




一、背景
本文主要记录一下使用 LDMs 之前,学习 LDMs 的过程。
二、论文解读
Paper:[2112.10752] High-Resolution Image Synthesis with Latent Diffusion Models
1. 总体描述
LDMs 将传统 DMs 在高维图像像素空间(Pixel Space)上的 diffusion 操作转移到低维潜空间(Latent Space)进行,大大降低了训练和推理所需计算资源,生成的图像细节更丰富,更真实,且能用于生成高分辨率(百万级像素)图像;同时引入的条件控制机制 Conditioning Mechanisms 使模型能够用于多种条件图像生成任务,如图像超分、图像修复、语义合成(文生图、图生图,布局生图)。
后面这几位作者又提出了检索增强扩散模型(Retrieval Augmented Diffusion Models, RDMs)并将其用于 LDMs 的文生图任务中,大概作用就是进一步降低生成图像所需计算资源,提升生成图像的质量。
2. LDMs
2.1 主体框架
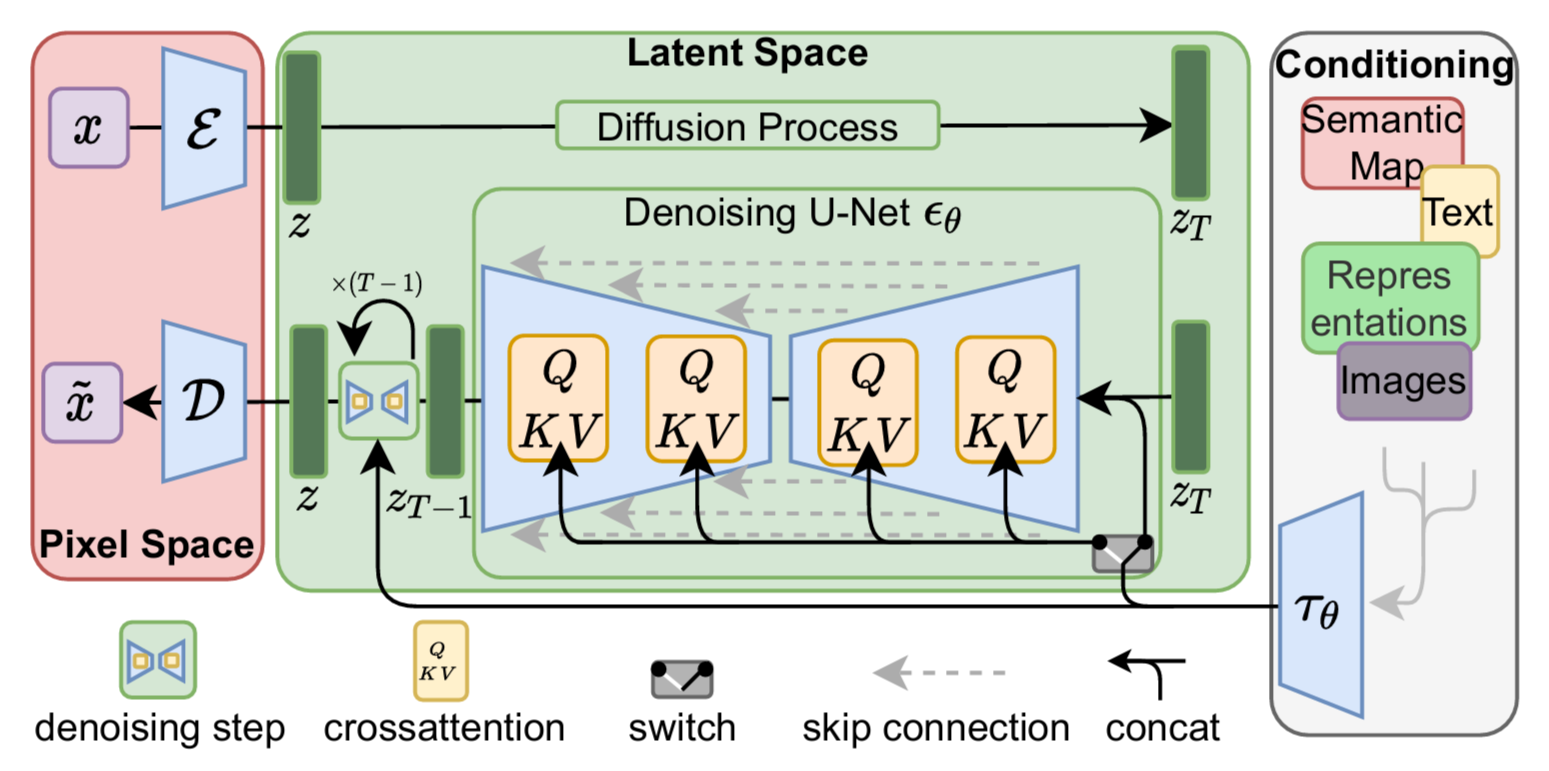
通过框架图可知,在 LDMs 之前需要先训练一个 Autoencoder,包含一个编码器 和一个解码器
,输入图像
经过编码器
得到其潜在空间的特征表示
,解码器
再将
从潜在空间重构回像素空间得到生成后的
,上述过程(对应框架图左部)可表示为:
