 ResNeXt:ResNet的革新
ResNeXt:ResNet的革新







 ResNeXt是ResNet的升级版,融合了Inception和VGG/ResNet的优势,通过split-transform-merge策略提升模型性能。在不增加计算量的情况下,ResNeXt在ILSVRC2016图像分类中取得优异成绩,其结构清晰、可扩展性强。
ResNeXt是ResNet的升级版,融合了Inception和VGG/ResNet的优势,通过split-transform-merge策略提升模型性能。在不增加计算量的情况下,ResNeXt在ILSVRC2016图像分类中取得优异成绩,其结构清晰、可扩展性强。
论文名称:Aggregated Residual Transformations for Deep Neural Networks
作者:Saining Xie1 \ Ross Girshick \ Zhuowen Tu \ Kaiming He
论文地址:http://openaccess.thecvf.com/content_cvpr_2017/papers/Xie_Aggregated_Residual_Transformations_CVPR_2017_paper.pdf
发表年份:CVPR 2017

ResNeXt算是Resnet的V3版本(不明白这个名字的含义,觉得很别扭)。基于ResNeXt的模型ILSVRC2016的图像分类中获得亚军(冠军是中国的Trimps-Soushen)。但抛开高准确性,ResNeXt的结构性、可扩展性、易用性使得它仍然风靡视觉界。
1 动机
Inception构建网络时,独辟蹊径,使用split-transform-merge的方式构建block unit,然后堆叠这些block,取得了很好的效果,但是Inception里那些block unit中的卷积核的个数/尺寸等都是对ImageNet数据集量身定做的,如果换个数据集,那么如果要达到更好的效果需要手动调整这些参数,,,,,,,,,,,。
VGG和ResnetV1/2都采用堆叠相同拓扑结构的“block unit”的方式构建网络,也取得了很好的效果,而且这种情况下block unit中的超参数数量是极少的。
那么能不能取Inception和VGG/ResnetV1/2两家之长呢?
2 贡献
作者提出一种新的残差映射的单元结构,在不增加计算的情况下,进一步提升Resnet的性能!
3 方法
3.1 split-transform-merge思想
这种思想来自Inception。对于单个神经元的操作可以深入浅出的解释这种行为。

原输入xxx被“split”成x1,x2,x3,,,xDx_1,x_2,x_3,,,x_Dx1,x2,x3,,,xD,然后单独做“transform” yi=wi∗xiy_i=w_i*x_iyi=wi∗xi,最后“merge” y=∑(yi)y=\sum(y_i)y=∑(yi)。
现在把单个神经元换成单个block unit,就可以重新构建残差块。

变形

对于新的残差块的实现一共有3中方式,而且3中方式效果等效,但是ccc的速度要快一些,所以应该使用ccc。
3.2 模板思想
这种思想来着VGG和ResnetV1/2,每个block都是来自同一个拓扑结构模板,其中的微小区别也可以用一两个参数解决,这样可以使得网络设计的灵活性和泛化性极高,即即使需要对于某个新的数据集更改网络结构也变得十分简单。
把上面的新的残差块模板化,参数就是分成的份数(论文中称为 cardinality)和每一份的width(论文中把width定义为channel的个数)。
3.3 网络结构
_for ImageNet

