL:
sudo systemctl restart mysqld
使用root用户登录:
sudo mysql -u root

创建数据库和用户:
SELECT VERSION();
SHOW DATABASES;
CREATE DATABASE mydatabase CHARACTER SET utf8mb4;
CREATE USER '用户名'@'localhost' IDENTIFIED BY '密码';
GRANT ALL PRIVILEGES ON mydatabase.* TO '用户名'@'localhost';
FLUSH PRIVILEGES;
EXIT;
注意:用户名和密码要替换成您自己的。
数据库配置:
在DataAnalysis目录下.env文件中,添加数据库配置:
LLM_PROVIDER=ollama
LLM_HOST=http://localhost:11434
LLM_MODEL=deepseek-r1:1.5b
DB_URL=mysql+pymysql://用户名:密码@localhost:3306/mydatabase
注意:用户名和密码要替换成您自己的。
4.4.2 准备演示数据
在data目录下,创建sales.csv文件:
product_name,year,sales_amount,region
产品A,2023,15000000,华东
产品B,2023,12000000,华南
产品C,2023,11000000,华北
产品D,2022, 8000000,华东

4.4.3 代码:src/text2sql.py
text2sql.py:自然语言转换成SQL语句。
import os, sqlite3, pandas as pd, requests
from sqlalchemy import create_engine, text
from dotenv import load_dotenv
load_dotenv()
class SQLRunner:
def __init__(self, db_url: str):
self.engine = create_engine(db_url)
def exec(self, sql: str) -> pd.DataFrame:
with self.engine.connect() as conn:
return pd.read_sql_query(text(sql), conn)
def init_from_csv(self, csv_path: str, table_name: str = "sales"):
df = pd.read_csv(csv_path)
with self.engine.connect() as conn:
df.to_sql(table_name, conn, if_exists="replace", index=False)
class NL2SQLAgent:
def __init__(self, schema_hint: str = "", provider=None, host=None, model=None,api_key=None):
self.schema_hint = schema_hint
self.provider = provider or os.getenv("LLM_PROVIDER", "ollama")
self.host = host or os.getenv("LLM_HOST", "http://localhost:11434")
self.model = model or os.getenv("LLM_MODEL", "deepseek-r1:1.5b")
self.api_key = api_key or os.getenv("LLM_API_KEY", "")
def _ask(self, prompt: str) -> str:
if self.provider == "ollama":
r = requests.post(f"{self.host}/api/generate", json={"model": self.model, "prompt": prompt, "stream": False})
r.raise_for_status()
return r.json().get("response", "")
