




整理 | 郑丽媛
出品 | 程序人生(ID:coder_life)
本周,OpenAI 宣布与知名在线编程问答论坛 Stack Overflow 达成技术合作:
ChatGPT 将能使用来自 Stack Overflow 可靠准确、高度技术性的知识和代码——这些数据”由 15 年来为 Stack Overflow 平台做出贡献的数百万开发人员“所提供。
同时,Stack Overflow 也能利用 OpenAI 模型作为其 OverflowAI 开发的一部分,并通过内测最大限度地提高 OpenAI 模型的性能。
在官宣博文中,Stack Overflow 表示:“这将使开发者能利用世界领先的高技术内容知识平台的集体优势和世界上最流行的 LLM 模型进行 AI 开发。”
然而,不同于 Stack Overflow 和 OpenAI 的乐观,众多 Stack Overflow 用户得知此消息后,强烈反对平台与 OpenAI 合作,并火速删除或修改了他们发布的各种帖子和答案,以免被 AI 拿去训练。
结果没想到,Stack Overflow 不仅恢复了被删掉的帖子和答案,还把这部分抗议的用户直接封号禁言了。


用户提出抗议+删帖,便被封号禁言
提起 Stack Overflow,相信多数程序员都不陌生。这是一个成立于 2008 年、面向开发者的问答网站,用户可提出并回答任何有关编程的技术问题。在过去 15 年中,Stack Overflow 逐步拥有了一个庞大的开发者社区,成为了许多开发者解决常见编码难题的首要选择,也积累了相当多的优质解答和代码。
自从与 OpenAI 合作的消息公布以来,Stack Overflow 用户社区中便引发了巨大争议,许多人无法接受他们贡献的答案被用来支持和训练 AI 模型,对此表示愤怒和抗议,并试图修改或删除他们在 Stack Overflow 上发表的帖子。
一位用户写道,"我讨厌这样,我要把我的答案一个个删除。"他指出,他不在乎这是否违反了 Stack Overflow“愚蠢的政策”:“你们的政策可以在不事先征求利益相关者意见的情况下随意更改。既然你们不关心用户,那我也不关心你们。”
据悉,这位用户所说的“愚蠢的政策”,是指 Stack Overflow 的服务条款规定:帖子一旦发布,就会成为其他贡献者“集体努力的一部分”,只有在特殊情况下才能删除——也就是说,Stack Overflow 对用户在该平台上提供的所有内容,都拥有不可撤销的所有权。
听起来似乎过于强势?但事实证明,在这方面 Stack Overflow 确实如此强势。
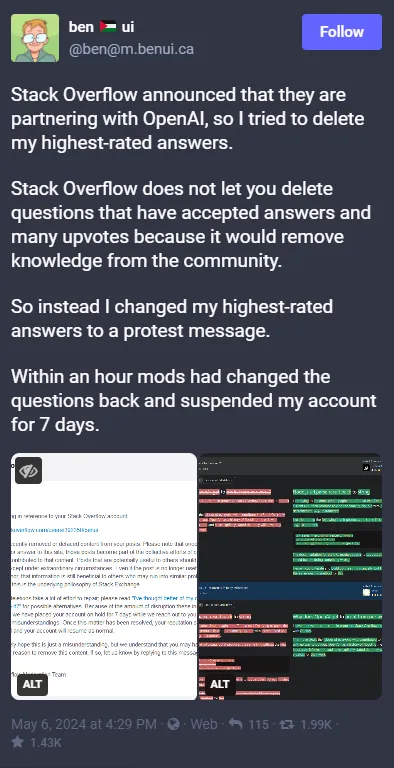
近日,一位名叫 Ben 的 Stack Overflow 用户在 Mastodon 上分享了他发布抗议信息后被禁言的经历:
Stack Overflow 宣布他们将与 OpenAI 合作,于是我想删了我评价最高的答案。
Stack Overflow 不允许你删除已接受答案并获得许多赞的问题,因为这样做会删除社区中的知识。
因此,我把评分最高的答案改成了抗议信息。
不到一个小时,Mods 就把问题改回来了,并把我的账户暂停了 7 天。
在这个线程下,Ben 继续补充道:“我只是想提醒大家,你们在某些平台上发布的所有信息都可能被用来牟利。例如你在 Discord、Twitter 等平台上发布的信息,迟早都会被收集起来,输入到一个模型中,然后再卖给你。”——Ben 的这个说法虽然不太中听,但很大程度上代表了加入抗议行列的 Stack Overflow 用户的想法。
还有许多用户提出:既然是合作,为什么 ChatGPT 不能分享它提供的答案来源,这样既能注明来源,又能增加答案的可信度。理论上来说,这个提议较为合理,因为 Stack Overflow 虽然拥有用户帖子的所有权,但网站使用的是知识共享 4.0 许可,即要求注明出处。不过目前来看,ChatGPT 未来是否会遵循这一许可还未可知。

对于 AI 的立场,突然转换
事实上,除了反对 Stack Overflow 不经用户同意便将数据提供给 AI 训练的决定外,很多用户还对 Stack Overflow 在生成式 AI 政策上的急转直下尤为愤慨。
还记得 2022 年底 ChatGPT 刚上线不久,Stack Overflow 就反其道而行,发布了封禁通知:禁止在 Stack Overflow 上发布 ChatGPT 生成的文本。当时 Stack Overflow 给出的理由是,ChatGPT 生成的答案正确率太低,而发布由 ChatGPT 生成的答案对网站和查询正确答案的用户来说非常有害,从而会对 Stack Overflow 的质量管理造成冲击。
自此之后,Stack Overflow 也一直坚持这项政策,即禁止使用生成式 AI 编写或改写发布的任何问题或答案,违规者最多封号 30 天,同时鼓励版主在审核帖子时用 AI 检测软件。当时还有不少报道称,ChatGPT 的出现严重降低了 Stack Overflow 的流量。
然而从上周开始,Stack Overflow 突然就改变了对 AI 的说法。其 CEO Prashanth Chandrasekar 在博文中赞扬了生成式 AI 的优点,还说“GenAI 的崛起对 Stack 来说是一个巨大的机遇”。然后很快地,平台管理人员就接到指示,停止删除论坛上 AI 生成的问题和答案。
据了解,Stack Overflow 并非唯一一家为了利益而改变对 AI 立场的公司:Valve 也悄无声息地取消了其在 Steam 上的 AI 禁令,并允许 1000 多款 AI 游戏涌入店面。
如此看来,Stack Overflow 选择改变立场与 OpenAI 合作似乎也是一种顺势而为。只不过,对于许多反对的用户来说,这样突然的立场转换,某种程度上来说也是一种“背叛”。
参考链接:
https://www.tomshardware.com/tech-industry/artificial-intelligence/stack-overflow-bans-users-en-masse-for-rebelling-against-openai-partnership-users-banned-for-deleting-answers-to-prevent-them-being-used-to-train-chatgpt
https://arstechnica.com/information-technology/2024/05/stack-overflow-users-sabotage-their-posts-after-openai-deal/
推荐阅读:
▶突发!阿里游戏核心人员云风离职,自曝原因:“Ant Engine项目被关停”
▶iOS 越狱开发者反被苹果“招安”:不得再碰“越狱”,便转身开源了 10 款工具!
▶火爆外网的「十亿行挑战」,国外大神用C++应战:从67s到0.77s,速度狂飙87倍!


















 1617
1617

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









