



在生成式AI爆发的浪潮中,模型训练的价值已得到广泛认可,但目前看来,真正决定AI商业价值的,是能否通过高效推理实现规模化、低成本的服务交付。Gartner预测,到2028年,随着市场的成熟,80%以上的数据中心工作负载加速器将专门部署用于推理,而不是训练用途。这一趋势凸显了推理框架在AI生态中的核心地位。
当前,主流大模型推理框架呈现多元化竞争格局,各有技术侧重与适用场景:NVIDIA推出的TensorRT-LLM凭借闭源全链路编译优化,成为低延迟场景的“性能天花板”,专为自家GPU深度定制;SGLang通过RadixAttention技术优化多轮对话吞吐量,结构化输出能力突出;Ollama以轻量化为核心,简化个人开发者的本地部署流程;XInference则专注大规模分布式部署与多模态任务集成。而vLLM作为开源领域的领军者,凭借突破性技术创新,成为企业级高并发场景的首选框架。
vLLM(Virtual Large Language Model)是由加州大学伯克利分校团队研发的大模型推理服务引擎,其核心优势源于两项革命性技术:PagedAttention分页注意力机制与Continuous Batching连续批处理。PagedAttention将注意力键值对(KV Cache)划分为固定大小的“页”,动态分配与复用显存空间,使显存利用率从传统框架的60%提升至95%以上;连续批处理技术则摒弃等待凑批模式,实时将新请求加入处理队列,确保GPU持续高负载运行。
此外,vLLM的开源属性与广泛兼容性进一步巩固了其行业地位。它基于PyTorch构建,支持Llama等主流模型架构,兼容GPTQ、AWQ等量化技术,可将模型体积压缩至原大小的1/4-1/2,同时适配NVIDIA、AMD GPU及Google TPU等多种硬件加速器。vLLM的成功不仅在于技术突破,更在于它为行业提供了一个开放、可扩展的推理标准,让不同规模的企业都能享受高性能AI服务。
红帽:vLLM生态的中坚力量
作为开源软件领域的领军企业,红帽自vLLM项目早期便深度参与其中,成为其最重要的商业贡献者之一。近日,我们有幸与红帽首席工程师、vLLM核心贡献者Michael Goin对话,揭开红帽在vLLM生态中的深层逻辑与具体实践。

众所周知,红帽致力于将优秀的开源技术转化为企业可用的稳定解决方案。在分布式推理领域,红帽牵头推动vLLM与Kubernetes的深度集成,为llm-d提供核心技术支撑。llm-d旨在构建Kubernetes原生的大规模分布式推理框架,将vLLM的单机高性能推理能力扩展至集群级别,通过AI感知网络路由、KV缓存卸载等创新功能,突破了单服务器的资源限制。