else:
# 以 DashScope 为例,其它厂商同理
headers = {"Authorization": f"Bearer {self.api_key}","Content-Type": "application/json"}
r = requests.post(f"{self.host}/chat/completions", headers=headers, json={"model": self.model, "messages":[{"role":"user","content":prompt}]})
r.raise_for_status()
return r.json()["choices"][0]["message"]["content"]
def generate_sql(self, question: str) -> str:
prompt = f"""你是SQL生成助手。根据以下数据库结构和问题,生成可在对应数据库上直接执行的SQL。
只返回SQL,不要任何解释或注释。
[数据库结构]{self.schema_hint}
[问题]{question}
"""
sql = self._ask(prompt).strip().strip("```").replace("sql", "")
return sql
4.4.4 运行脚本:src/text2sql_demo.py
text2sql_demo.py:自然语言转换成SQL语句的执行类,输出转换后的SQL语句并操作MySQL数据库。
import os
import re
from pathlib import Path
from dotenv import load_dotenv
from text2sql import SQLRunner, NL2SQLAgent
load_dotenv()
ROOT = Path(__file__).resolve().parents[2]
if __name__ == "__main__":
db_url = os.getenv("DB_URL", "mysql+pymysql://用户名:密码@localhost:3306/mydatabase")
csv_path = ROOT / "data" / "sales.csv"
# 1) 初始化数据库与示例表
runner = SQLRunner(db_url)
runner.init_from_csv(str(csv_path), table_name="sales")
# 2) 提供 schema_hint(强烈建议绑定到你企业真实数据字典)
schema = """CREATE TABLE sales (product_name TEXT,year INTEGER,sales_amount INTEGER,region TEXT);"""
agent = NL2SQLAgent(schema_hint=schema)
# 3) 自然语言问题
q = "查找2023年所有销售额超过1000万的产品,并按销售额降序排列"
sql = agent.generate_sql(q)
# 使用 split() 方法分割字符串,以 "</think>" 为分隔符,并取最后一部分
parts = sql.split("</think>")
# 提取最后一部分并去除首尾空格
real_sql = parts[-1].strip()
print("生成的SQL:\n", real_sql.strip())
# 4) 执行与结果
df = runner.exec(real_sql.strip())
print("\n查询结果:\n", df.to_string(index=False).strip())
注意:DB_URL中的用户名和密码要替换成您自己的用户名和密码。
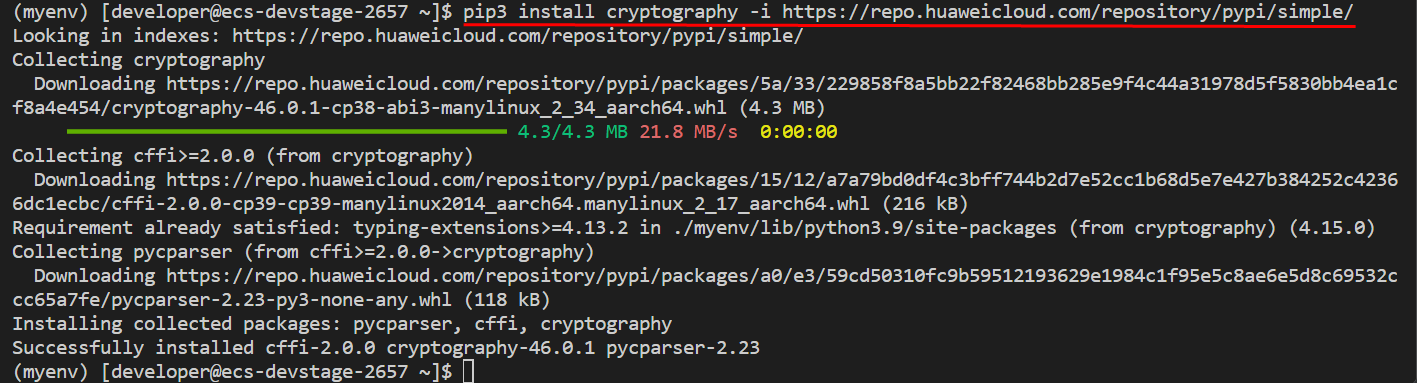
安装cryptography库:
pip3 install cryptography -i https://repo.huaweicloud.com/repository/pypi/simple/
进入DataAnalysis/src 目录下,执行python文件。
依次执行以下命令:
cd DataAnalysis/
cd src
python text2sql_demo.py