Encode:
Decode:
其中降采样因子 ,且为 2 的幂次,即
。
正向扩散(加噪)过程和反向去噪(重构)过程均发生在潜在空间,重构过程中通过加入一个条件降噪自编码器 (UNet
cross attention,对应框架图中部)可以将输入条件
扩展到不同形态(对应框架图右部),比如文本、语义图、图像等,进而可以实现如文生图、布局生图、图生图等多种生成任务。
2.2 感知图像压缩(Perceptual Image Compression)
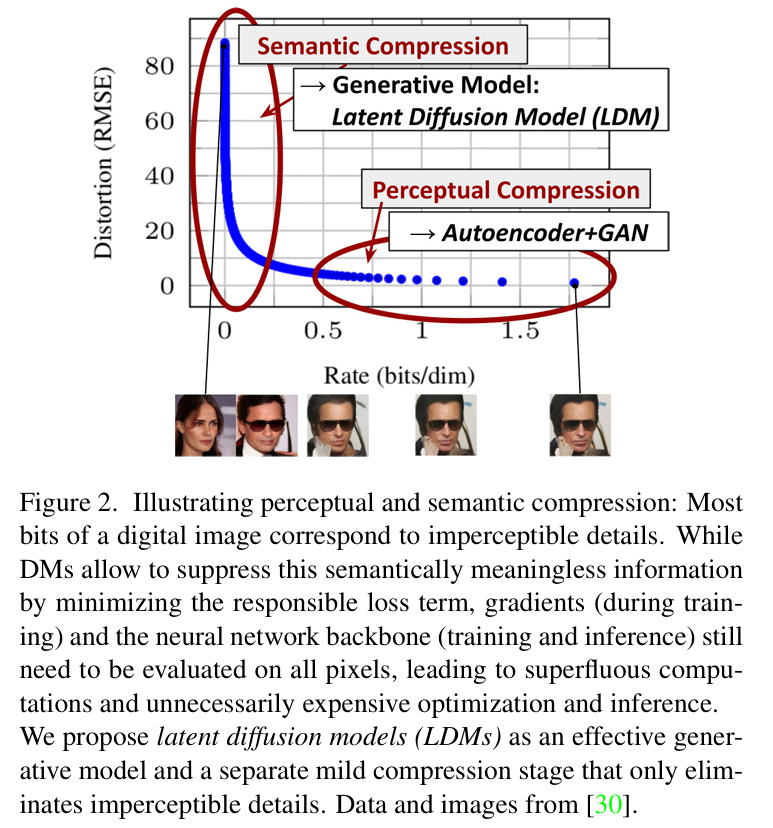
现有 DMs 的生成过程可以视为一个压缩比(感知有效 bit 与图像维度之比)和失真率的平衡问题(如上图所示),压缩比越低(高),说明图像中感知有效的 bit 越少(多),因而生成的图像失真程度越大(小)。其学习过程大致可分为两个阶段:感知压缩阶段和语义压缩阶段。在感知压缩阶段,模型会舍弃图像中的高频信息而只学习一些语义变化,在语义压缩阶段,生成模型会学习数据的语义和概念信息(高维抽象的信息)。
DMs 虽然可以忽略图像中一些在感知上无关紧要的信息,但模型的计算和优化过程仍然在像素空间中,这就导致如果合成一些高分辨率图像,空间维度就会非常高,在计算时间和计算资源上的花费会非常昂贵(heavy cost)。
于是
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