此外,红帽在vLLM生态中的另一重要贡献是推动硬件兼容性标准化与模型优化生态的完善。Michael Goin强调:“开源技术的生命力在于生态包容,我们致力于让vLLM实现‘任意模型、任意加速器、任意云’的部署愿景。”目前,vLLM已支持主流硬件加速器,企业可根据成本与需求灵活选择部署平台。
为了进一步降低企业使用门槛,红帽在Hugging Face构建了专门的优化模型仓库,提供Llama、Mistral、Qwen、Granite等主流模型的vLLM适配版本。这些模型经过红帽技术的稀疏化与量化优化,在准确率几乎无损的前提下,显存占用大幅降低。此外,红帽还为vLLM提供企业级技术支持与长期维护服务,确保开源技术在金融、政务等关键行业的稳定应用。
全栈布局的核心锚点:vLLM赋能红帽AI战略落地
vLLM不仅是红帽参与贡献的重点开源项目,更是其全栈AI战略的核心支柱。红帽以vLLM为推理核心,构建了涵盖底层操作系统、中间件、容器平台到AI应用的完整技术栈。Michael Goin指出:“红帽的AI战略并非孤立的产品堆砌,而是以vLLM为枢纽,打通硬件适配、模型优化、部署管理与应用集成的全流程,为企业提供一致的混合云AI解决方案。”
目前,vLLM已深度集成至红帽的三大核心AI产品:红帽AI推理服务器、红帽企业Linux AI(RHEL AI)与红帽OpenShift AI。
其中,红帽AI推理服务器作为独立容器化产品,提供经过强化的企业级vLLM发行版;在红帽企业Linux AI(RHEL AI)中,vLLM作为默认推理引擎,为模型开发、测试与部署提供统一基础平台;在红帽OpenShift AI这一MLOps平台中,vLLM与模型训练、生命周期管理、监控告警等功能深度融合,实现“训练-推理-部署-迭代”的闭环管理。
可以说,vLLM为红帽AI战略带来的核心价值,体现在企业AI部署的成本控制、效率提升与灵活性增强三个维度。在成本控制方面,vLLM的高显存利用率与红帽的模型压缩技术相结合,使企业运行相同模型的GPU大幅减少;在效率提升层面,vLLM的高性能推理能力使红帽客户的AI应用响应速度显著加快;在部署灵活性上,vLLM的开源属性与红帽的混合云技术相结合,使企业可在公有云、私有云、边缘节点等任意环境部署AI推理服务。无论是需要严格数据隔离的政务场景,还是要求低延迟的边缘计算场景,红帽都能通过vLLM提供一致的推理性能。这种灵活性让企业摆脱了云厂商与硬件供应商的双重束缚,能够根据业务需求自由选择部署架构,同时降低迁移成本。