生成了SQL语句,并根据SQL语句查询了数据库,返回了查询结果。
4.5 可视化智能体(Visualization Agent)
可视化智能体是一种能够分析数据、生成见解并通过可视化方式呈现结果的智能系统。结合 Pandas 进行数据处理和Matplotlib/Seaborn/Plotly 进行可视化,可以构建一个基础的智能体框架。也可以将DataFrame 交给大模型智能体,让它根据数据内容决定可视化方式,并自动生成图表代码(如用 matplotlib/ plotly / seaborn)。这种做法本质上就是构建一个 DataFrame 可视化智能体(Visualization Agent),它能够结合数据结构、字段含义与任务需求,为用户自动设计图表并呈现。具体实现逻辑很简单:DataFrame → LLM → 图表自动生成。
4.5.1 代码:src/viz.py
viz.py:数据分析与可视化。
import pandas as pd
import matplotlib.pyplot as plt
class VizAgent:
def __init__(self, df: pd.DataFrame):
self.df = df
def bar(self, x: str, y: str, title: str = ""):
plt.figure()
self.df.plot(kind="bar", x=x, y=y, title=title)
plt.savefig('bar1.png')
def line(self, x: str, y: str, title: str = ""):
plt.figure()
self.df.plot(kind="line", x=x, y=y, marker="o", title=title)
plt.savefig('line.png')
def topk(self, y: str, k: int = 10):
plt.figure()
self.df.nlargest(k, y).plot(kind="bar", x=self.df.columns[0], y=y, title=f"Top-{k} by {y}")
plt.savefig('bar2.png')
4.5.2 运行脚本:src/viz_demo.py
viz_demo:数据分析与可视化的执行类,调用viz.py中的方法,生成可视化图表。
import os
from dotenv import load_dotenv
from text2sql import SQLRunner
from viz import VizAgent
load_dotenv()
if __name__ == "__main__":
db_url = os.getenv("DB_URL", "mysql+pymysql://用户名:密码@localhost:3306/mydatabase")
runner = SQLRunner(db_url)
# 直接查询或接前一节 NL2SQL 的 df
df = runner.exec("SELECT product_name, sales_amount FROM sales WHERE year=2023 ORDER BY sales_amount DESC;")
VizAgent(df).bar(x="product_name", y="sales_amount", title="2023 product sales bar chart")
注意:DB_URL中的用户名和密码要替换成您自己的用户名和密码。
进入DataAnalysis/src 目录下,执行python文件。
python viz_demo.py
执行成功后,在src目录下生成bar1.png图片。
下载到本地打开:
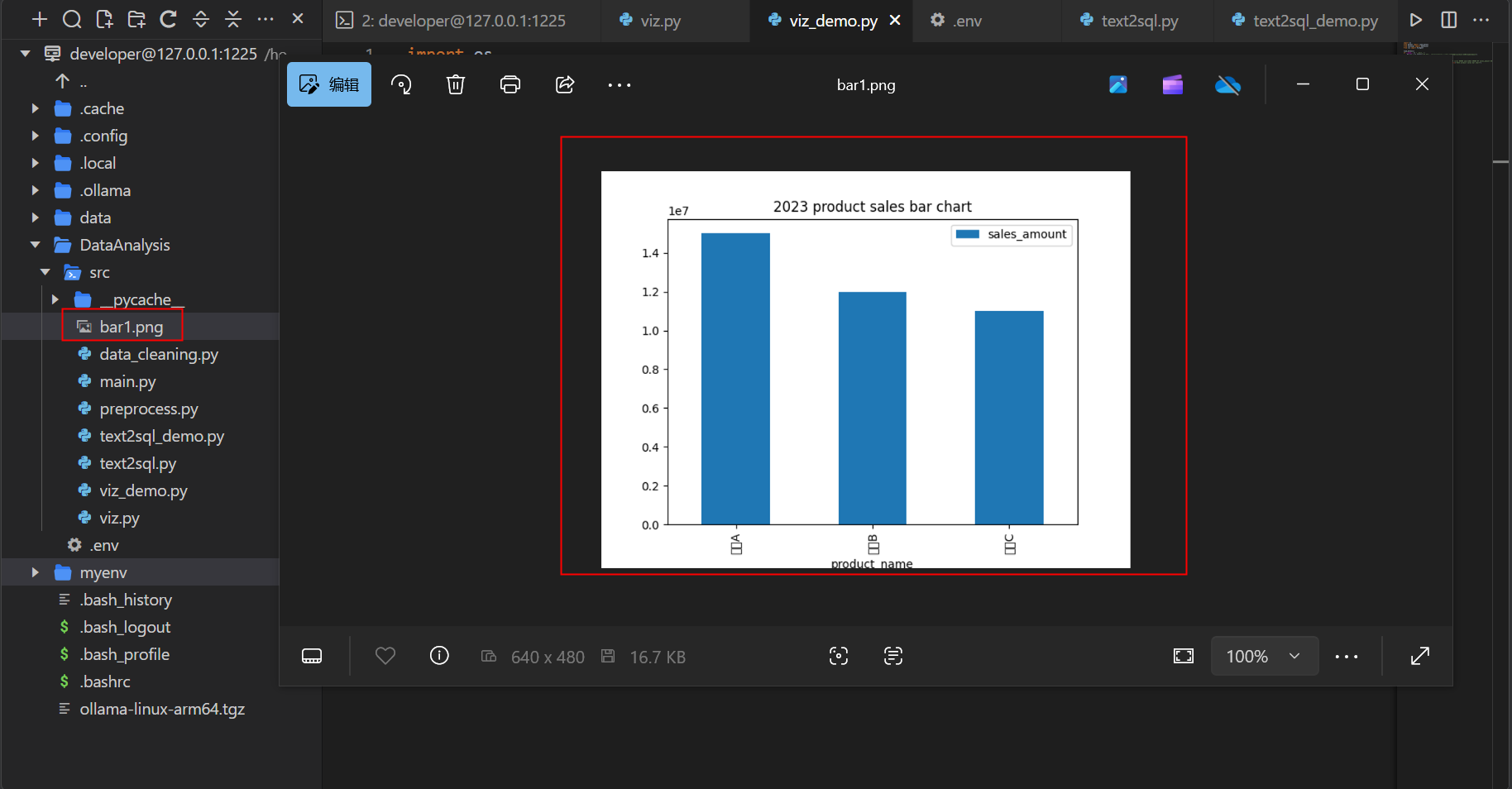
至此,华为开发者空间云开发环境 x DeepSeek打造全链路高效数据分析工作流的案例已全部完成。
反馈改进建议
如您在案例实操过程中遇到问题或有改进建议,可以到论坛帖评论区反馈即可,我们会及时响应处理,谢谢!


















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









