




Spark Shuffle 调优详解
在 Spark SQL 和 DataFrame 的执行中,Shuffle 是最关键、最影响性能的操作之一。Shuffle 不仅涉及数据重分布,还直接影响任务并行度和最终输出文件数量。本文从基础概念到调优策略,系统梳理 Shuffle 相关参数和优化方法。
一、Spark 任务执行逻辑回顾
Spark 的执行逻辑可以简化为:
SQL/DataFrame -> Catalyst优化(逻辑计划) -> 物理计划 -> DAG切Stage -> Task调度 -> Executor执行 -> 结果/文件输出
1. Stage 与 Task
-
Stage:按 Shuffle 划分的执行阶段。Stage 之间通过宽依赖(wide dependency,如 groupBy、join)进行数据交换。
-
Task:Stage 的最小执行单元,每个 Task 处理一个数据分区。Task 数 = 分区数。
2. 数据分区与算子类型
-
窄依赖算子(Narrow dependency,如 map、filter):父分区和子分区一对一,可流水线执行,无需落盘。
-
宽依赖算子(Wide dependency,如 groupByKey、join、distinct):父分区和子分区多对多,需要 Shuffle,Stage 切分点。
二、Shuffle 的执行逻辑
Shuffle 是宽依赖算子触发的关键操作,可分为两个阶段:
-
Shuffle Write
-
每个 Task 根据分区规则将数据按 key 划分到下游分区。
-
Task 可能将数据溢写到磁盘。
-
每个 Task 生成一组中间文件,为下游 Stage 的 Task 读取做准备。
-
-
Shuffle Read
-
下游 Stage 的 Task 拉取上游 Shuffle 文件中属于自己的分区数据。
-
拉取后进行聚合或排序,执行下游算子。
-
Shuffle 是 Stage 切分的边界,也是 Spark 性能的瓶颈之一。
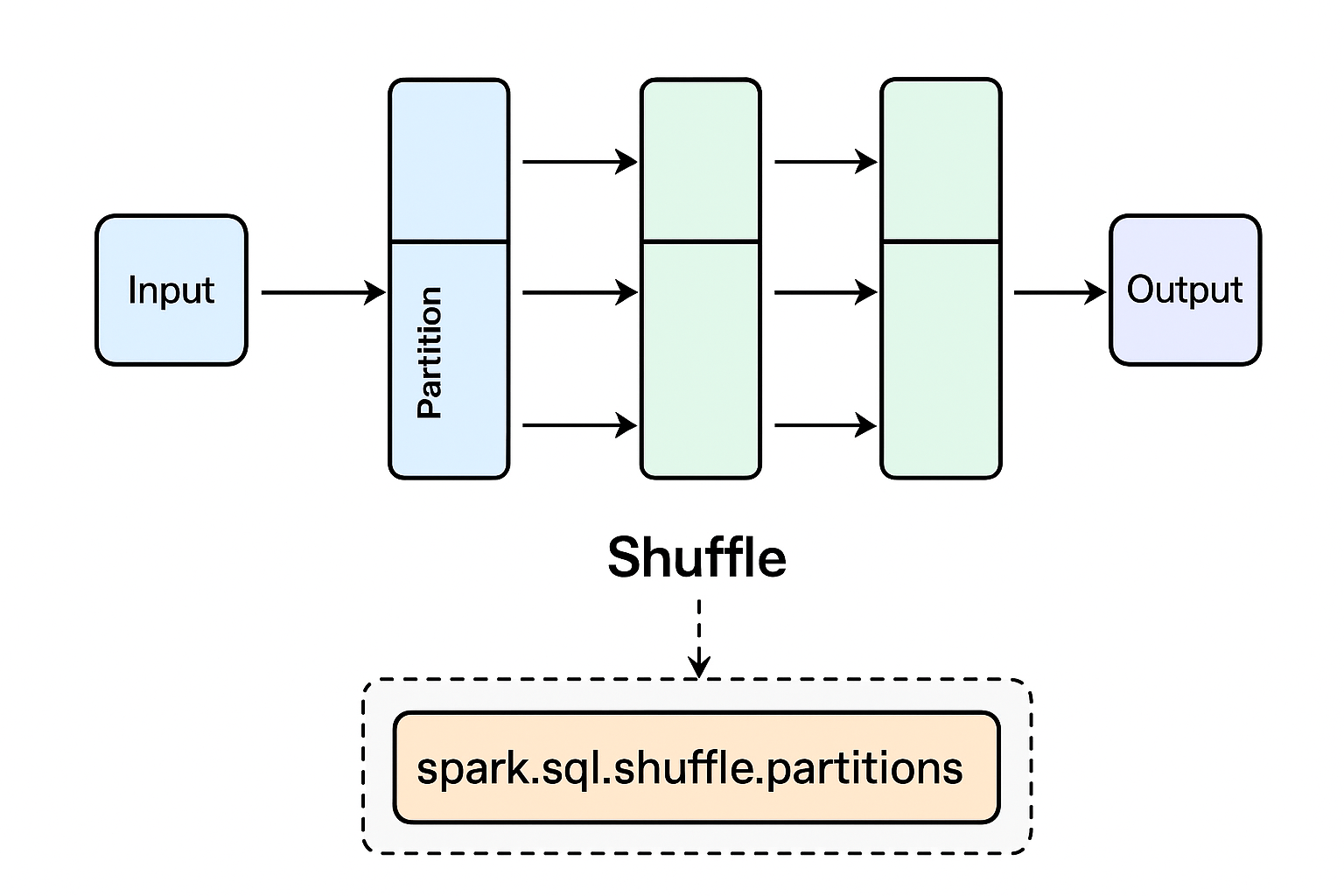
三、关键参数及含义
1. spark.sql.shuffle.partitions
-
作用:设置 Shuffle 输出分区数量,也就是 Stage 下游 Task 数。
-
生效阶段:物理计划生成阶段。
-
特点:静态配置,决定初始 Task 数和文件数。
-
问题:分区数过多会导致每个 Task 数据量变小,输出小文件过多。
2. spark.sql.adaptive.enabled 与 AQE
-
作用:开启自适应查询执行(Adaptive Query Execution, AQE)。
-
功能:
-
根据运行时统计动态优化 Shuffle 分区数。
-
调整 Join 策略(如小表广播)。
-
3. spark.sql.adaptive.coalescePartitions.enabled
-
作用:开启运行时 分区合并,减少小文件和 Task 调度开销。
-
逻辑:
-
初始分区数由
spark.sql.shuffle.partitions提供。 -
运行时根据每个分区实际数据量合并成合适大小分区。
-
4. 辅助参数
spark.sql.adaptive.coalescePartitions.minPartitionSize=64m # 合并后每个分区最小大小