与沐曦携手,开启vLLM软硬协同新篇章
作为GPU赛道的“当红炸子鸡”,沐曦(MetaX)正以技术攻坚与市场拓展双轮驱动的态势迅猛崛起。依托核心团队在芯片设计、架构研发领域十余年的深耕积淀,沐曦聚焦高性能通用GPU核心技术突破,破解了指令集兼容、算力优化等行业痛点。其首款自主研发的通用GPU产品一经推出,便凭借在浮点运算性能、功耗控制等关键指标上的亮眼表现,获得政企客户及合作伙伴的广泛认可,快速切入AI训练推理、数据中心等核心应用场景。
而在日前举行的2025红帽论坛上,红帽与沐曦联合发布MXAIE解决方案,通过vLLM推理引擎的深度优化,实现GPU与开源软件生态的无缝融合,为企业提供安全、高效、可扩展的AI基础设施,成就了vLLM生态“软硬协同”的典型案例。
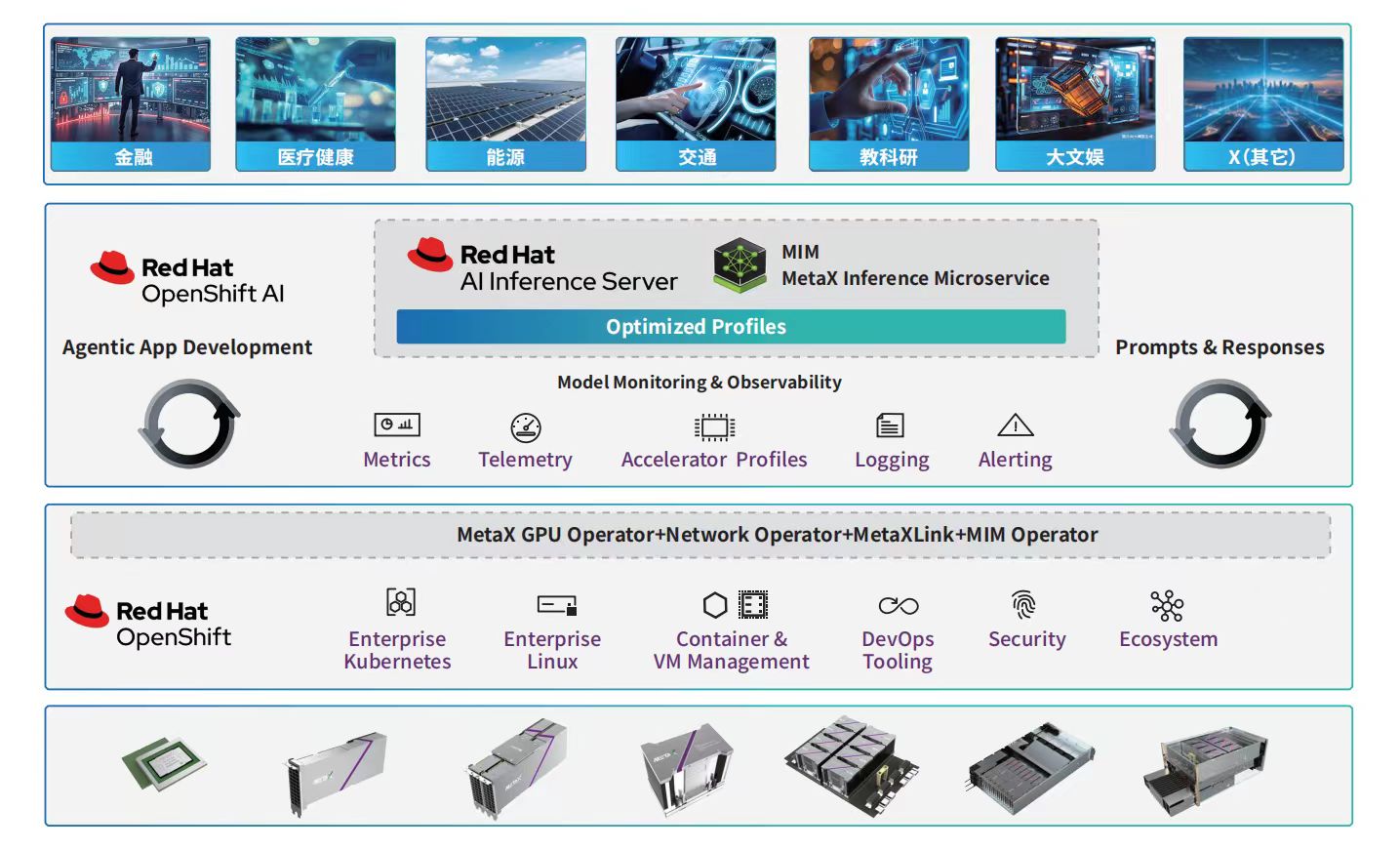
谈及合作缘起,Michael Goin表示:“红帽选择合作伙伴的核心标准是技术实力与生态互补性,沐曦在GPU领域的技术积累与红帽的开源生态优势形成了完美契合。”双方的合作始于2025年初,初期聚焦于vLLM与沐曦硬件的兼容性适配。红帽开放了vLLM的底层优化接口,提供算子优化指南与性能调优经验;沐曦则基于其GPU架构特性,为vLLM开发定制化内核,重点优化了注意力计算与张量运算等关键环节。
经过三个月的联合攻关,双方完成了vLLM与沐曦曦云C系列、曦思N系列产品的全面互兼容性测试。在兼容性测试通过后,双方将合作升级至解决方案整合与生态拓展层面,共同推出MXAIE一站式AI基础设施方案。该方案整合了沐曦的高性能GPU硬件、红帽OpenShift容器平台与红帽AI推理服务器(vLLM核心),实现从硬件加速到平台管理的闭环。MXAIE方案的核心是vLLM的跨硬件适配能力,通过统一的推理服务层屏蔽底层硬件差异,让企业无需修改应用代码即可获得高性能推理体验。
从伯克利分校的实验室项目到企业级推理的标准框架,vLLM的成长之路可谓是开源协作的典范。我们相信,未来,随着技术的持续迭代与生态的不断扩展,vLLM必将在AI产业化的浪潮中扮演更重要的角色。而红帽也将继续扛起vLLM大旗,深化全栈AI战略,推动开源推理技术在更多行业场景的落地。


















 4644
4644

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