3.4 实现细节
- 使用ccc方式构建残差块
- 其余超参数、优化器及其参数等 与ResnetV1相同
4 实验
4.1 验证ResNeXt的优越性
_注:下面结果中的(m x nd)中,m表示cardinality的个数,n表示每个cardinality的width
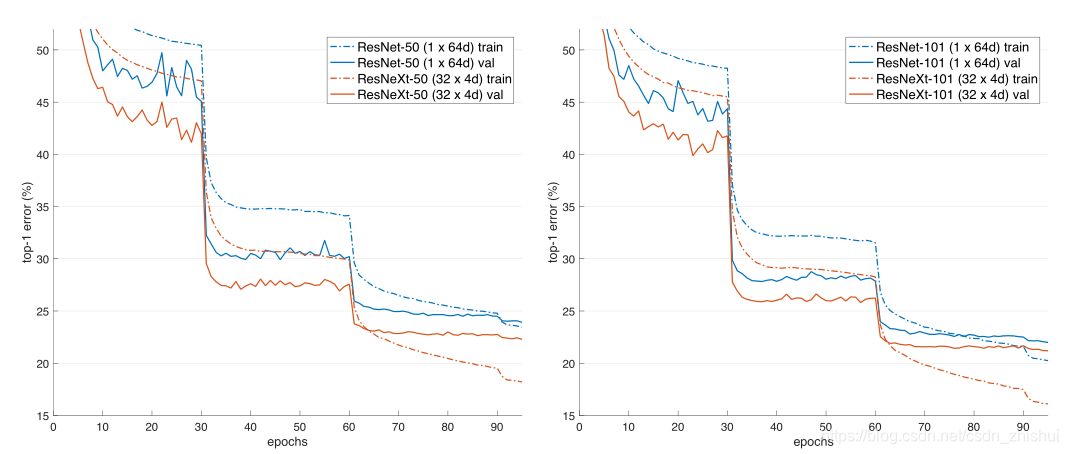
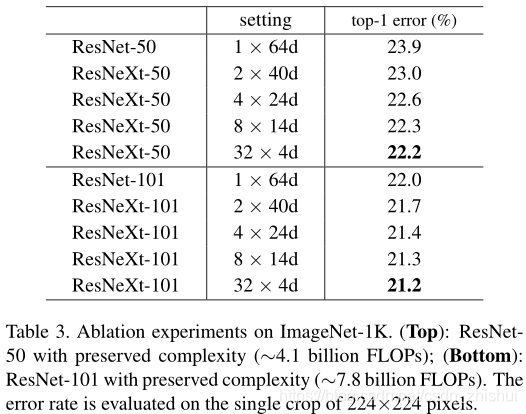
4.2 ResNeXt用于目标检测
同ResnetV1中一致,仍然使用Faster RCNN框架,这次使用ResNeXt作为特征提取器。

5 思考
1.文中并没有对新的残差块设计为什么有效给出解释。
本人对这种设计的理解是:
先看单个神经元的操作,把xxx“split”之后在做“transform”时wiw_iwi仅仅对xix_ixi负责,那么训练出来的WWW应该很纯净。
再看卷积实现,假设X:(C,H,W)={X1,X2,...,XC}X:(C,H,W)=\{X_1,X_2,...,X_C\}X:(C,H,W)={X1,X2,...,XC},如果对它卷积,那么卷积核Filter:(F,C,H,W)={w1,w2,...,wF}Filter:(F,C,H,W)=\{w_1,w_2,...,w_F\}Filter:(F,C,H,W)={w1,w2,...,wF}在对XXX卷积时,直接对XiX_iXi负责的部分广泛分布在w1,w2,...,wCw_1,w_2,...,w_Cw1,w2,...,wC中,可以记为wji,1≤j≤Cw_{ji},1 \leq j\leq Cwji,1≤j≤C,那么训练出来的w1,w2,...,wCw_1,w_2,...,w_Cw1,w2,...,wC每一个都在对整个XXX负责。即对于XiX_iXi,FilterFilterFilter中并不存在某个确定的单独对它负责的卷积子核wjw_jwj,这样训练出的FilterFilterFilter认为是不纯净的。
而如果把XXX“split”成X1,X2,...,XKX_1,X_2,...,X_KX1,X2,...,XK,然后分别让w1(C/K,H,W),w2(C/K,H,W),...wk(C/K,H,W)w_1(C/K,H,W),w_2(C/K,H,W),...w_k(C/K,H,W)w1(C/K,H,W),w2(C/K,H,W),...wk(C/K,H,W)去卷积,这样就有wjw_jwj单独对XiX_iXi负责,这样训练出来的wkw_kwk相较于一开始的wjw_jwj应该要纯净,并且当K=CK=CK=C时,就把XXX全部“split”,这个时候的wkw_kwk应该最纯净,效果最好。
并且在计算量大致相同的情况下,“split-transform-merge”的方式下,对XiX_iXi负责的参数数目会增加。

















 1089
1089

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