spark.sql.adaptive.shuffle.targetPostShuffleInputSize=128m # 每个分区目标大小
-
Spark 会尝试让每个分区大小在 64MB~128MB 之间。
-
过小的分区会被合并,过大的分区可能会拆分。
四、参数之间的关系
| 参数 | 生效阶段 | 静态/动态 | 作用 | 关系 |
|---|---|---|---|---|
| spark.sql.shuffle.partitions | 物理计划生成 | 静态 | 初始 Shuffle 输出分区数 | AQE 的初始值 |
| spark.sql.adaptive.coalescePartitions.enabled | Shuffle 执行阶段 | 动态 | 根据实际数据量合并分区 | 可以修改初始 Task 数,减少小文件,不冲突 |
理解类比:
-
shuffle.partitions→ “计划派出 200 个工人执行任务” -
coalescePartitions→ “运行中发现数据少,让 200 个工人只干 50 个工人的活”
五、小文件问题来源
小文件问题主要来源于以下原因:
-
分区数过多
-
每个 Task 对应一个输出文件,分区越多,文件越多。
-
-
每个分区数据量过小
-
数据量小 → 输出文件小 → 文件数量多。
-
-
数据倾斜
-
某些分区数据几乎为空,仍生成文件。
-
核心结论:分区数和每个 Task 数据量直接决定 Shuffle 输出文件大小和数量。
六、调优策略
-
合理设置
spark.sql.shuffle.partitions-
根据总数据量和目标每个 Task 数据量计算:
shuffle.partitions = 数据总量 / 每个Task目标数据量 -
通常目标数据量为 128MB 左右。
-
-
开启 AQE 分区合并
spark.sql.adaptive.enabled=true spark.sql.adaptive.coalescePartitions.enabled=true spark.sql.adaptive.coalescePartitions.minPartitionSize=64m spark.sql.adaptive.shuffle.targetPostShuffleInputSize=128m-
初始 Task 数由
shuffle.partitions提供 -
实际运行时动态调整 Task 数和文件数
-
-
必要时手动调整
-
使用
coalesce(n)或repartition(n)控制输出文件数量。
-
-
避免无意义 Shuffle
-
尽量用
map-side combine、广播 Join 等减少 Shuffle。
-
七、总结
-
Shuffle 是 Spark 性能瓶颈,同时决定文件输出数量。
-
spark.sql.shuffle.partitions是初始上限,AQE 分区合并则是运行时下调。 -
合理调优可以减少小文件、降低调度开销,提高集群利用率。
-
AQE 的出现使 Spark 调优更智能,但理解其与 shuffle.partitions 的关系仍然至关重要。

















 2816
2816

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









